【待更新】感知视频编码中的感知检测技术(显著性物体检测向)
之前对ROI编码感兴趣,做了显著性检测方面的文献综述。截至到2019年1月13号有13400字。
现在搬上来,一来交流,二来重温
感知视频编码PVC
HVS

针对HVS所构建的数学模型分类

基于HVS可以做很多方面的改进,目前PVC有三种思路,分别是:基于视觉敏感度的、基于视觉注意力的以及混合编码。其中在基于视觉注意的思路中,最为常见的编码方式是基于ROI的编码。

基于ROI的视频编码
在基于ROI的视频编码任务中,任务所感兴趣的区域是:人眼可能会关注/注意到的区域,编码基本思路是:在视频编码前,对输入的视频场景进行视觉感知分析以确定感兴趣区域。在编码过程中,通过调整编码参数来分别控制感兴趣区域和非感兴趣区域的失真程度,进而改善感兴趣区域的编码质量。因此基于ROI的编码方法主要研究点在于:一是感兴趣区域的提取,二是编码参数的调整。

感兴趣区域的定义
对输入的视频序列,如何确定感兴趣区域是第一个关键问题,在开始梳理ROI提取方法之前首先解释以下若干术语的具体概念。
感兴趣区域(Region of Interest,ROI)起源于计算机视觉(Computer Vision,CV)领域,指的是CV任务所感兴趣的区域,ROI的定义会随着CV任务的不同而不同。在目标检测、语义分割等任务中也会出现ROI术语,ROI在这些任务中的定义与在视频编码中的定义是不一样,但是可能会相交,因此会出现用语义分割等的方法来解决视频编码领域中ROI提取的问题,这在后面的ROI提取技术现状部分将详细解释。
视觉注意力(Visual attention)起源于认知神经科学中,后面被引入到CV领域。视觉注意力属于注意力的一部分,注意力本身是一个很大的概念,我们只考虑观看图像视频这一情境下,此时视觉注意力是指观看者在观看视频图像时,将注意力所投放到的区域,也即眼睛关注的区域。
注意力在认知神经领域和CV领域都有对应的bottom-up和top-down(模型)分类。具体到视觉注意力中分别是:自底而上的视觉注意力(bottom-up visual attention)和自顶而下的视觉注意力(top-down visual attention),前者一般是指观看者在无意识的情况下被图像中的某些部分吸引而注意到;后者则跟人的主观想法有关,如任务驱动,比如当在观看篮球比赛时,观看者会根据自己的意愿,有目的地主动关注。
显著性检测(Saliency Detection,SD)是将视觉注意引入CV领域以后用来构建其数学模型的一类重要技术方法。
综上所述,在基于ROI的视频编码中,编码任务的感兴趣区域就是人眼所投注视角注意力的区域,因而显著性检测是一项重要的ROI提取方法。但是具体的ROI提取方法确定取决于视频编码是如何定义ROI的,而针对不同的编码场景会对ROI提出不同的要求、给出不同的定义。
ROI提取技术现状
通过上一小节对概念的梳理,明确了视频编码任务的ROI就是人眼的视觉注意区域,而用来对视觉注意建模最有效的一种方式就是显著性检测技术。因此,显著性检测技术时ROI提取的一项重要方法。除此之外,在某些具体的应用场景下,具体编码场景对ROI有具体的要求,此时也可以将ROI提取问题转为其他CV任务来解决。
人脸是最常见也是最容易引起观看者注意的特征之一,在特殊的应用场景下,根据需要可以将ROI直接定义为人脸。这样就将显著性检测任务转为人脸检测任务[27-29];还有由于人眼更倾向于关注视频场景中运动的物体,因此人对运动物体的失真比静态物体更加敏感,例如在观看单人跳水比赛时,观看者肯定时关注选手,这时候我们只需要应用视频的语义分割模型把运动的选手分割出来,高比特编码即可。这种问题的转换一般都是在有任务驱动的情况下才会成立的,通常对应的是自顶向下的注意力。
目前用到ROI视频编码中的视觉注意可计算模型主要是bottom-up类型的——通过一种或整合多种视频特征进而确定显著区域,对应的是自底向上的视觉注意力。采用的视频特征主要包括以下几种类型:l)空间域视频特征,如肤色[]、亮度[]、色度[]以及纹理[]等;2)时间域视频特征,比如运动[];3)综合考虑空间域和时间域的视频特征[]。
由于视频场景中的时域和空域的视觉信息都会对HVS的感知结果造成影响,近年来,基于时空域视觉特征融合的ROI视频编码越来越受到视频处理领域研究人员的关注。但是相比显著性检测本身的发展,应用在视频编码中的显著性检测技术相对滞后,主要还是依赖于人工设计的特征。本课题重点研究显著性检测技术在ROI提取中的应用,具体的显著性检测技术现状将在2.3节中具展开介绍。
基于ROI信息的视频编码优化策略
本课题将经过ROI提取之后得到的结果称为显著图(saliency map),显著图确定以后,很多编码参数可以根据显著图自适应地调整,使得更多的比特资源和计算资源可以分配到显著区域中。随着HEVC编码标准的提出和推广,在混合编码的大框架下,有越来越多的编码参数可供选择,参数的调整也越来越灵活。包括量化参数、块划分模式、块编码模式、帧内预测模式、帧间参考帧数目、运动搜索的范围、运动估计的精度。本课题以HEVC标准下的编解码方法为研究对象,以下主要对针对HEVC标准下的优化策略进行梳理。
从应用方式来说,分为“硬”优化和“软”优化,前者在编码过程中只区分显著区域和非显著区域,对于显著区域内部的各像素采用相同的编码方式[];而后者区分显著程度,编码器对不同程度的显著区域会给予不同程度的“重视”,一般是通过将显著图加权到原有编码计算上来实现的。
现有基于ROI的编码方法采用后者居多,但是考虑到目前引入到视频编码中的显著性检测方法自身的限制, “硬”编码还是有很大的发展空间的。将这在后续2.3节中在做讨论。
从优化位置来说,分为编码器外[]和编码器内[],后者又进一步分为率失真建模[]、码率控制[]和复杂度控制[]。率失真建模和码率控制是目前基于ROI的视频编码研究中主要应用ROI信息来优化的两大部分。
[]在开始编码之前,利用得到的显著图对原始输入视频帧做空间滤波,加重非显著区的模糊程度,这种方法没有调整编码参数,快速简单,在一定程度的效果。[]提出了类似的思路,在编码环节中,对预测误差进行滤波。
对于率失真模型部分,具体是对率失真计算公式进行改进。率失真公式主要有两点:失真的定义以及拉格朗日因子的定义。[]将显著图作为权重,加权到原来定义的失真上,[]也将显著图作为权重,加权到原来定义的拉格朗日因子上;而[]则是改变图片的质量评价标准,将从人眼主观出发而设计的SSIM质量评估准组替代原来的失真计算方法。
码率控制本身分为两大步,目前HEVC建议的码率控制算法为JCTVC-K0103[],这是一种基于R-λ模型的多层次码率控制算法。第一步是比特分配,JCTVC-K0103设计了GOP、图片、基本单元三种级别的比特分配,各级别有对应的比特计算公式。
[]在帧级别和CTU级别的比特分配计算中,分别将各级别对应的感知信息用作计算公式中的权重,其中帧级别的比特分配计算公式如下:
PSMF就是[]计算得到的视觉敏感度。另外,[183#]在LCU()级别上将传统采用MAD计算一个CTU权重的方法用基于显著图的方法代替,并保留原来的计算结果,最终的权重是传统方法和基于显著性得到的结果的折中,在一定程度上保留传统方法的结果,在一定程度上可以
另外[]针对CTU级别上的比特分配,借助二值化的显著图将ROI和非ROI区域分开,在帧级别分配结果的基础上为两个区域分配不同的比特数,各区域在随后的编码处理中相互独立。
[]则提出bpw(bit per weight,将显著值当作weight)的概念,以bpw为单元来计算分配得到的比特数,进一步得到以bpp为单位的比特数。
码率控制的第二步是利用率失真模型来达到每个级别分配的比特数,也就是确定各类编码参数,包括模式决策、运动估计以及量化参数等。具体通过率失真优化方式来在达到目标比特的同时实现尽量小的失真。码率控制的核心问题之一是码率于失真之间关系建模,即R-D模型。传统的R-D模型假设量化值是决定码率的主要因素,因此在Q域上进行建模。而后随着HEVC标准提供了越来越灵活的块划分、预测模式等选择,[]认为量化值对码率的影响不再占主导位置,在λ域提出了R-λ模型,通过该模型可以直接从目标码率中计算得到λ,进而由λ来统一决定模式决策、运动估计以及量化参数等编码参数。R-λ模型在学界引起了广泛的讨论和研究。具体模型如下:
模型
下面介绍感知信息在码率控制第二步的改进点。
首先是对R-λ模型的改进,改进思路同对率失真模型的改进类似,也是从定义入手,[#175]联合SSIM和SSE两种质量评估准则从新定义了失真,进而改变了λ的定义。[#183]则从感知角度引入基于显著性的失真,具体做法是对显著图做编码和重建,并将编码前后显著图的像素绝对残差之和作为显著图的失真,将该失真加入到率失真模型当中,通过对码率求偏导得到基于显著性的λ——λ_saliency。最终的λ是λ_saliency与传统方法得到的λ_HEVC的折中。
[173#]对ROI和非ROI区域,做出不同程度的λ、QP波动范围限制。
另外[182#]利用得到的显著值,为CTU设定可以划分的深度,到了快速模式选择的目的。[]设定非ROI区域的帧间运动搜索范围是ROI区域的1/8。
针对基于RDO的多QP优化,也即自适应量化(Adaptive QP),[]根据感知信息的不同改变不同区域的候选量化值;[]基于规则,对计算得到的显著值划分等级,设定显著值到自适应量化的基础QP值的映射。
显著性检测技术
正如上面得出的结论:在基于ROI的视频编码任务中,显著性检测是一项重要的ROI提取技术。以下来介绍国内外显著性检测技术方面的研究现状。
显著性检测技术分类以及概览
显著性检测技术分为图像显著性检测和视频显著性检测。视频显著性检测开始的要比图像的晚,主要研究点在于:在图像显著性检测的基础上,以合理有效的方式加入时间信息,从而将显著性检测任务扩展到视频数据上。
无论是图像(静态)数据还是视频(动态)数据,显著性检测任务按照解决思路来说分为两大类,分别是人眼关注点的预测(Fixation prediction, FP)和显著物体的检测(Salient object detection, SOD)。最早的时候研究FP的图像显著性检测居多,后来显著物体检测居上。
前者主要参考采集而来的人眼眼动数据来预测观看者在观看图像或视频时可能的关注点,显著检测的输出结果通常是零散的点,以热力图形式表示,结果举例如下:

图 2 1 via #195

图 2 2 via #194
后者的目标是将最显著的物体区域完整标注出来,其输出结果通常是二值化的显著图,该图将认为是显著的物体的轮廓与非显著区域用二值化的像素值区分开来,结果举例如下:

图 2 3 via#190
由于Fixation Prediction方法对关注区域的轮廓刻画的不够清晰,对于视频编码而言,更加有用的是显著物体的整个区域,例如图像中一匹马对应的所有像素,而不是这个物体上的若干个点,例如马的眼睛。因此,本课题主要考虑SOD方式作为视频编码中的一种ROI提取方法。
按照方法论可将显著性检测技术分为自顶向下的模型(top-down model)和自底向上的模型(bottom-up model),这与视觉注意力的分类吻合。同样地,两种模型的不同之处在于前者是任务驱动的,一般适用于观看者带有目的性时。目前的显著性检测方法以bottom-up模型研究居多[#xx-#xx]。基于方法论的分类类别与基于解决思路的分类类别两者不矛盾,FP和SOD均可以有自顶向下和自底向上的两种不同的实现模型。
按照研究发展历程可以分为传统方法和基于学习的方法[#188]。

传统方法主要是从一些简单的知识或规律中人为制定规则并设计特征,进行启发式的显著推理(Saliency Inference)。比如,我们发现在通常情况下,一张图像中色彩鲜艳的区域会更加吸引人眼的关注,那也就是说对人眼来说,该区域的显著度是比较高,因此在显著性计算模型中就可以设计对图像进行颜色对比度的计算。因此受到特征综合理论[21via#220]和Guided search[via#220:22,23]等注意的心理学模型基础上, 早期的研究提出了大量的可计算注意力选择模型, 以用于模拟人类的视觉注意机制。包括: 基于认知、贝叶斯、决策论、信息论、图模型、频域分析和基于模式分类的视觉注意模型。
在以上众多模型中,受到认知科学领域研究成果的启发,尤其是#219提出的金字塔理论,Itti于1998年将视觉注意的问题用计算模型表达出来,首次正式地提出了基于认知的视觉注意计算模型,该模型采用多特征融合思想,将多个低层级特征融合在一起并计算显著图。除了生成显著图,#219也探讨了注视点的转移机制,具体模型如下图所示【是启发式吗?我连什么是启发式也没有搞的很懂】:
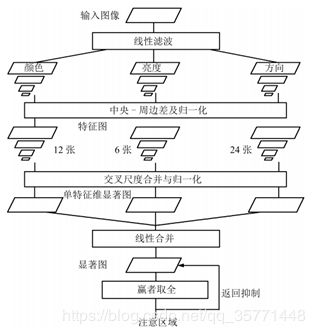
图 2 4 via #198
对于一幅输入的图像,该模型提取初级视觉特征:颜色(RGBY)、亮度和方位、在多种尺度下使用中央周边(Center-surround)操作产生体现显著性度量的特征图,将这些特征图合并得到最终的显著图(Saliency map)后,利用生物学中赢者取全(Winner-take-all)的竞争机制得到图像中最显著的空间位置, 用来向导注意位置的选取,最后采用返回抑制 (Inhibition of return) 的方法来完成注意焦点的转移[]。从模型的输出可以看到,该模型最终是得到一个注视点,这属于Fixation Predication,但是后来 [尾注 ]将saliency detection从以fixation prediction占绝对统治地位的时代,引导到了以salient object detection为主的时代。即使是在salient object detection方式中,#219模型已经成为自低而上模型的典型代表[#220],加上原本研究bottom-up模型的人就很多,#219模型奠定了后续很长时间的研究基调,直到深度学习的出现。
由于传统方法对人工的依赖,设计的特征较为低级,不能充分地表征数据特性,另外模型的泛化性不够好,无法应对多变的图像内容。视频场景相对复杂的视频。随着机器学习的发展,尤其是深度学习的出现,深层神经网络可以在带有标注的训练数据的监督下,自动提取对CV任务有帮助的高层特征,而不用人为进行特征的定义和筛选,进而使得训练得到的模型更加灵活,可以应对内容变化的图像视频数据,增强模型的鲁棒性。对于很多CV任务而言,只要给予足够的训练数据,就可以得到非常好的效果, 比如图像分类、目标检测以及语义分割任务。同样地可以利用深层神经网络强大的全局性、高层级特征提取能力,来自动提取对显著性检测任务有用的多层级特征(hierarchical features)[#205 ]并根据这些特征提取显著图。试验也证明了以Deep CNN based model为代表的一系列显著性检测模型的效果要优于传统方法[…,#DSS,#203, via 205:4,13-7,49]。
Deep CNN based approach可以进一步地分为region based deep feature learning和end-to-end learning FCN[#190]。前者将图像分成几个独立的处理区域,对这些区域分别进行特征提取。这种方法由于在特征提取过程存在冗余会产生不必要的计算消耗和空间消耗。随着端到端深度网络在语义分割任务上的成功,越来越多的研究工作出现在了端到端的的训练,以进行像素级别的显著图计算[#137]。而后者是将输入的数据直接映射为对应的显著图。目前的研究大多集中在end-to-end模型上。
接下来对基于deep CNN方法的显著物体检测展开详细的研究现状分析。
图像显著物体检测技术
从2015年开始出现了基于深度学习的图像显著物体检测的研究,起初[Supercnn]直将CNN用在超像素(super-pixel)层面上:网络模型的输入是图像的超像素,网络直接基于超像素来提取特征并判断显著值。
基于deep CNN的检测模型大多数是以监督学习的方式来训练模型参数,对于一个计算机视觉任务,为了达到像训练数据标注那样的效果,网络会自动去学习特征。那么为了让网络能够学得好——即能够提取出有效的、对计算机视觉任务完成有用的特征,就需要设计合理的网络。包括网络结构的设计、损失函数的设计以及超参数的设定等,本人重点对网络结构的设计做详细梳理和归纳。
一方面,对于多数计算机视觉任务而言,如语义分割、显著性检测、图像分类,2D空间域上的全局特征和局部特征都是非常重要的,前者表征抽象的语义信息,后者表征具体的细节信息。两种特征有效结合才能做到对图像数据有全面的认识。因此现今的研究大多数是围绕着局部与全局之间或相互作用,或相互补充等思路来改进网络模型。
接下来先介绍能够改进的切入点以及若干改进策略,然后再介绍用来实现这些改进策略的网络结构分类。
重要的基础网络(这样放怕是有点不高不低 不上不下的)
全卷积神经网络FCN
CVPR2015《Fully Convolutional Networks for Semantic Segmentation》首次提出用端到端网络模型来实现语义分割,简称FCN。该网络直接拿segmentation 的 ground truth作为监督信息,训练一个端到端的网络,让网络做pixelwise的prediction,直接预测label map。该模型对传统的CNN提出了三大改进,分别是:
卷积化(Convolutional):将传统的CNN后面全连接层替换为卷积层,使得网络可以接受任意尺寸的图像输入。
上采样(Upsample):此处的上采样即是反卷积(Deconvolution),在普通的CNN中经过多次“池化-卷积-池化”操作以后会使得输入的特征图分辨率越来越小,为了得到和原图等大的分割图,该文提出了上采样/反卷积操作。反卷积和卷积类似,都是相乘相加的运算。只不过后者是多对一,前者是一对多。而反卷积的前向和后向传播,只用颠倒卷积的前后向传播即可。所以无论优化还是后向传播算法都是没有问题。图解如下:
但是,虽然文中说是可学习的反卷积,但是作者实际代码并没有让它学习,可能正是因为这个一对多的逻辑关系。
跳跃结构(Skip Layer):该结构用于优化结果,因为只将全卷积之后的结果直接上采样所得到的结果是很粗糙的,所以作者将不同池化层的结果进行上采样之后来优化输出。具体结构如下:
另外,目前常用的四种基础CNN结构。分别为普通CNN、全卷积网络FCN、带有反卷积的FCN以及带有全卷积和反馈的FCN:
还有对称结构的带有反卷积的FCN,这种模型有encoder-decoder的框架思想,主要使用了反卷积和上池化。
SegNet
DeconvNet
上采样,分为普通意义上的采样,以下图示是最大池化方式地下采样与对应的上采样:
以及反卷积:
HED
在ICCV2015中被[尾注 ]首次提出来用于实现端到端的图像边缘检测问题。解决思路是利用多尺度和多级别的特征学习。在一般的skip-layer结构的基础上,
添加side-output:在对应卷积层后的侧边插入一个输出层 side-output,在side-output层上进行监督,从而实现了将监督落实到中间的若干卷积层上,而非仅对最后的输出层做监督。每个side-output层的输出都是一个CV任务结果,使得随着网络层数的加深,结果向着边缘检测方向进行。
另外随着卷积层的加深,网络的感受野变大,对应side-output层变小。最后将不同感受野下产生的不同尺寸的结果送入一个weighted-fusion layer中计算,最终输出多尺度融合的结果。HED模型类似是一个相互独立多网络多尺度预测系统,是将多个side outputs组合成一个单一深度网络。一般网络都是使用一个输出的loss函数进行单一的回归预测,而边缘检测可以通过多个回归预测,得到结合的边缘图效果更好。网络结构可视化举例如下:
空洞卷积
ICLR2016[尾注 ]
金字塔
FAIR出品的Feature Pyramid Networks for Object Detection#223
策略分类
正如本节开头所说的,对于2D图像数据,也就是空间域,要想使得网络获得全面的信息表征,以便做精确的显著性判决,需要将空间域上的局部信息和全局信息都考虑到。具体关键策略有如下若干种,这些策略可以相互套用。
Multi-context
这是早期局部信息与全局信息的整合策略,是直接指向原始图像的空间局部和全局。如#215直接用两个的CNN网络分别对整体图像和局部图像做特征提取,最后将两个网络的输出合在一起。可以认为是region based deep feature learning和end-to-end learning两种方法的结合。
#214Deep networks for saliency detection via local estimation and global search:结合局部预测和全局搜索两者来完成任务,两者分别由两个不同的CNN实现。
Multi-level
与multi-context策略不同的是,multi-level是从CNN网络自身特点出发寻找改进点。 CNN网络结构利用卷积运算,不断在当前卷积运算结束之后叠加新的卷积运算,使得卷积层输出的特征图层层叠加,特征图所表征的数据信息越来全局化、语义高度抽象化。这种叠加的做法使得CNN具有提取层次化特征(hierarchical features)的特点。其低卷积层能够很好地捕捉数据的局部细节信息,对应的是低级特征(low-level features),而高卷积层则擅长捕捉全局语义信息,对应的是高级特征(high-level features)。CNN自身结构决定了既可以获得局部细节信息也可以获得全局语义信息,因此multi-level策略就是指对CNN网络中的低级特征与高级特征做关联。
高低层级特征的相互配合可以分为三种方式,
融合(fusion):单纯地将低级特征与高级特征连接在一起,一般夏勇ski-layer结构的网络模型来实现,如带有shot connection的网络(DSS)。
指导:在特征计算过程中,高级特征反馈到低级特征上,如#137提出的带有反馈线的CNN(recurrent CNN);
补充:在特征计算过程中,低级特征为高层特征补充细节信息,如#137提出的渐进式显著图计算框架。
对于第一种融合方式,有以下三种网络结构,分别是直接融合、通过side-output融合、side-output之间存在相互影响:
最后一种方式来自#186提出的DSS模型,该检测模型应用在了2017年华为发布的新款手机mate 10中。在华为mate 10手机上可以达到实时的处理速度。经过了严苛的工业级测试,2016年年底到现在的华为高端手机基本上都用的这个方法支撑智能拍照中的大光圈功能。
该模型以用于边缘检测的HED模型为基础,向网络的side-output结构中添加了short connection——通过该短连接采用top-down的方式将高层级的边输出作用到低层级的边输出上,间接地实现了高层级特征与低层级特征的融合。
图 2 5 基础网络是VGG
#137同样采用multi-level策略,整体网络结构如下图所示:
该模型有两个地方用到了multi-level策略,分别采用了两种不同的方法。首先是在特征提取部分,应用了高层特征指导低层特征的方法。受Multi-Path Feedback Recurrent Neural Network(MPF-RNN)的启发,提出了多路循环引导模块(Multi-Path Recurrent Guidance Module)。该模块使得网络提取的层级特征做自顶而下的反馈操作。下图是将两次训练流程展开的网络结构:
如图所示,在训练过程中,保存上一次计算时网络的最终输出结果,在下一次计算时,通过反卷积的方式将其依次扩大到对应特征图的尺寸大小,并将每次反卷积的结果与第二次各卷积层输出的特征图相加,从而实现高层特征对低层特征的指导,进而使得训练得到的网络可以提取出更加精确的特征。但是可以网络
另外一处是在显著图生成部分,采用低级特征为高级特征补充细节的方式。在此过程中,加入了“选择性”——为不同的低层特征赋予对高层特征不同程度的影响能力。这是由于在众多特征中,不同特征各自所表征的数据信息对检测任务而言有不同程度的作用,有些特征甚至会对检测结果造成干扰。比如描述了平滑背景的特征,对于检测任务来说,该背景是不重要的,甚至需要网络刻意忽略。为此该模型引入注意力机制,为每个级别的特征赋予不同程度的“关注度”——即权重值。具体做法是采用空间注意力和通道注意力两种soft attention机制结合的方式,分别对一个卷积层出书的一组特征图进行权重计算,使得处理完feature maps之后得到的attentive feature maps可以更加突出对检测显著有用的部分。
首先分别求出在HW平面上的Spatial attention map:α_s,和在C维度上的衡量各个channels的重要性的长向量α_c。
1)设给定某一个Layer的特征图组F的size为 CxHxW,因为显著性区域在图片中只占一部分,所以在HW平面中,各个位置的重要程度可能不同。于是提出了:Spatial Attention (SA)(空间注意力机制)。
这里的注意力机制是将feature maps的通道维度给压缩到了一个feature map上,权重系数是每个像素占总像素之和的比重在做归一化。主要工作在于训练压缩网络使得网络可以合适地压缩掉通道维度。换句话说,训练使得压缩网络可以合理地将同一位置的不同通道的feature map映射成一个数值。
2)在通道维度,不同的channels对前景和背景的响应程度可能不同。于是提出了:Channel-wise Attention (CA)(通道上的注意力机制)。用的是SENet的思想。
那么,这两个要怎么使用呢?与SAN-CNN一样,都是先通道后空间,这是SAN-CNN通过实验得出的结论。如下图:
第一个蓝色的运算是指对应channel的那一“片”的所有元素乘以α_c的对应位置的元素值;第二个黄色运算是指HW平面的每一个位置横跨所有的channels的那个长向量来乘以α_s对应位置的元素值。
然后提出了渐进式注意力驱动框架(a progressive attention driven framework)
该框架用来实现选择性且渐进式地集成多层特征,“渐进式”指的是该框架的输入是网络的高层feature map,在框架下面的若干注意力层有低层feature maps不断加入。如上图所标的S_5^csa,与低一点的特征图Conv4_4结合以后再一次进行注意力选择得到新的attentive 特征图S ̃_4^csa。该框架本质上是
在特征融合过程中考虑到——
1)不同level的特征的相互关系;
2)同一个level的特征不同channels之间的相互关系;
3)同一channel的在HW平面的不同位置(Spatial)的相互关系(这是由图像上的显著性区域往往只占领图像的一部分造成的)。
Multi-scale
Multi-scale是指原始图或特征图或中间显著图结果的分辨率,“图”的尺寸大小。在CNN的感受野不变情况下,放大“图”的分辨率,相当于缩小感受野大小,使得网络可以更好地关注细节信息;反之,当缩小“图”的分辨率时,相当于扩大了感受野的大小,使得网络可以更好地把握图像的全局特性。因此让网络对不同尺寸“图”进行特征提取可以同时兼顾到图像全局和局部的特征提取。
在多尺度方面,有内部网络形成的多尺度,和外部网络形成的多尺度。前者是由于卷积神经网络不断叠加“池化-卷积”操作而在不同层输出得到的不同尺度特征图。后者是通过对输入图像的尺度处理时的多尺度,获得不同尺度信息。
#213Visual saliency based on multiscale deep features:基于多尺度深度特征的视觉显著性,利用FCN产生多尺寸的feature,并将features合并成一个显著图。
#203指出一般神经网路,包括FCN模型都有下采样运算,这有利于增大网络的感受野,但是由于丢失了一些空间信息,会对像素敏感(pixel-wise)的CV任务造成精度下降的影响。即使multi-level策略在一定程度上可以缓解这一问题,但是并不能解决该问题。对此有[]提出了空洞卷积的解决方法,使得可以在扩大网络感受野的同时不损失分辨率。另外,文章采用了multi-scale的策略,将其与空洞卷积结合,设计了金字塔空洞卷神经网络(Pyramid Dilated Convolution, PDC)。大致网络结构如下图所示:
该网络重点在于多尺寸的感受野模块(multi-scale receptive field module):该网络设计了四条并行的空洞卷积分支,每条分支的空洞率不同,从而使得在相同输入特征图下,每条分支进行不同尺寸的特征提取。不仅实现了多尺寸策略还同时解决了由于下采样导致的精确下降的问题。独立卷积层组并行计算多尺寸特征图,属于multi-stream网络结构。
Multi-stage
指的是多阶段,第一个阶段进行粗略的显著图计算,后面的阶段进行精细的优化。
#199 recurrent FCN利用循环的思路,在原本的FCN网络的基础上反馈线:将网络的输出反馈到网络的输入端,并采用multi-stage的策略,将上一次计算得到显著图沿着反馈线以遮罩的形式作用到原始输入图像上,从而使得网络可以依据前一次的计算结果在下一阶段细化结果。
这种做法需要多次执行整个显著图计算流程,耗时。另外,得到的显著图直接作用在原始图像上,相当于是在原始图像上强调了显著区域,这样做,先验显著图对最终结果的影响力度可能不够大。
#222在第二细化阶段中利用[]提出的金字塔池化模块结构进行region based的特征提取并将sub-region features进行融合与全局特征(进入PPM之前的feature map)以同优化第一阶段输出的saliency map。
这里的金字塔模型用来做池化,该模块融合了4种不同金字塔尺度的特征,第一行红色是最粗糙的特征–全局池化生成单个bin输出,后面三行是不同尺度的池化特征。为了保证全局特征的权重,如果金字塔共有N个级别,则在每个级别后使用1×1的卷积将对于级别通道降为原本的1/N。再通过双线性插值获得未池化前的大小,最终concat到一起。
Dhsnet: Deep hierarchical saliency network for salient object detection
capture hierarchical saliency information from deep, coarse layers with global saliency information to shallow, fine layers with local saliency response.
其他策略
Multi-task
借助其他任务的高层特征:Multi-task(#217)和#218
【待放图细说】
Multi-feature
handcrafted feature + network generation feature[#209] 【待放图细说】
网络结构分类
用于SOD的网络模型结构可以分为四类,分别为:
图 2 6 Deep Learning Architectures of Saliency Detection Models via#205
single stream network;
只有一条数据流的单流网络
multi-stream network
同时输入多个图像的多流网络,该网络模型用相互独立的卷积层对不同的数据进行并行计算,并将多个数据流的输出合并输出。Multi-scale和multi-context策略都采用过这种网络模型。
skip-layer network.
在单流网络的基础上,取各卷积层的特征图一并送入一个卷积层中,得到输出结果,这是针对multi-level策略的一种网络结构。首次在[]中提出,后来HED在该结构的基础上添加了side-output处理,经过该处理以后的输出就是CV任务的一个结果,然后将不同程度的结构送入统一化的卷积层中做最终结果的计算。
bottom-up/top-down network
该模型可以看成是在encoder-decoder框架(一般指的是但又反卷积的FCN)中加入了skip-layer结构的模型,该模型主要用于显著物体分割(salient object segmentation)和实例分割(instance segmentation)。
小结
多级别和多尺寸信息对许多CV任务都很重要,认知科学领域也多次强调过多级别和多尺寸信息对视觉显著而言是非常重要的[#18via#203, #39#203]。#205:“It has been proved that saliency cues on different level and scales are important in saliency detection [29]. Incorporating multi-scale feature representations of neural networks into attention models is a natural choice. In the following variation of single-stream network, namely multi-stream network, the modifications are performed in this line.”
Single-stream Multi-stream Skip-layer Recurrent* Multi-scale Multi-level Multi-stage Multi-task Multi-context
#215 √ √
HED √ √
DSS √ √
PDC √ √
RFCN √ √ √
PAGRN1 √ √ √ √
PAGRN2 √** √
*:CNN网络添加了循环线就是在训练过程中的trick,可以说是多阶段策略
**:具体是attention based bottom-up/top-down
视频显著物体检测技术综述
视频显著物体检测是在图像显著物体检测的基础上加以时间维度的扩展而实现的。在2018年,基于深度学习的视频SOD仍处于起步阶段——还在努力尝试用end-to-end模型摆脱掉传统方法对人工设计特征的依赖、需要光流表征运动信息,试图用深度学习来充分挖掘出高层级的数据特征表示、替换掉耗时的光流技术。
Stage1:最开始的video SOD将静态SOD与动态SOD完全分开,假定静态SOD已完成,只研究如何将时间维度上的有用信息表示出来,并添加到静态SOD上,这就完成了动态SOD。一般都是额外地添加人工设计的特征,其中最重要的是用光流来表征运动信息。[24 via#190,9via#190]
Stage2:之后人们将视频显著性检测看成是对连续视频帧进行上下文时空信息建模的问题,在连续的几帧视频上做特征的提取、融合以及显著图的计算。一般是结合人工定义的规则结合能量函数去做空间上的平滑和时间上的时间一致性 [3 via#190,35 via#190,6 via#190]。
前两个阶段都属于无监督方式,非常依赖人工设计的低层级特征,因此,一方面由于底层特征无法充分表示数据的特征而导致计算得到得显著图不是很理想,另外由于特征和规则都是人工设计规定的,所以在面对一些复杂场景,效果不是很好。因为越复杂的场景越要求模型对数据有更加偏向语义层面上的认识require knowledge and semantic reasoning [#190]。
Stage3:当今,随着深度卷积神经网络的出现,人们开始尝试用深度学习的方法来解决时空信息的建模问题,目的是利用deep CNN一系列模型对数据高层次、全局性的特征抽象提取能力。目前基于deep CNN的方法都是监督学习方式:模型网络为了计算时空显著图,网络内部会自动地提取时空特征,将其作为时空显著检测的依据。一般思路是先进行空间域的特征提取,随后在空间特征的基础上并结合相邻若干视频帧相关数据,进一步地提取时空特征。
目前的视频显著性检测大致思路是:先做空间显著性检测,在得到了空间显著图的基础上进行时空建模并计算时空显著图。本节抛开静态显著检测,只梳理如何计算时空显著图。
视频显著性检测的难点:
缺乏大规模标注数据
如何完成从图像检测模型到视频检测模型的扩展
重要的基础网络(这样放怕是有点不高不低 不上不下的)
FlowNet
随着深度学习的发展,目前已经出现了不少具有代表性的深度学习方法来计算光流,最为典型的是FlowNet [7via#190]。
ConvLSTM
NIPS2015[尾注 ]
ConvLSTM [32], as a convolutional counterpart of conventional fully connected LSTM (FC-LSTM) [15], introduces convolution operation into input-to-state and state-to-state transitions. ConvLSTM preserves spatial information as well as modeling temporal dependency. Thus it has been well applied in many spatiotemporal pixel-level tasks, such as dynamic visual attention prediction [41], video super-resolution [12]
该模型是CNN与RNN的结合,CNN与RNN是深度神经网络的两个不同的深化方向,CNN是空间的上加深:通过不断地叠加卷积池化操作,使得网络的感受野变大,训练得到的网络可以提取更加全局化的空间特征。而RNN则是时间维度的深化,通过设计循环结构,使得网络可以对不同输入的数据进行时间上的信息累积。LSTM是目前应用最多的一种RNN变体。
ConvLSTM则是利用了CNN和RNN各自的优势,将CNN提取的空间特征如送入LSTM中进行时间维度上的累积。另外,随后还出现了Bidirectional ConvLSTM,指的是对输入的数据分别进行从前(输入时间早的)往后(输入时间晚的)的累积和从后往前的累积。大致网络结构如下:
图 2 7 via #203
国内外现状
使用光流
文章#190将FlowNet引入检测模型中,整体网络模型如下图所示。在特征提取器部分,可以兼容任意FCN网络,本文采用了DSS作为特征提取器。另外采用双向ConvLSTM来对FlowNet计算得到的光流图进行特征翘曲以及时间一致性对齐。特征翘曲操作可以补偿由于对象或相机移动造成的误差。经试验验证,该模型的处理速度可以达到5fps。
用光流表征运动信息好处在于精度高,缺点在于无论是传统的光流计算方法还是基于深度学习的计算方法,所消耗的计算量非常大,这会严重制约视频SOD的应用。
不使用光流
#189可以说是端到端模型框架的初次尝试,该篇不采用光流技术,而是将两个FCN串行拼凑起来。第一个FCN用来计算当前帧的空间显著图,后一个FCN直接基于空间显著图、当前帧数据与上一帧数据来计算当前帧的时空显著性。最终达到了2fps的处理速度。
具体采用的是带有反卷积的FCN:
但是检测效果并不是非常理想,在某些数据集下的测试结果还不如DSS。一部分原因在于时空显著图计算模型允许输入的连续视频帧长度太短。
203#同样不采用光流信息,也是先提取空间特征,在此基础上提取时空特征。在连续若干帧所对应的空间特征的基础上进一步地提取时空特征。
与190#一样,都使用了双向ConvLSTM来捕捉视频帧之间的时间信息。不同的是为了克服“池化-卷积-池化”带来的精度下降的问题,该文在以ConvLSTM为核心的基础上,也加入了空洞卷积的操作。另外,为了更好地提取时空信息,也采用了图像显著性检测的multi-scale策略。最终,同提出的PDC空间显著图计算模型一样,将multi-scale策略和空洞卷积一并考虑提出了Pyramid Dilated Bidirectional ConvLSTM (PDB-ConvLSTM)。
DB-ConvLSTM module:
图 2 8 via #203
In PDB-ConvLSTM module, two DB-ConvLSTMs with different dilate rates are adopted for capturing multi-scale information and encouraging information flow between bi-directional LSTM units.
该模型经试验测试得到的处理速度达到了20fps
常用数据集
无论是基于FP的显著性检测还是基于SOD的显著性检测,都缺少大规模的标注数据集。目前有人[#191#195]
小结
没有最好的策略,只有将几种策略组合在一起做到组合最优。
目前朝着end-to-end模型发展的deep learning based SOD正在努力舍弃从视觉注意理论基础发展起来的一些人工规定的约束,转而通过监督学习的方式,让神经网络在给定“目标”下——有标注的训练数据,自动学习特征,以输出像标注那样的结果。
视频显著物体检测与语义分割的关系
从当前deep CNN based 模型来看,两者最明显的区别在于网络的输出,前者为每一个像素判断是否显著,也即是一个二分类问题;而后者则需要判断每一个像素是否为物体以及是何种物体,是一个多分类问题。
同语义分割一样,现在的视频显著性也在做end-to-end的模型,试图将数据直接输入到神经网络这个“黑盒子”中——神经网络通过学习自动确定模型参数,从而导致人无法参与到网络模型的中间过程中,这种黑箱操作使得从对人工设计特征的依赖转到了对训练数据的依赖。因此目前有人开始研究在弱监督、半监督甚至无监督下来实现视频的语义分割。
不是说用来深度学习的方法就一定比传统的好;也不是针对视频的检测方法就一定比图像检测方法在视频数据集上表现好。
通过对比各篇论文的实验部分得到的初步结论,必要情况会自己做实验来验证
DSS(deep learning based image SOD)比DLVSD(deep learning based video SOD 189#)表现要好:
图 2 9 via#190
MD是另外一个deep learning based image SOD:
图 2 10 via #189(DLVSD)
所以直到18年的video SOD(不敢说SD)文章,都是对比图像和视频的方法放到一起对比。个人认为这又从侧面证明了目前的视频SOD正处于刚开始:还在研究从图像与视频之间衔接的问题。