Win10编译GPU版YOLOv4并训练VOC数据集
我的配置写在前面
系统:windows
cuda版本10.1
cudnn是cudnn-10.1-windows10-x64-v7.6.4.38
opencv4.3.0
显卡1060
本文参考darknet官方参考https://github.com/AlexeyAB/darknet
一、编译步骤
编译前别忘了把Makefile文件修改一下
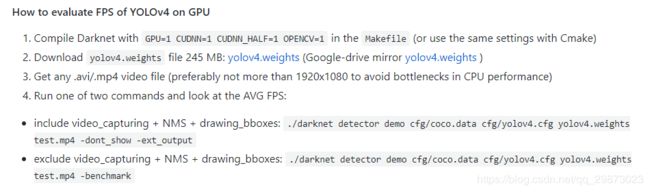
修改后就可以编译了,照之前用cmake配置简单了很多
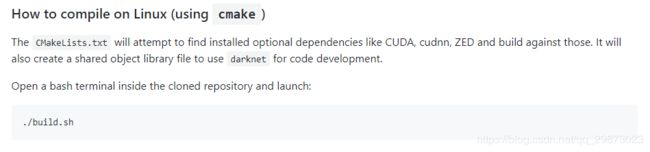
不知道是不是我的问题,出现报错的解决方法

Copy-Item : 未能找到路径“D:\darknet\share\darknet\”的一部分。
所在位置 D:\darknet\build.ps1:224 字符: 3
+ Copy-Item cmake\Modules\*.cmake share\darknet\
+ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+ CategoryInfo : NotSpecified: (:) [Copy-Item], DirectoryNotFoundException
+ FullyQualifiedErrorId : System.IO.DirectoryNotFoundException,Microsoft.PowerShell.Commands.CopyItemCommand
解决方法:我在创建这个路径就好了

这样应该就是编好了,然后去D:\darknet\build_win_release_novcpkg\Release\darknet.exe目录把darknet.exe放到x64下D:\darknet\build\darknet\x64
二、训练一个自己的数据集
按照VOC数据集要求的需要按照如下结构创建数据集
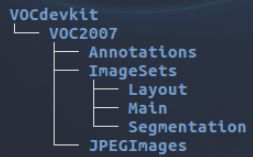
主要使用 Annotations、ImageSets里的Main 和 JPEGImages 这三个文件夹
1)Annotations文件夹里存放xml标签文件:

2)ImageSets里的Main文件夹里存放训练集和验证集:
![]()
这两个文件里面的内容只需填要图片的名称即可,不需要后缀名
比如我的图片是:00001.jpg,那么我只要写00001即可
traint.txt格式如下:(text.txt一样的格式)

3)JPEGImages文件夹里存放训练集和验证集的图片文件
全部图片放在一起即可,到时程序会根据你的train.txt和test.txt去找你的图片和对应的标签文件,所以要保证同一张图片对应的标签文件的名称一样
然后利用scripts目录下的voc_label.py脚本生成到时候训练时调用的图片关联txt文件
voc_label.py要修改两个地方:

并且注释掉最后两行

然后执行voc_label.py
python voc_label.py
这时会在/VOCdevkit/VOC2007生成labels文件夹,里面是对应图片的标签
除此之外还会在data目录下生成2007_train.txt 和 2007_test.txt 这两个文件
2007_train.txt里面是训练集图片的具体路径位置,它将会作为后期训练的一个索引文件来找到那些数据集。2007_test.txt同。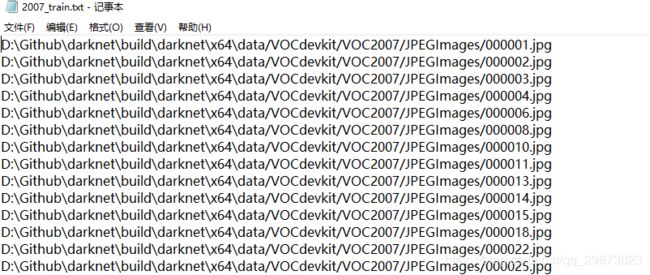
sets那个地方改成刚刚在Main里面添加了那个文件的名称
classes那个地方列表里的内容改成你自己数据的类的名称(直接复制图片路径的classes里的内容就好)
到这里数据集就准备好了。
接着修改训练配置文件
1、修改训练初始化超参数(我们这里以yolov4-custom.cfg为例子)
修改(或者创建)data下的config.data和config.names,根据自己的情况修改classes的数目,是几类就改为几,我这里写的一,因为我初学只标注了一个类。。同样的在config.names填上标签名
data:
classes=1
train=data/2007_train.txt
valid=data/2007_test.txt
names=data/config.names
backup=backup/
config.names(同classes.txt里的)
dog
person
cat
tv
car
meatballs
marinara sauce
tomato soup
chicken noodle soup
french onion soup
chicken breast
ribs
pulled pork
hamburger
cavity
然后修改cfg/yolov4-custom.cfg,修改三个地方:yolo块下的classes,anchor,yolo上面块的filter。filter可以用filters=3*(class +5)公式计算,我这里是15类,所以填的60

anchor的内容需要在x64目录下使用
./darknet.exe detector calc_anchors data/config.data -num_of_clusters 9 -width 416 -height 416
获得
然后分离训练集与测试集 Process.py ,训练集和测试集的比例按需分配,我这里样本太少了,所以选的9/1。最后改一下图片格式,我这里是png。

然后python Process.py就会在imagesets中得到分好的数据集
最后训练和测试就好了
训练
.\darknet.exe detector train data/config.data cfg/yolov4-custom.cfg weights/yolov4.conv.137 -map
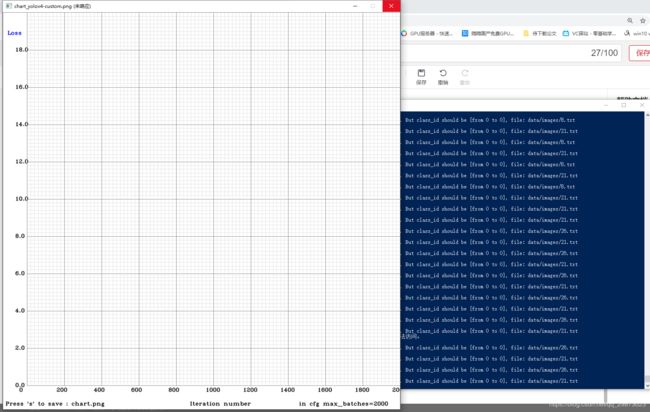
.\darknet.exe detector train data/config.data cfg/yolov4-custom.cfg weights/yolov4.conv.137 -map -show_imgs
训练的过程中会展示这个图,和弹出你标注的图片
测试
.\darknet.exe detect data/config.data cfg/yolov4-custom.cfg backup/yolov4-custom_best.weights data/images/1.png -thresh 0.5