手把手带你可视化分析NBA首轮球队表现及火勇对决前瞻!
NBA激战正酣,首轮除掘金和马刺的较量还没有结束外,其余对决都已经结束,本文将手把手带你可视化分析下各球队的首轮表现,同时将对次轮最受瞩目的火勇大战进行一个简单的前瞻分析!
通过本文,你将学会python中使用matplotlib库绘制柱状图、散点图、雷达图的相关知识!咱们开始吧!
1、数据获取及准备
我们首先获取各球队季后赛首轮的数据,网址是:https://www.basketball-reference.com/playoffs/NBA_2019.html。首先选择Playoffs:

然后,下拉到球队技术统计这里,导出csv,如果无法直接倒出,可以复制到txt文件里面(我就是这么干的):
然后,我们再把对手表现的数据导出,这样基础数据就准备好了:

好了,我们使用代码将数据进行读取,首先导入所需要的库:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
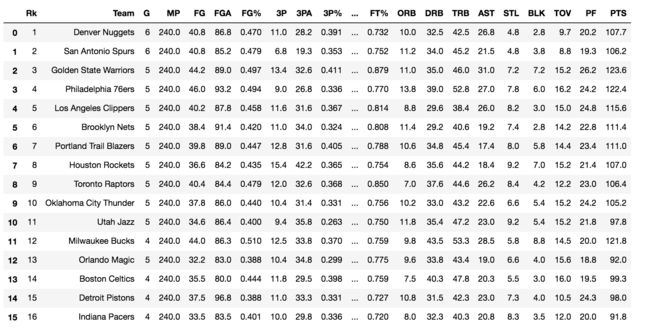
将数据使用pandas进行读取,看看数据如何:
team_stats_df = pd.read_csv('data/nba1.txt',sep=',')
team_stats_df
同样,将对手表现的数据读入,但是这里列名需要修改一下:
team_opp_stats_df = pd.read_csv('data/nba2.txt',sep=',')
team_opp_stats_df.columns = ['Rk','Team','G'] + ['opp' + x for x in team_opp_stats_df.columns[3:]]
将两个表按照队名进行merge,这样oppPTS列,可以表示场均失分,这也是我们在对手表现数据里面主要关注的列:
mergedf = pd.merge(team_stats_df,team_opp_stats_df,on=['Team'])
2、柱状图分析球队场均得失分
绘制柱状图,需要使用的是plt.bar方法,其主要输入的有两个参数,一个是x轴的值,一个是高度,比如,我们绘制一下各球队首轮平均得分的柱状图:
pts = np.array(mergedf[['PTS','oppPTS']].values.tolist())
index = np.arange(pts.shape[0])
plt.bar(index,pts[:,1])
plt.show()
结果如下:
上面的图还是有几个问题的,首先,我们不希望X显示的是数值,我们希望展示各个球队名称的缩写,同时刻度可以不从0开始,这样看上去区分度不是十分的明显。
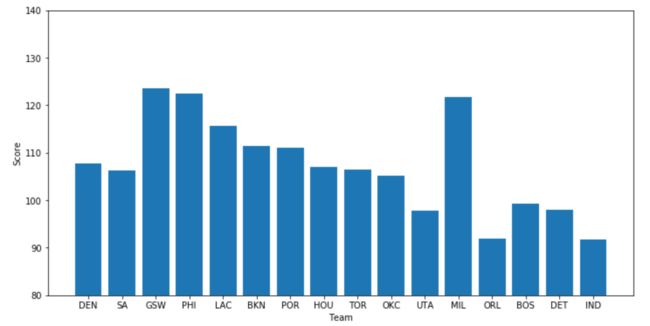
针对第一个问题,我们需要首先按顺序得到各个球队名称的缩写:
team_name = ['DEN','SA','GSW','PHI','LAC','BKN','POR','HOU','TOR','OKC','UTA','MIL','ORL','BOS','DET','IND']
随后,将x轴的刻度设置为相应的队名:
plt.xticks(index,team_name) # 设置x轴的刻度
针对第二个问题,我们需要限定y轴的范围,使用ylim方法:
plt.ylim(80,140) # y轴的范围
这样,我们得到了下面的图片:
上面这部分的完整代码如下:
team_name = ['DEN','SA','GSW','PHI','LAC','BKN','POR','HOU','TOR','OKC','UTA','MIL','ORL','BOS','DET','IND']
plt.ylabel('Score') # 设置y轴的label
plt.xlabel('Team') # 设置x轴的label
plt.xticks(index,team_name) # 设置x轴的刻度
plt.yticks(np.arange(80,141,10)) #y轴的刻度
plt.ylim(80,140) # y轴的范围
plt.bar(index,pts[:,0]) # 绘制直方图
plt.rcParams['figure.figsize'] = (12.0, 6.0) # 修改图片大小
plt.show()
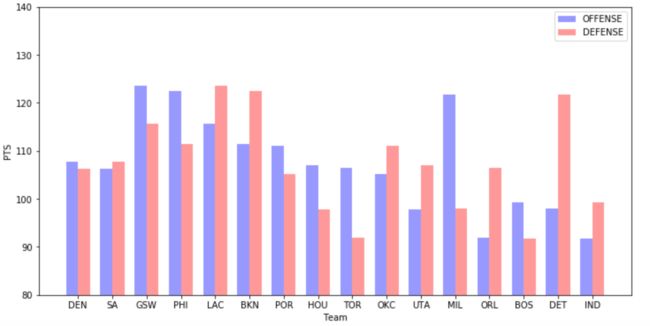
此时,我们可能想要将球队的得失分表示出来,代码如下:
fig, ax = plt.subplots()
bar_width = 0.35
opacity = 0.4
rects1 = ax.bar(index, pts[:,0], bar_width,
alpha=opacity, color='b',
label='OFFENSE')
rects2 = ax.bar(index + bar_width, pts[:,1], bar_width,
alpha=opacity, color='r',
label='DEFENSE')
ax.set_xlabel('Team')
ax.set_ylabel('PTS')
ax.set_xticks(index + bar_width / 2)
ax.set_xticklabels(team_name)
ax.set_yticks(np.arange(80,141,10)) #y轴的刻度
ax.set_ylim(80,140) # y轴的范围
ax.legend()
plt.show()
绘制的结果如下:
3、散点图分析球队场均得失分
这一部分,我们使用散点图来分析球队场均得失分,使用plt.scatter函数,分别指定各个点的x和y值:
plt.scatter(pts[:,0], pts[:,1])
plt.xlabel('Offense PTS') # 设置x轴的label
plt.ylabel('Defense PTS') # 设置y轴的label
plt.show()
得到的效果如下:

简单的绘制散点图,什么都看不出来,此时,我们提出两个需求,首先,能不能将各个球队的简称放到各个点的旁边,这样我们就能清楚知道哪个点代表哪个球队。其次,能不能在图中添加两条直线,分别表示球队得分和失分的平均值?我们一个一个来解决。
首先,将球队标记加入到图中,我们使用plt.annotate函数,该函数需要传入三个参数,依次是注释文本内容,被注释的坐标点,注释文字的坐标位置:
plt.scatter(pts[:,0], pts[:,1])
plt.xlabel('Offense PTS') # 设置x轴的label
plt.ylabel('Defense PTS') # 设置y轴的label
for i in range(len(pts[:,0])):
plt.annotate(team_name[i], xy = (pts[i,0], pts[i,1]), xytext = (pts[i,0]+0.1, pts[i,1]+0.1)) # 这里xy是需要标记
plt.show()
此时的效果就能满足我们的第一个需求:

对于第二个需求,我们使用plt.vlines和plt.hlines方法,对于plt.vlines方法,它是在图中绘制一条竖直线,因此需要指定x轴的坐标,同时需要指定y轴的起始坐标和结束坐标,对于plt.hlines方法,它是在图中绘制一条水平线,因此需要指定y轴的坐标,同时需要指定x轴的起始坐标和结束坐标:
offense_mean = np.mean(pts[:,0])
defense_mean = np.mean(pts[:,1])
print(offense_mean,defense_mean)
plt.scatter(pts[:,0], pts[:,1])
plt.vlines(np.mean(pts[:,0]), np.min(pts[:,1])-5,np.max(pts[:,1])+5,colors = "r", linestyles = "dashed")
plt.hlines(np.mean(pts[:,1]), np.min(pts[:,0])-5,np.max(pts[:,0])+5,colors = "r", linestyles = "dashed")
plt.ylim(np.min(pts[:,1])-5,np.max(pts[:,1])+5) # y轴的范围
plt.xlim(np.min(pts[:,0])-5,np.max(pts[:,0])+5) # x轴的范围
plt.xlabel('Offense PTS') # 设置x轴的label
plt.ylabel('Defense PTS') # 设置y轴的label
for i in range(len(pts[:,0])):
plt.annotate(team_name[i], xy = (pts[i,0], pts[i,1]), xytext = (pts[i,0]+0.1, pts[i,1]+0.1)) # 这里xy是需要标记
plt.show()
结果如下:

基于上面的散点图,我们就能很快将十六支球队分为四个象限。
1)第一象限:进攻好,防守差,包含的球队有金州勇士、费城76人、洛杉矶快船、布鲁克林篮网
2)第二象限:进攻差,防守差,包含的球队有底特律活塞、俄克拉荷马雷霆、圣安东尼奥马刺
3)第三象限:进攻差,防守好,包含的球队有休斯顿火箭、奥兰多魔术、印第安纳步行者、犹他爵士、多伦多猛龙、波士顿凯尔特人
4)第四象限:进攻好,防守好,包含的球队有密尔沃基雄鹿、波特兰开拓者、丹佛掘金
哈哈,是不是跟你想象的不太一样,比如火箭怎么能说是进攻差的球队呢!因为他们的对手爵士是全联盟常规赛防守第一的球队,这种因素我们是无法通过这种图分析出来的。也就是说,数据不能表明一切!
4、基于雷达图的火勇对决前瞻
勇士在今天的比赛中,凭借杜兰特的神奇表现,击败快船与火箭会师西部半决赛,这也是半决赛对决中最受人瞩目的。那么,我们通过雷达图来分析下两队在季后赛首轮的表现吧。这里要说明的是,我们的数据是在勇船第六场之前获取的,因此只有勇士五场的数据。
我们先来看看两队的基础数据,我们挑选了场均得分,场均失分、命中率、三分命中率、篮板、助攻、抢断、盖帽、失误等九项数据:
two_team_stats = mergedf[(mergedf['Team']=='Houston Rockets') | (mergedf['Team']=='Golden State Warriors')]
hou_and_gsw_df = two_team_stats[['FG%','3P%','TRB','AST','STL','BLK','PTS','oppPTS','TOV']]
print(hou_and_gsw_df)
结果如下,其中2代表勇士,7代表火箭:

接下来,我们相通过雷达图来对比一下二者的这九项数据,matplotlib里面的雷达图貌似必须是统一刻度的,至少我目前还没有找到如何设置为不同刻度。因此,我们首先将二者的数据,用统一的标准,转换到0-1区间内:
hou_and_gsw_data[:,0] = hou_and_gsw_data[:,0] / 0.55
hou_and_gsw_data[:,1] = hou_and_gsw_data[:,1] / 0.55
hou_and_gsw_data[:,2] = hou_and_gsw_data[:,2] / 55
hou_and_gsw_data[:,3] = hou_and_gsw_data[:,3] / 40
hou_and_gsw_data[:,4] = hou_and_gsw_data[:,4] / 12
hou_and_gsw_data[:,5] = hou_and_gsw_data[:,5] / 12
hou_and_gsw_data[:,6] = hou_and_gsw_data[:,6] / 130
hou_and_gsw_data[:,7] = hou_and_gsw_data[:,7] / 130
hou_and_gsw_data[:,8] = hou_and_gsw_data[:,8] / 20
绘制雷达图,使用的是极坐标系,因此,我们需要设置一下:
fig=plt.figure(figsize=(14,8))
ax1=fig.add_subplot(1,1,1,polar=True) #设置第一个坐标轴为极坐标体系
随后,我们获取勇士和火箭的数据,并取得对应的数据标签:
gsw=hou_and_gsw_data[0,:] #提取GSW的信息
hou=hou_and_gsw_data[1,:] #提取HOU的信息
label=np.array([j for j in hou_and_gsw_df.columns]) #提取标签
随后,我们基于label的数量,对整圆进行切分,在切分的同时,我们需要加入切分后的第一个元素,以形成一个闭环:
angle = np.linspace(0, 2*np.pi, len(gsw), endpoint=False) #有几个label,就把整圆360°分成几份
angles = np.concatenate((angle, [angle[0]])) #增加第一个angle到所有angle里,以实现闭合
gsw = np.concatenate((gsw, [gsw[0]])) #增加gsw的第一项数据,以实现闭合
hou = np.concatenate((hou, [hou[0]])) #增加hou的第一项数据,以实现闭合
随后,便可以绘制我们的雷达图:
ax1.set_thetagrids(angles*180/np.pi, label, fontproperties="Microsoft Yahei") #设置网格标签
ax1.plot(angles,gsw,"o-",label='GSW')
ax1.plot(angles,hou,"o-",label='HOU')
ax1.set_theta_zero_location('NW') #设置极坐标0°位置
ax1.set_rlim(0,1) #设置显示的极径范围
ax1.fill(angles,gsw,facecolor='g', alpha=0.2) #填充颜色
ax1.set_title("HOU VS GSW",fontproperties="SimHei",fontsize=16) #设置标题
plt.legend(loc = 'best')
plt.show()
结果如下:

从雷达图来看,火箭除了在抢断和失分上占据一定优势外,其他各项数据均落后于勇士。不过还是刚才的那句话,数据不能体现一切,希望火勇双方能给我们带来一场精彩绝伦的较量。