- Java 大视界 -- Java 大数据中的自然语言生成技术与实践(63)
青云交
大数据新视界Java大视界大数据自然语言生成基于规则模型基于统计模型基于深度学习模型新闻写作智能客服
亲爱的朋友们,热烈欢迎来到青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而我的博客正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也期待你毫无保留地分享独特见解,愿我们于此携手成长,共赴新程!一、欢迎加入【福利社群】点击快速加入:青云交灵犀技韵交响盛汇福利社群点击快速加入2:2024CSDN博客之星创作交流营(NEW)二、本博客的精华专栏:大数据新视
- 动态规划详解-最小路径和问题【python】
数据分析螺丝钉
LeetCode刷题与模拟面试动态规划算法leetcodepython数据结构
作者介绍:10年大厂数据\经营分析经验,现任大厂数据部门负责人。会一些的技术:数据分析、算法、SQL、大数据相关、python欢迎加入社区:码上找工作作者专栏每日更新:LeetCode解锁1000题:打怪升级之旅python数据分析可视化:企业实战案例备注说明:方便大家阅读,统一使用python,带必要注释,公众号数据分析螺丝钉一起打怪升级1.问题介绍和应用场景最小路径和问题是一个常见的动态规划问
- Java 大视界 -- Java 大数据中的知识图谱构建与应用(62)
青云交
大数据新视界Java大视界大数据知识图谱信息抽取知识融合智能搜索智能推荐风险评估
亲爱的朋友们,热烈欢迎来到青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而我的博客正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也期待你毫无保留地分享独特见解,愿我们于此携手成长,共赴新程!一、欢迎加入【福利社群】点击快速加入:青云交灵犀技韵交响盛汇福利社群点击快速加入2:2024CSDN博客之星创作交流营(NEW)二、本博客的精华专栏:大数据新视
- [Python从零到壹] 七十七.图像识别及经典案例篇之目标检测入门普及和ImageAI对象检测详解
Eastmount
Python从零到壹python目标检测ImageAI图像是被基础系列
欢迎大家来到“Python从零到壹”,在这里我将分享约200篇Python系列文章,带大家一起去学习和玩耍,看看Python这个有趣的世界。所有文章都将结合案例、代码和作者的经验讲解,真心想把自己近十年的编程经验分享给大家,希望对您有所帮助,文章中不足之处也请海涵。Python系列整体框架包括基础语法10篇、网络爬虫30篇、可视化分析10篇、机器学习20篇、大数据分析20篇、图像识别30篇、人工智
- 用 Java 的思路快速学习 Scala
进朱者赤
其他大数据scalaScala
引言Scala是一种结合了面向对象和函数式编程的现代编程语言,广泛应用于大数据处理框架如ApacheSpark和ApacheFlink。对于熟悉Java的开发者来说,Scala的学习曲线相对平缓。本文将通过类比Java中的概念,帮助Java开发者快速上手Scala。1.基本语法1.1.数据类型以下是Scala和Java数据类型的汇总表格:Scala数据类型Java数据类型说明Intint32位整数
- python鸢尾花数据集knn_【python+机器学习1】python 实现 KNN
weixin_39629269
python鸢尾花数据集knn
欢迎关注哈希大数据微信公众号【哈希大数据】1KNN算法基本介绍K-NearestNeighbor(k最邻近分类算法),简称KNN,是最简单的一种有监督的机器学习算法。也是一种懒惰学习算法,即开始训练仅仅是保存所有样本集的信息,直到测试样本到达才开始进行分类决策。KNN算法的核心思想:要想确定测试样本属于哪一类,就先寻找所有训练样本中与该测试样本“距离”最近的前K个样本,然后判断这K个样本中大部分所
- 函数计算 FC 诚邀您参加【Cloud Up 挑战赛】赢取丰厚奖品!
github
亲爱的开发者们,函数计算FC团队向你们发出诚挚邀请,加入我们即将举办的【CloudUp挑战赛】,这不仅是一场技术盛宴,更是一次展示才华与创新的机会。从互联网应用开发到AI、大数据,再到现代化应用开发,本次赛事覆盖了所有你渴望掌握的技能点,旨在为你提供一个实践平台,将理论知识转化为解决实际业务问题的能力。挑战赛为期三周,活动时间为2024年11月25日至12月13日,立即参与:https://dev
- 未来商贸物流:人工智能与大数据的深度融合
呆码科技
临沂软件开发软件开发商贸物流科技人工智能
未来商贸物流:人工智能与大数据的深度融合在当今数字化浪潮汹涌澎湃的时代,商贸物流行业正站在变革的十字路口,而人工智能与大数据宛如一对闪耀的双子星,为其照亮前行的道路,深度融合之下,一个全新的未来画卷正徐徐展开。智能预测需求:精准把握市场脉搏传统的商贸物流往往依赖过往经验和粗略的市场调研来预估货物需求,这就如同在迷雾中摸索,充满不确定性。而如今,借助大数据的海量存储与超强分析能力,以及人工智能的深度
- 【大数据之路11】多范式编程语言 Scala
程序员老五
大数据scala开发语言
多范式编程语言Scala1.Scala概述1.Scala介绍2.学习Scala的必要性1.基于编程语⾔⾃身2.基于活跃度2.Scala基础语法1.HelloScala2.变量定义1.变量与常量2.Scala自动类型识别3.lazy懒加载3.数据类型1.相关概述1.Scala数据类型列表2.测试代码3.Scala数据类型结构图2.Scala基本类型操作3.编码规范4.流程控制1.if2.块表达式3.
- 2024年大数据最全数据仓库|数据库面试题总结_面试题 数据仓库
2301_82243558
程序员大数据数据仓库数据库
这里值得注意的是不要想着为每个字段建立索引,因为优先使用索引的优势就在于其体积小。索引有哪几种类型?主键索引:数据列不允许重复,不允许为NULL,一个表只能有一个主键。唯一索引:数据列不允许重复,允许为NULL值,一个表允许多个列创建唯一索引。可以通过ALTERTABLEtable_nameADDUNIQUE(column);创建唯一索引可以通过ALTERTABLEtable_nameADDUNI
- AI Agent:一场智能革命的开始
机器人openai区块链
在当今科技日新月异的时代,AI(人工智能)技术正以前所未有的速度改变着我们的生活和工作方式。其中,AIAgent作为AI领域的一个新兴分支,正逐渐展现出其巨大的潜力和价值。本文将深入探讨AIAgent的发展现状、核心优势以及未来的发展方向,带您领略这一前沿技术的无限魅力。一、AIAgent的发展现状:技术突破与广泛应用近年来,随着大数据、云计算和机器学习等技术的飞速发展,AIAgent的技术水平得
- C# 与.NET 日志变革:JSON 让程序“开口说清话”
步、步、为营
c#.netjson
一、引言:日志新时代的开启在软件开发的漫长旅程中,日志一直是我们不可或缺的伙伴。它就像是应用程序的“黑匣子”,默默地记录着程序运行过程中的点点滴滴,为我们在调试、排查问题以及性能优化时提供关键线索。在早期,文本日志是我们最常用的记录方式,它简单直接,就像我们随手写下的日记,记录着事件发生的时间、内容等基本信息。然而,随着软件系统规模的不断扩大,架构日益复杂,尤其是在微服务、大数据分析以及云原生应用
- python方差分析误差棒_一文讲透,带你学会用Python绘制带误差棒的柱状图和条形图...
加勒比考斯
python方差分析误差棒
Python数据可视化,作为数据常用的必备技能,是目前大数据和数据分析的一个热门,而matplotlib库作为Python中最为常用和经典的二维绘图库,受到了很多人的青睐,最近已经和大家共同探讨了多种类型的图表的绘制,其中关于误差棒图,咱们已经在上次一起讨论过了,今天咱们继续深入研究误差棒图相关的知识。那今天咱们聊点什么呢?咱们一起探讨一下如何在Python中绘制带误差棒的柱状图和条形图吧!首先,
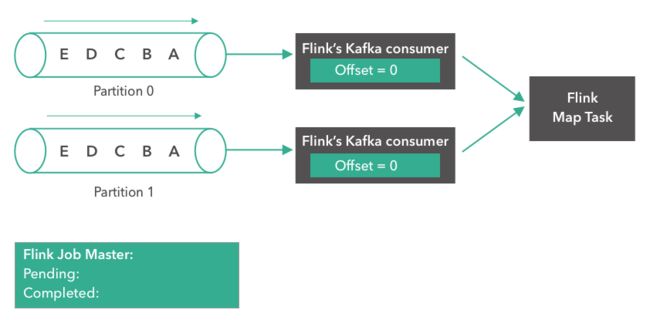
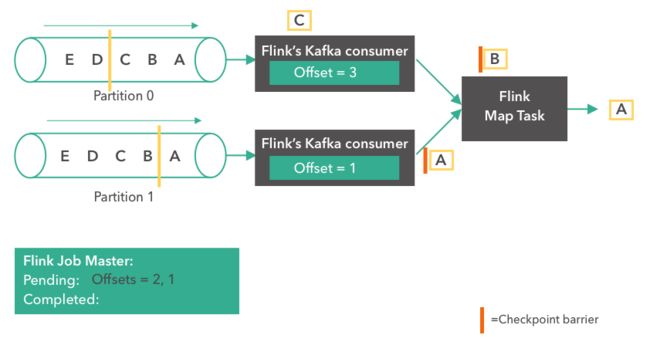
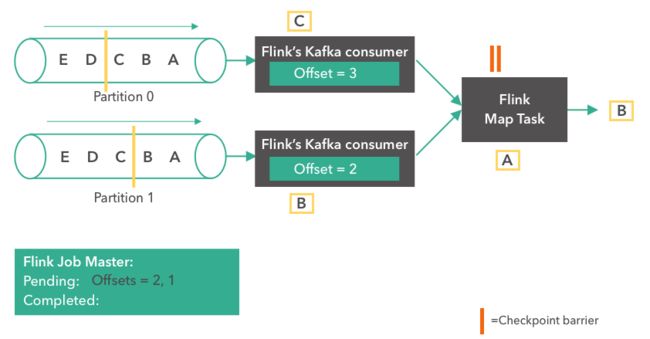
- Flink之kafka消息解析器2
怎么才能努力学习啊
flinkkafka大数据
概要昨天的话题,FlinkSource消费kafka数据自定义反序列化,获取自己想要的数据和类型实现过程publicclassTestWithMetadataDeserializationSchemaimplementsKafkaRecordDeserializationSchema{第一步:自定义实现这个接口,这里的泛型一般的都是自定义类@Overridepublicvoiddeserializ
- Flink之kafka消费数据
怎么才能努力学习啊
flinkkafka大数据
场景:本地构建Flink程序问题描述消费Kafka的数据时,使用Flink新的KakfaSource。会报如下错误KafkaSourcekafkaSource=KafkaSource.builder().setBootstrapServers(kafkaProperties.getProperty("kafka.bootstrap.servers")).setTopics("test2").set
- 【大数据入门核心技术-Hive】(十六)hive表加载csv格式数据或者json格式数据
forest_long
大数据技术入门到21天通关大数据hivehadoop开发语言后端数据仓库
一、环境准备hive安装部署参考:【大数据入门核心技术-Hive】(三)Hive3.1.2非高可用集群搭建【大数据入门核心技术-Hive】(四)Hive3.1.2高可用集群搭建二、hive加载Json格式数据1、数据准备vistu.json[{"id":111,"name":"name111"},{"id":222,"name":"name22"}]上传到hdfshadoopfs-putstu.j
- 镜舟科技荣登《2024 中国大数据产业年度「国产化」优秀代表厂商》榜单!
数据库软件数据分析
在近日于上海成功举办的“释放×数效应·共创智+未来”2024第七届金猿&魔方论坛上,镜舟科技凭借其在数据分析领域的卓越贡献和国产化技术实力,入选《2024中国大数据产业年度「国产化」优秀代表厂商》榜单,展现了其在国产化、信创道路上的成果。镜舟科技自2022年成立以来,始终致力于帮助中国企业建立卓越的数据分析系统,形成自身的“数据护城河”。基于开源项目StarRocks进行深度研发,镜舟科技推出2款
- 云起无垠入选中国信息通信研究院2024年度首期“磐安”优秀案例
人工智能
近日,中国信通院举办的深度观察报告会系列论坛在北京顺利召开。在数字生态治理分论坛上,2024年度首期“磐安”优秀案例——AI+数字安全应用优秀案例遴选结果正式公布,云起无垠凭借其在生成式AI网络安全攻防对抗垂直领域扎实的研究及应用成果,成功入选该年度首期“磐安”优秀案例。当下,数字化浪潮席卷全球,信息技术广泛渗透各个产业。云计算、大数据、人工智能、物联网等前沿技术深度融合,传统制造业生产线、现代服
- 东华发思特&巨杉数据库:打造智慧城市分布式大数据联合解决方案
巨杉数据库SequoiaDB
SequoiaDB巨杉数据库巨杉数据库sequoiadb东华发思特联合解决方案
合作伙伴公司简介东华发思特为东华软件旗下控股子公司,是一家通过高新技术企业认定的技术企业,拥有CMMI3、ISO27001、ISO9000、ISO20000等高级行业资质认证。公司组建了一批视野开拓、经验丰富的管理和研发团队,如今已打造了一系列新型智慧城市产品体系,以HarryData大数据中台和BobbyLink物联网中台为核心,以数字政府、数字文旅、数字乡村、城市精细化管理平台等为产业互联网助
- 【Flink 实战系列】Flink CDC 实时同步 Mysql 全量加增量数据到 Hudi
JasonLee实时计算
Flink实战系列hbasespark大数据
【Flink实战系列】FlinkCDC实时同步Mysql全量加增量数据到Hudi前言FlinkCDC是基于Flink开发的变化数据获取组件(Changedatacapture),简单的说就是来捕获变更的数据,ApacheHudi是一个数据湖平台,又支持对数据做增删改查操作,所以FlinkCDC可以很好的和Hudi结合起来,打造实时数仓,实时湖仓一体的架构,下面就来演示一下同步的过程。环境组件版本F
- 数据治理组织架构
产品经理自我修养
大数据
企业数据治理体系除了在技术方面的实施架构,还需要管理方面的组织架构支撑。一般在数据治理建设初期,集团会先成立数据治理管理委员会。从上至下由决策层、管理层、执行层构成。决策层决策、管理层制定方案、执行层实施。层级管理、统一协调。4.2.1组织架构1)决策层提供数据标准管理的决策职能,通俗理解即拍板定方案。2)管理层审议数据标准管理相关制度对跨部门难的数据标准管理争议事项进行讨论并决策管理重大数据标准
- 基于数据可视化+SpringBoot+Vue的医院综合管理平台设计和实现(源码+论文+部署讲解等)
java李杨勇
Java精品毕设实战案例Java毕业设计实战案例信息可视化springbootvue.js医院综合管理平台Java毕业设计
博主介绍:✌全网粉丝50W+,csdn特邀作者、博客专家、CSDN新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流✌技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等
- 【数据治理】数据治理框架概述
野老杂谈
数据治理数据治理框架DAMA-DMBOKCOBIT企业数据治理数据管理
欢迎来到我的博客,很高兴能够在这里和您见面!欢迎订阅相关专栏:⭐️全网最全IT互联网公司面试宝典:收集整理全网各大IT互联网公司技术、项目、HR面试真题.⭐️AIGC时代的创新与未来:详细讲解AIGC的概念、核心技术、应用领域等内容。⭐️大数据平台建设指南:全面讲解从数据采集到数据可视化的整个过程,掌握构建现代化数据平台的核心技术和方法。⭐️《遇见Python:初识、了解与热恋》:涵盖了Pytho
- 大数据治理:概念、框架与实践
一ge科研小菜鸡
大数据Python大数据
个人主页:一ge科研小菜鸡-CSDN博客期待您的关注引言随着数据量的爆炸性增长,大数据治理(BigDataGovernance)成为数据管理领域的重要议题。大数据治理旨在对海量数据进行有效管理,确保数据的质量、可用性、安全性和合规性,同时为企业决策提供有力支持。本文系统介绍大数据治理的概念、核心框架、实施步骤及典型应用案例,结合实际场景提供技术支持和代码示例。一、大数据治理的定义与重要性1.什么是
- 【Springer斯普林格出版,Ei稳定,往届快速见刊检索】第四届电子信息工程、大数据与计算机技术国际学术会议( EIBDCT 2025)
艾思科蓝 AiScholar
学术会议计算机科学电子信息科学与技术大数据信息可视化可信计算技术深度学习人工智能自然语言处理信息与通信
第四届电子信息工程、大数据与计算机技术国际学术会议(EIBDCT2025)20254thInternationalConferenceonElectronicInformationEngineering,BigDataandComputerTechnology中国-青岛|2025年2月21-23日|www.eibdct.net组织单位长春电子科技大学、加拿大魁北克大学、美国新泽西理工学院、美国欧道
- 软考信安26~大数据安全需求分析与安全保护工程
jnprlxc
软考~信息安全工程师需求分析安全运维笔记
1、大数据安全威胁与需求分析1.1、大数据相关概念发展大数据是指非传统的数据处理工具的数据集,具有海量的数据规模、快速的数据流转、多样的数据类型和价值密度低等特征。大数据的种类和来源非常多,包括结构化、半结构化和非结构化数据。1.2、大数据安全威胁分析(1)“数据集“安全边界日渐模糊,安全保护难度提升(2)敏感数据泄露安全风险增大(3)数据失真与大数据污染安全风险(4)大数据处理平台业务连续性与拒
- 大数据学习(七)Python3操作livy(使用pylivy模块)
猪笨是念来过倒
大数据大数据python
Livy是一个用于与Spark交互的开源REST接口。pylivy是Livy的Python客户端,可以在Spark集群上轻松实现远程代码执行。安装$pipinstall-Ulivy请注意,pylivy需要Python3.6或更高版本。用法所述LivySession类的主界面提供由pylivy:from
- Python多进程 multiprocessing
培之
编程语言python机器学习开发语言
在大数据时代,Python已经成为最受追捧的语言。在本文中,让我们专注于Python的一个特定方面,它使其成为最强大的编程语言之一——Multi-Processing。在阅读本文之前,我建议您阅读我之前关于Python中的线程的文章,因为它可以为当前文章提供更好的上下文。多进程是什么?假设你是一名小学生,你的作业是让1200对数字相乘,这让你感到麻木。假设您能够在3秒内将一对数字相乘。那么总共需要
- Python数据分析与可视化研究
阿尔法星球
pythonpython数据分析开发语言
Python数据分析与可视化研究摘要随着大数据和人工智能技术的飞速发展,Python数据分析与可视化技术已成为现代科学研究、企业决策等领域不可或缺的工具。本研究全面梳理了Python在数据分析与可视化领域的基本理论框架和关键技术,系统分析了Pandas、NumPy等核心数据分析库以及Matplotlib、Seaborn等可视化库的应用优势与特点。通过实际案例,本研究深入探讨了Python在数据清洗
- 物联网导论复习材料
物腐虫生
物联网学习
简答题Q1:物联网的概述,特点,模型,应用,重点是应用层,云计算,数据集成。物联网的概述物联网(IoT,InternetofThings)是指通过各种传感器、设备和网络技术,将物理世界中的物体连接到互联网,实现数据的采集、传输、处理和应用的智能化系统。物联网的特点全面感知:通过传感器实时采集数据。可靠传输:通过互联网和无线网络传输数据。智能处理:利用云计算和大数据技术对数据进行分析和处理,实现智能
- 多线程编程之理财
周凡杨
java多线程生产者消费者理财
现实生活中,我们一边工作,一边消费,正常情况下会把多余的钱存起来,比如存到余额宝,还可以多挣点钱,现在就有这个情况:我每月可以发工资20000万元 (暂定每月的1号),每月消费5000(租房+生活费)元(暂定每月的1号),其中租金是大头占90%,交房租的方式可以选择(一月一交,两月一交、三月一交),理财:1万元存余额宝一天可以赚1元钱,
- [Zookeeper学习笔记之三]Zookeeper会话超时机制
bit1129
zookeeper
首先,会话超时是由Zookeeper服务端通知客户端会话已经超时,客户端不能自行决定会话已经超时,不过客户端可以通过调用Zookeeper.close()主动的发起会话结束请求,如下的代码输出内容
Created /zoo-739160015
CONNECTEDCONNECTED
.............CONNECTEDCONNECTED
CONNECTEDCLOSEDCLOSED
- SecureCRT快捷键
daizj
secureCRT快捷键
ctrl + a : 移动光标到行首ctrl + e :移动光标到行尾crtl + b: 光标前移1个字符crtl + f: 光标后移1个字符crtl + h : 删除光标之前的一个字符ctrl + d :删除光标之后的一个字符crtl + k :删除光标到行尾所有字符crtl + u : 删除光标至行首所有字符crtl + w: 删除光标至行首
- Java 子类与父类这间的转换
周凡杨
java 父类与子类的转换
最近同事调的一个服务报错,查看后是日期之间转换出的问题。代码里是把 java.sql.Date 类型的对象 强制转换为 java.sql.Timestamp 类型的对象。报java.lang.ClassCastException。
代码:
- 可视化swing界面编辑
朱辉辉33
eclipseswing
今天发现了一个WindowBuilder插件,功能好强大,啊哈哈,从此告别手动编辑swing界面代码,直接像VB那样编辑界面,代码会自动生成。
首先在Eclipse中点击help,选择Install New Software,然后在Work with中输入WindowBui
- web报表工具FineReport常用函数的用法总结(文本函数)
老A不折腾
finereportweb报表工具报表软件java报表
文本函数
CHAR
CHAR(number):根据指定数字返回对应的字符。CHAR函数可将计算机其他类型的数字代码转换为字符。
Number:用于指定字符的数字,介于1Number:用于指定字符的数字,介于165535之间(包括1和65535)。
示例:
CHAR(88)等于“X”。
CHAR(45)等于“-”。
CODE
CODE(text):计算文本串中第一个字
- mysql安装出错
林鹤霄
mysql安装
[root@localhost ~]# rpm -ivh MySQL-server-5.5.24-1.linux2.6.x86_64.rpm Preparing... #####################
- linux下编译libuv
aigo
libuv
下载最新版本的libuv源码,解压后执行:
./autogen.sh
这时会提醒找不到automake命令,通过一下命令执行安装(redhat系用yum,Debian系用apt-get):
# yum -y install automake
# yum -y install libtool
如果提示错误:make: *** No targe
- 中国行政区数据及三级联动菜单
alxw4616
近期做项目需要三级联动菜单,上网查了半天竟然没有发现一个能直接用的!
呵呵,都要自己填数据....我了个去这东西麻烦就麻烦的数据上.
哎,自己没办法动手写吧.
现将这些数据共享出了,以方便大家.嗯,代码也可以直接使用
文件说明
lib\area.sql -- 县及县以上行政区划分代码(截止2013年8月31日)来源:国家统计局 发布时间:2014-01-17 15:0
- 哈夫曼加密文件
百合不是茶
哈夫曼压缩哈夫曼加密二叉树
在上一篇介绍过哈夫曼编码的基础知识,下面就直接介绍使用哈夫曼编码怎么来做文件加密或者压缩与解压的软件,对于新手来是有点难度的,主要还是要理清楚步骤;
加密步骤:
1,统计文件中字节出现的次数,作为权值
2,创建节点和哈夫曼树
3,得到每个子节点01串
4,使用哈夫曼编码表示每个字节
- JDK1.5 Cyclicbarrier实例
bijian1013
javathreadjava多线程Cyclicbarrier
CyclicBarrier类
一个同步辅助类,它允许一组线程互相等待,直到到达某个公共屏障点 (common barrier point)。在涉及一组固定大小的线程的程序中,这些线程必须不时地互相等待,此时 CyclicBarrier 很有用。因为该 barrier 在释放等待线程后可以重用,所以称它为循环的 barrier。
CyclicBarrier支持一个可选的 Runnable 命令,
- 九项重要的职业规划
bijian1013
工作学习
一. 学习的步伐不停止 古人说,活到老,学到老。终身学习应该是您的座右铭。 世界在不断变化,每个人都在寻找各自的事业途径。 您只有保证了足够的技能储
- 【Java范型四】范型方法
bit1129
java
范型参数不仅仅可以用于类型的声明上,例如
package com.tom.lang.generics;
import java.util.List;
public class Generics<T> {
private T value;
public Generics(T value) {
this.value =
- 【Hadoop十三】HDFS Java API基本操作
bit1129
hadoop
package com.examples.hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoo
- ua实现split字符串分隔
ronin47
lua split
LUA并不象其它许多"大而全"的语言那样,包括很多功能,比如网络通讯、图形界面等。但是LUA可以很容易地被扩展:由宿主语言(通常是C或 C++)提供这些功能,LUA可以使用它们,就像是本来就内置的功能一样。LUA只包括一个精简的核心和最基本的库。这使得LUA体积小、启动速度快,从 而适合嵌入在别的程序里。因此在lua中并没有其他语言那样多的系统函数。习惯了其他语言的字符串分割函
- java-从先序遍历和中序遍历重建二叉树
bylijinnan
java
public class BuildTreePreOrderInOrder {
/**
* Build Binary Tree from PreOrder and InOrder
* _______7______
/ \
__10__ ___2
/ \ /
4
- openfire开发指南《连接和登陆》
开窍的石头
openfire开发指南smack
第一步
官网下载smack.jar包
下载地址:http://www.igniterealtime.org/downloads/index.jsp#smack
第二步
把smack里边的jar导入你新建的java项目中
开始编写smack连接openfire代码
p
- [移动通讯]手机后盖应该按需要能够随时开启
comsci
移动
看到新的手机,很多由金属材质做的外壳,内存和闪存容量越来越大,CPU速度越来越快,对于这些改进,我们非常高兴,也非常欢迎
但是,对于手机的新设计,有几点我们也要注意
第一:手机的后盖应该能够被用户自行取下来,手机的电池的可更换性应该是必须保留的设计,
- 20款国外知名的php开源cms系统
cuiyadll
cms
内容管理系统,简称CMS,是一种简易的发布和管理新闻的程序。用户可以在后端管理系统中发布,编辑和删除文章,即使您不需要懂得HTML和其他脚本语言,这就是CMS的优点。
在这里我决定介绍20款目前国外市面上最流行的开源的PHP内容管理系统,以便没有PHP知识的读者也可以通过国外内容管理系统建立自己的网站。
1. Wordpress
WordPress的是一个功能强大且易于使用的内容管
- Java生成全局唯一标识符
darrenzhu
javauuiduniqueidentifierid
How to generate a globally unique identifier in Java
http://stackoverflow.com/questions/21536572/generate-unique-id-in-java-to-label-groups-of-related-entries-in-a-log
http://stackoverflow
- php安装模块检测是否已安装过, 使用的SQL语句
dcj3sjt126com
sql
SHOW [FULL] TABLES [FROM db_name] [LIKE 'pattern']
SHOW TABLES列举了给定数据库中的非TEMPORARY表。您也可以使用mysqlshow db_name命令得到此清单。
本命令也列举数据库中的其它视图。支持FULL修改符,这样SHOW FULL TABLES就可以显示第二个输出列。对于一个表,第二列的值为BASE T
- 5天学会一种 web 开发框架
dcj3sjt126com
Web框架framework
web framework层出不穷,特别是ruby/python,各有10+个,php/java也是一大堆 根据我自己的经验写了一个to do list,按照这个清单,一条一条的学习,事半功倍,很快就能掌握 一共25条,即便很磨蹭,2小时也能搞定一条,25*2=50。只需要50小时就能掌握任意一种web框架
各类web框架大同小异:现代web开发框架的6大元素,把握主线,就不会迷路
建议把本文
- Gson使用三(Map集合的处理,一对多处理)
eksliang
jsongsonGson mapGson 集合处理
转载请出自出处:http://eksliang.iteye.com/blog/2175532 一、概述
Map保存的是键值对的形式,Json的格式也是键值对的,所以正常情况下,map跟json之间的转换应当是理所当然的事情。 二、Map参考实例
package com.ickes.json;
import java.lang.refl
- cordova实现“再点击一次退出”效果
gundumw100
android
基本的写法如下:
document.addEventListener("deviceready", onDeviceReady, false);
function onDeviceReady() {
//navigator.splashscreen.hide();
document.addEventListener("b
- openldap configuration leaning note
iwindyforest
configuration
hostname // to display the computer name
hostname <changed name> // to change
go to: /etc/sysconfig/network, add/modify HOSTNAME=NEWNAME to change permenately
dont forget to change /etc/hosts
- Nullability and Objective-C
啸笑天
Objective-C
https://developer.apple.com/swift/blog/?id=25
http://www.cocoachina.com/ios/20150601/11989.html
http://blog.csdn.net/zhangao0086/article/details/44409913
http://blog.sunnyxx
- jsp中实现参数隐藏的两种方法
macroli
JavaScriptjsp
在一个JSP页面有一个链接,//确定是一个链接?点击弹出一个页面,需要传给这个页面一些参数。//正常的方法是设置弹出页面的src="***.do?p1=aaa&p2=bbb&p3=ccc"//确定目标URL是Action来处理?但是这样会在页面上看到传过来的参数,可能会不安全。要求实现src="***.do",参数通过其他方法传!//////
- Bootstrap A标签关闭modal并打开新的链接解决方案
qiaolevip
每天进步一点点学习永无止境bootstrap纵观千象
Bootstrap里面的js modal控件使用起来很方便,关闭也很简单。只需添加标签 data-dismiss="modal" 即可。
可是偏偏有时候需要a标签既要关闭modal,有要打开新的链接,尝试多种方法未果。只好使用原始js来控制。
<a href="#/group-buy" class="btn bt
- 二维数组在Java和C中的区别
流淚的芥末
javac二维数组数组
Java代码:
public class test03 {
public static void main(String[] args) {
int[][] a = {{1},{2,3},{4,5,6}};
System.out.println(a[0][1]);
}
}
运行结果:
Exception in thread "mai
- systemctl命令用法
wmlJava
linuxsystemctl
对比表,以 apache / httpd 为例 任务 旧指令 新指令 使某服务自动启动 chkconfig --level 3 httpd on systemctl enable httpd.service 使某服务不自动启动 chkconfig --level 3 httpd off systemctl disable httpd.service 检查服务状态 service h