Hive的DDL数据定义
创建数据库
- 创建一个数据库,数据库在HDFS上的默认存储路径是/user/hive/warehouse/*.db
hive (default)> create database db_hive; - 避免要创建的数据库已经存在错误,增加if not exists判断。(标准写法)
hive> create database db_hive;
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. Database db_hive already exi
sts
hive (default)> create database if not exists db_hive;
- 创建一个数据库,指定数据库在HDFS上存放的位置
hive (default)> create database db_hive2 location '/db_hive2.db';
修改数据库
用户可以使用ALTER DATABASE命令为某个数据库的DBPROPERTIES设置键-值对属性值,来描述这个数据库的属性信息。数据库的其他元数据信息都是不可更改的,包括数据库名和数据库所在的目录位置。
alter database db_hive set dbproperties("mynick"="lzl"); 在mysql中查看修改结果 hive> desc database extended db_hive; // 注意要添加 extended 关键字,意思是查看数据库额外的信息,这个信息就包括我们自己定义的
|

查询数据库
显示数据库
- 显示数据库 hive> show databases;
- 过滤显示查询的数据库 hive> show databases like 'db_hive*';
查看数据库详情
- 显示数据库信息 hive> desc database db_hive;
- 显示数据库详细信息,extended hive> desc database extended db_hive;
使用数据库
hive (default)> use db_hive;
删除数据库
- 删除空数据库
hive>drop database db_hive2; - 如果删除的数据库不存在,最好采用 if exists判断数据库是否存在
hive> drop database if exists db_hive2; - 如果数据库不为空,可以采用cascade命令,强制删除
hive> drop database db_hive cascade; // cascade 强制删除关键字
创建表
建表语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS]table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [ROW FORMAT row_format] [STORED AS file_format] [LOCATIONhdfs_path] |
字段解释说明
|
默认创建的表都是所谓的管理表,有时也被称为内部表。因为这种表,Hive会(或多或少地)控制着数据的生命周期。Hive默认情况下会将这些表的数据存储在由配置项hive.metastore.warehouse.dir(例如,/user/hive/warehouse)所定义的目录的子目录下。 当我们删除一个管理表时,Hive也会删除这个表中数据。管理表不适合和其他工具共享数据。
案例实操
- 普通创建表
create table if not exists student2(
id int, name string
)
row format delimited fields terminated by '\t'
stored as textfile
location '/user/hive/warehouse/student2'; - 根据查询结果创建表(查询的结果会添加到新创建的表中)
create table if not exists student3 as select id, name from student; - 根据已经存在的表结构创建表
create table if not exists student4 like student; - 查询表的类型
hive (default)> desc formatted student2;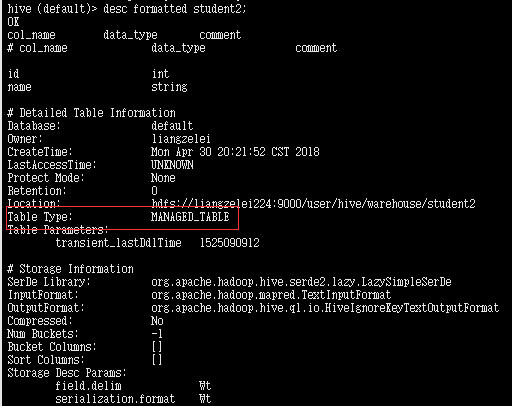
外部表
因为表是外部表,所有Hive并非认为其完全拥有这份数据。删除该表并不会删除掉这份数据,不过描述表的元数据信息会被删除掉。
管理表和外部表的使用场景:每天将收集到的网站日志定期流入HDFS文本文件。在外部表(原始日志表)的基础上做大量的统计分析,用到的中间表、结果表使用内部表存储,数据通过SELECT+INSERT进入内部表。
案例实操
分别创建部门和员工外部表,并向表中导入数据。
- 原始数据
emp.txt和dept.txt - 建表语句
create external table if not exists default.dept(
deptno int,
dname string,
loc int
)
row format delimited fields terminated by '\t';create external table if not exists default.emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by '\t'; - 查看创建的表
hive (default)> show tables; - 向外部表中导入数据
/*注意/opt/module/datas/dept.txt根据自己的路径进行修改*/
hive (default)> load data local inpath '/opt/module/datas/dept.txt' into table default.dept;
hive (default)> load data local inpath '/opt/module/datas/emp.txt' into table default.emp;
查询一下
hive (default)> select * from emp;
hive (default)> select * from dept; - 查看表格式化数据
hive (default)> desc formatted dept; 后会看到表类型为如下:
Table Type: EXTERNAL_TABLE
分区表
分区表实际上就是对应一个HDFS文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过WHERE子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。分区表基本操作
- 引入分区表(需要根据日期对日志进行管理)
- 创建分区表语法
hive (default)> create table dept_partition(
deptno int, dname string, loc string
)
partitioned by (month string)
row format delimited fields terminated by '\t'; - 加载数据到分区表中
hive (default)> load data local inpath '/opt/module/datas/dept.txt' into table default.dept_partition partition(month='201804');
hive (default)> load data local inpath '/opt/module/datas/dept.txt' into table default.dept_partition partition(month='201805');
hive (default)> load data local inpath '/opt/module/datas/dept.txt' into table default.dept_partition partition(month='201806'); - 查询分区表中数据
单分区查询 hive (default)> select * from dept_partition where month='201805';
多分区联合查询
hive (default)> select * from dept_partition where month='201805'
union
select * from dept_partition where month='201804'
union
select * from dept_partition where month='201806'; - 增加分区
创建单个分区
hive (default)> alter table dept_partition add partition(month='201807') ;
同时创建多个分区
hive (default)> alter table dept_partition add partition(month='201808') partition(month='201809'); - 删除分区
删除单个分区
hive (default)> alter table dept_partition drop partition (month='201804');
同时删除多个分区
hive (default)> alter table dept_partition drop partition (month='201805'), partition (month='201806'); - 查看分区表有多少分区
hive>show partitions dept_partition; - 查看分区表结构
hive>desc formatted dept_partition;
- 创建多级分区表
hive (default)> create table dept_partition2(
deptno int, dname string, loc string
)
partitioned by (month string, day string)
row format delimited fields terminated by '\t'; - 正常的加载数据
加载数据到二级分区表中
hive (default)> load data local inpath '/opt/module/datas/dept.txt' into table default.dept_partition2 partition(month='201805', day='13');
查询分区数据
hive (default)> select * from dept_partition2 where month='201805' and day='13'; - 把数据直接上传到分区目录上,让分区表和数据产生关联的三种方式
方式一:上传数据后修复
方式二:上传数据后添加分区上传数据 hive (default)> dfs -mkdir -p /user/hive/warehouse/dept_partition2/month=201805/day=1;
hive (default)> dfs -put /opt/module/datas/dept.txt /user/hive/warehouse/dept_partition2/month=201805/day=1;执行修复命令 hive>msck repair table dept_partition2; 查询数据 hive (default)> select * from dept_partition2 where month='201805' and day='1';
方式三:上传数据后load数据到分区上传数据 hive (default)> dfs -mkdir -p /user/hive/warehouse/dept_partition2/month=201805/day=1;
hive (default)> dfs -put /opt/module/datas/dept.txt /user/hive/warehouse/dept_partition2/month=201805/day=1;执行添加分区 hive (default)> alter table dept_partition2 add partition(month='201805', day='1'); 查询数据 hive (default)> select * from dept_partition2 where month='201805' and day='1';
创建目录 hive (default)> dfs -mkdir -p /user/hive/warehouse/dept_partition2/month=201805/day=1; 上传数据 hive (default)> load data local inpath '/opt/module/datas/dept.txt' into table dept_partition2
partition(month='201805',day='1');查询数据 hive (default)> select * from dept_partition2 where month='201805' and day='1';
修改表
- 重命名表 ALTER TABLE table_name RENAME TO new_table_name
实操案例: hive (default)> alter table dept_partition2 rename to dept_partition3; - 增加、修改和删除表分区
见分区表基本操作 - 增加/修改/替换列信息
更新列
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name]
增加和替换列
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)
注:ADD是代表新增一字段,字段位置在所有列后面(partition列前),REPLACE则是表示替换表中所有字段。
实操案例
(1)查询表结构
hive>desc dept_partition;
(2)添加列
hive (default)> alter table dept_partition add columns(deptdesc string);
(3)更新列
hive (default)> alter table dept_partition change column deptdesc desc int;
(4)替换列
hive (default)> alter table dept_partition replace columns(deptno string, dname string, loc string);
删除表
hive (default)> drop table dept_partition; // 可以用于删除空表
hive (default)> drop table dept_partition cascade; // 可以用于删除有数据的表