前言:
这篇论文是2017年cvpr顶会的论文,该论文文笔很优美,读起来很舒服。这篇论文的作者是厦门大学的Zhiming Luo。
摘要:
作者指出:对于处理具有复杂背景的图像,传统的方法做的不好,而对于现在的深度学习方法,结构上有点过度的复杂并且处理图像的速度并不能实时。因此,作者提出了他的解决方案:提出一个基于vgg16简单的,结合4x5网格的多分辨率局部和全局特征信息的端到端的神经网络。作者并没有使用CRF或者是超像素,而是使用一个惩罚边界错误的loss项来约束空间一致性。超像素预处理和CRF后处理过程,都是比较费时间的。该方案在达到和最好的效果同等水平的同时,在推断处理的速度上也接近实时。
介绍:
典型的传统方法是提取基于像素或基于区域的局部特征,然后与全局特征对比,会得到显著图。而深度学习相对于传统的方法的好处在于,他们能够使用局部和深度特征的结合,通过简单优化函数来端到端的训练。目前针对解决显著性目标检测特制的CNN架构,在速度上还有很大的空间可以提升。
作者提出的模型是4*5网格的卷积块和反卷积块组成。网格的每一列提取特定分辨率的特征,在每一列中局部对比处理模块强化了局部特征的对比,局部特征和全局特征通过一个score处理模块组合在一起,最终输出输入图片一半分辨率大小的显著图。

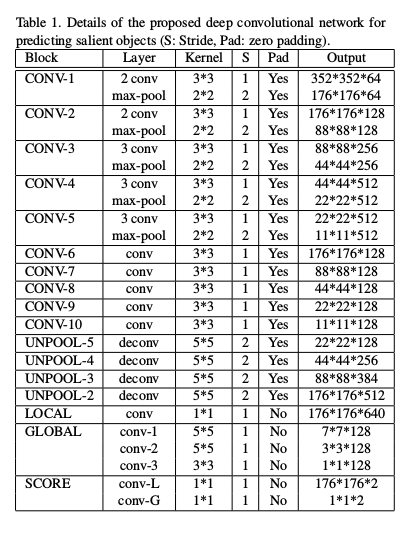
简单的网络架构流程描述:
该深度卷积网络架构是基于vgg-16的,我们知道vgg-16是有五个池化层的,而本文保留了vgg-16的前13层(即到第五个池化层),后面的三个全连接层去除。由上图可知,是分别从每一个池化层后,将池化后的特征图提取出来,分别作为该分辨率的特征图,这也就是设置五列(五种不同的分辨率特征图)的原因。这里有四行,第一行是vgg-16的前13层,第二行是分别处理五种不同的分辨率特征图的卷积层,目的是通过对来自池化层的特征图学习,得到不同分辨率(多个尺度的)特征图,第三行是为了捕获前景和背景这种差异的信息,增加了局部对比特征。第四行,是为了汇总每一列的局部特征,但由于每一列的局部特征分辨率不同,所以增加了反卷积模块,从分辨率小的局部特征(X5,X5c)从后往前传递,最后通过一个卷积层来得到最后的局部特征。在第一行的最后,通过vgg-16第五个池化层得到的特征图,通过三个卷积层来得到最后的全局特征,最后,局部特征和全局特征分别经过一个卷积层后,再相加得到最终包含局部和全局的特征。这整个网络结构就是一个特征提取器,提取了更为全面的局部和全局特征信息,然后,经过一个softmax函数得到预测的输出。
具体的流程描述:
首先,我们来确定一下输入和输出分别是什么,在本论文中,无论是训练还是测试,输入:都是将原图片空间大小(也就是分辨率h*w)直接通过cv2.resize(src,(352,352))这个方法强制转换为352*352这个分辨率大小的图片,当然通道数还是不变,然后通过reshape((1,img_size,img_size,3))函数将图片的输入格式变为(1,352,352,3),也就是常见的处理格式(batch_size,height,weight,channel)格式,这就是我们的输入啦! 输出:我们先了解真值图的类型,真值图也是经过和输入一样的方法将其变为176*176分辨率大小(通道数为1)的图片,然后,通过np.stack(label,(1-label),axis=2)的函数和np.reshape(label,[-1,2])将其真值图变为两个维度的(176*176,2)大小的ndarray类型数组,第一个维度是原本label值,第二个维度是其1-label值。要处理图片输入到该网络结构后的特征(self.Score)维度信息是(1,176,176,2),经过reshape(self.Score[-1,2])变成(176*176,2)大小的类型。好了,在搞清楚了输入和输出是什么的情况下,那么我们带着一张大小为357*357空间分辨率大小的三通道彩色图片来依次去探寻这个网络架构的每一个模块是对它进行了那些操作吧!在开始探寻之前,我们来直观的感受一下图片的样貌吧





第一个图片是最原始的输入要处理的图片(400*300),第二个是对应原始图片的真值图(400*300),第三个是将空间分辨率强制改为352*352的图片,第四个是将第三个图片的三个通道(BGR,因为cv2.imread读入的是这三个通道)分别减去VGG16_MEAN=[103.939, 116.779, 123.68]这几个平均值得到的图片,这个才是真正的输入到网络结构的图片,第五个是对应网络输出的空间分辨率为176*176的真值图。好了,有了直观的认识后,我们来开始带着图四去探寻吧!
探寻:
首先明确的一点是,输入的数据格式为[batch_size,height,weight,channel],在本论文中,batch_size设置为1,所以,输入为数据格式为[1,352,352,3],数据类型为numpy.ndarray的float64。
好了,啰嗦了大半天,开始吧!
我们以input作为输入到网络结构的图片,先看一下经过vgg16的8个卷积层和5个池化层的变化(如上图4*5结构的第一行):
vgg16的第一个模块2个卷积核大小为3*3通道数为64的步长为1的padding为SAME的卷积层(conv1-1,conv1-2)和一个2*2步长为2的,padding为SAME最大池化层(pool1),input经过conv1-1,变为了[1,352,352,64],经过conv1-2,变为[1,352,352,64],再经过pool1,变为了[1,176,176,64] (记为input_pool1)的特征图,将这个input_pool1的特征图拿出来放在第一列中处理,接下来讨论;
然后继续经过vgg16的第二个模块2个卷积核大小为3*3通道数为128的步长为1,padding为SAME的卷积层(conv2-1,conv2-2)和一个2*2步长为2的,padding为SAME的最大池化层(pool2),input_pool1经过conv2-1,变为[1,176,176,128],经过conv2-2,变为了[1,176,176,128],经过pool2,变为了[1,88,88,128](记为input_pool2)的特征图,将这个input_pool2的特征图拿出来放在第二列中处理,稍后讨论;
然后继续经过vgg16的第三个模块3个卷积核大小为3*3通道数为256的步长为1的padding为SAME的卷积层(conv3-1,conv3-2,conv3-3)和一个2*2步长为2的padding为SAME的最大池化层(pool3),input_pool2经过conv3_1,变为了[1,88,88,256],经过conv3_2,变为了[1,88,88,256],经过conv3_3,变为了[1,88,88,256],经过pool3,变为了[1,44,44,256](记为input_pool3)的特征图,将这个input_pool3的特征图拿出来放在第三列中处理,一会讨论;
然后继续经过vgg16的第四个模块3个卷积核大小为3*3通道数为512步长为1的padding为SAME卷积层(conv4-1,conv4-2,conv4-3)和一个2*2步长为2的padding为SAME的最大池化层(pool4),input_pool3经过conv4-1,变为[1,44,44,512],经过conv4-2,变为[1,44,44,512],经过conv4-3,变为[1,44,44,512],经过pool4变为[1,22,22,512](记为input_pool4)的特征图,将这个input_pool4的特征图拿出来放在第四列,下面会讨论;
然后继续经过vgg16第五个模块3个卷积核大小为3*3通道数为512步长为1的padding为SAME卷积层(conv5-1,conv5-2,conv5-3)和一个2*2步长为2的padding为SAME的最大池化层(pool5),input_pool5经过conv5-1,变为[1,22,22,512],经过conv5-2,变为[1,22,22,512],经过conv5-3,变为[1,22,22,512],经过pool5变为[1,11,11,512](记为input_pool5)的特征图,将这个input_pool5的特征图拿出来放在第五列,稍后讨论;
此时,vgg16完成了它的使命,接下来的工作都是本论文作者构建的层啦。
从pool5出来的input_pool5,经过三个卷积层(global_conv-1,global_conv-2,global_conv-3),global_conv-1,卷积核大小为5*5,通道数为128,步长为1,padding为VALID;global_conv-2,卷积核大小为5*5,通道数为128,步长为1,padding为VALID;global_conv-3,卷积核大小为3*3,通道数为128,步长为1,padding为VALID;input_pool5经过global_conv-1,变为[1,7,7,128],经过global_conv-2变为[1,3,3,128],经过global_conv-3变为[1,1,1,128],最后在经过一个分数模块(SCORE)的一个score_conv-G卷积核,这个卷积核大小为1*1,通道数为2,步长为1,padding为VALID,变为[1,1,1,2](记为input_gloal)。这个input_global就是我们的全局特征。
好了,现在开始讨论第二行:
第二行中的每一个模块都只有一个卷积层,并且这一行的每个模块卷积层的设置是一样的,即卷积核大小为3*3,通道数128,步长为1,padding为SAME(记为conv-6,conv-7,conv-8,conv-9,conv-10),input_pool1经过conv-6变为[1,176,176,128](记为X1);input_pool2经过conv-7,变为了[1,88,88,128](记为X2);input_pool3经过conv-8,变为了[1,44,44,128](记为X3);input_pool4经过conv-9,变为了[1,22,22,128](记为X4);input_pool5经过conv-10,变为了[1,11,11,128](记为X5)。
好了,现在开始讨论第三行:
这一行的模块,没有参数;它的存在是计算在每一个特定的分辨率的局部特征的前景和背景对比的信息,计算方式为: Xi - AvgPool(Xi),Xi代表第二行的每一列的输出,AvgPool(Xi)表示对Xi进行平均池化,大小为3*3,步长为1,padding为VALID,因为我们要保持AvgPool(Xi)的大小类型和Xi一致,所以,要对送入AvgPool的Xi做一个边界补值,作者在代码中,用的是tf.pad方法,模式为symmetric,将边界补了一圈,如对X1而言,补值后,大小变为[1,178,178,128];所以,Xi - AvgPool(Xi)的大小仍然和Xi大小一样,在这里记为(X1c,X2c,X3c,X4c,X5c)
到了最后一行啦:
这一行的模块是卷积层和反卷积层,在这里的反卷积层是将小的空间分辨率特征图,变为大一倍的大点的空间分辨率特征图;对与卷积而言,我们只要知道卷积的对象是什么,卷积核大小,通道数,步长和pading类型即可推出卷积后的输出,而反卷积要比卷积层需要多一个信息,就是我们的输出数据格式是什么样的,原因请百度查看。
在这一行的反卷积模块设置是一样的,即卷积核大小为5*5,步长为2,padding为SAME,通道数每一个反卷积模块不同;从第四行,第五列到第二列以此记为(unpool-5,unpool-4,unpool-3,unpool-2)。
对于unpool-5这个模块,输入为X5,X5c,X5和X5c是级联在一起,X5在上面,X5c在下面,那么输入就变为了[1,11,11,128*2],设置输出的通道数与X5保持相同,即[1,22,22,128](记为U5);
对于unpool-4这个模块,输入为X4,X4c和U5(同样是级联在一起,上到下的顺序为X4,X4c,U5),那么输入就变为[1,22,22,128*3],设置输出的通道数为与X4和U5的通道数和保持一致,即[1,44,44,128*2](记为U4);
对于unpool-3这个模块,输入为X3,X3c和U4(同样是级联在一起,上到下的顺序为X3,X3c,U4),那么输入就变为[1,44,44,128*4],设置输出的通道数为与X3和U4的通道数和保持一致,即[1,88,88,128*3](记为U3);
对于unpool-2这个模块,输入为X2,X2c和U3(同样是级联在一起,上到下的顺序为X2,X2c,U3),那么输入就变为[1,88,88,128*5],设置输出的通道数为与X2和U3的通道数和保持一致,即[1,176,176,128*4](记为U2);
好了,到这里反卷积模块就进行完了,
还剩第一行,第四列的local_conv卷积层,该卷积层的卷积核大小为1*1,通道数为128*5(X1+U2的通道数和)步长为1,padding为VALID,对于这个模块,输入是X1,X1c,U2(同样是级联在一起,上到下的顺序为X1,X1c,U2),那么输入就变成了[1,176,176,128*6],经过local_conv,变为[1,176,176,128*5](记为XL),到这里第四行就结束啦。
最后局部特征XL还要经过一个Score模块的conv-L卷积层,该卷积层大小为1*1,通道数为2,步长为1,padding为VALID,XL经过conv-L,变为[1,176,176,2](记为input_local),这个input_local就是我们的总局部特征啦!
到现在,我们得到了全局特征input_global,[1,1,1,2],和局部特征input_local,[1,176,176,2];此时,我们融合全局特征和局部特征,作者很简单的将两者加在了一起,有同学提问啦,这怎么加呀?特征的元素个数都不一致;作者代码:self.Score = self.Local_Score + self.Global_Score ,这里input_global是self.Global_Score,input_local是self.Local_Score
答:利用了python的广播机制。KO,那self.Local_Score的大小:[1,176,176,2]
最后,将self.Score做一个reshap, self.Score = tf.reshape(self.Score, [-1,2]),此时self.Score为[176*176,2],经过一个softmax(self.Score)输出self.Prob(记为prediction_out)
这里的prediction_out就是我们的这个网络的最后的输出啦!到此将整个网络结构详细的分析了一下,接下来就是loss损失函数,真的是废话一大篇,不知道您有看厌烦没?哈哈哈,皮一下
LOSS 损失函数:(我们结合一下源码来具体分析啦)
本论文中,loss损失函数由两项组成,第一项为交叉熵损失函数,第二项是边界重叠损失函数IoU Boundary Loss(借鉴医疗图像处理中常用的评价指标):
交叉熵损失函数,这个调用一个tensorflow的函数即可,
tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=self.Score,labels=self.label_holder))了;self.Score,我们刚才分析过了,是网络的输出大小为[176*176,2],self.label_holder,是真值图,大小也为[176*176,2]
tf.reduce:是求和然后平均
IoU Boundary Loss,就没有那么简单啦:

我们处理原始图片如上图,我们先对输入的数据分析一下,通过网络的输出,我们得到了prediction_out,[176*176,2],这个里的值是接近0,或者接近1的:如下的形式
array([[2.9550231e-04, 9.9970442e-01],
[3.1208037e-04, 9.9968791e-01],
[2.9506793e-04, 9.9970490e-01],
...,
[7.4689655e-05, 9.9992526e-01],
[1.0897202e-04, 9.9989104e-01],
[2.2902120e-04, 9.9977094e-01]], dtype=float32)
我将这个prediction_out,可视化了一下,使用下面几个函数
result = np.reshape(result,(l176,176,2)) : [1,176,176,2]
result = result[:,:,0] # [1,176,176]
result = np.squeeze(result) # 除去维度为1的那个维度 # [176,176]
cv2.imwrite('it_C.png',result)

通过self.Prob_C = tf.reshape(self.Prob, [1, 176, 176, 2]),这里的self.Prob_C,是我们的要处理的预测的:
我通过,cv2.imwrite('ccc1.png',(image_C[:,:,0]*255).astype(np.uint8));cv2.imwrite('ccc2.png',(image_C[:,:,1]*255).astype(np.uint8));这里的image_C就是self.Prob_C,写成图片,更为直观一点




我们对真值图,也做了形状的转换
self.label_C = tf.reshape(self.label_holder, [1, 176, 176, 2])
好了,到此,我们知道了,我们要处理的数据是什么样的啦,预测的:self.Prob_C, 真值的:self.label_C ,大小都是[1,176,176,2]
下面我们开始了解怎样对self.Prob_C和self.label_C进行边界检测的:
首先,我们需要简单的了解一下Sobel算子,它是用来检测图像边缘的,可以百度了解。
在水平方向上,Sobel算子的模板为:fx= np.array([[-1, 0, 1], [-2, 0, 2], [-1, 0, 1]]).astype(np.float32)
在垂直方向上,Sobel算子的模板为: fy = np.array([[-1, -2, -1], [0, 0, 0], [1, 2, 1]]).astype(np.float32)
因为我们要处理的self.Prob_C和self.label_C是两个图,所以:我们将 fx,和 fy分别叠加:
fx = np.stack((fx, fx), axis=2)
fy = np.stack((fy, fy), axis=2)
并转换一下形状:
fx = np.reshape(fx, (3, 3, 2, 1))
fy = np.reshape(fy, (3, 3, 2, 1))
此时,我们需要将fx,fy与self.Prob_C和self.label_C进行卷积操作,然而tenforflow很擅长这件事情(卷积操作):
所以,将fx,fy转为tf.Variable类型:
tf_fx = tf.Variable(tf.constant(fx))
tf_fy = tf.Variable(tf.constant(fy))
我们使用tensorflow提供的tf.nn.depthwise_conv2d这个方法进行卷积,在对self.Prob_C卷积之前,要进行一个tf.pad操作,扩充边界值,从[1,176,176,2] -> [1,178,178,2],以免卷积后大小改变(卷积核为tf_fx,tf_fy3*3,步长为1,multi-channel为2,padding:VALID)
通过tf.nn.depthwise_conv2d这个方法卷积后,下面这个方法
def im_gradient(self, im):
gx = tf.nn.depthwise_conv2d(tf.pad(im, [[0, 0], [1, 1], [1, 1], [0, 0]], 'SYMMETRIC'),self.sobel_fx, [1, 1, 1, 1], padding='VALID')
gy = tf.nn.depthwise_conv2d(tf.pad(im, [[0, 0], [1, 1], [1, 1], [0, 0]], 'SYMMETRIC'),self.sobel_fy, [1, 1, 1, 1], padding='VALID')
return tf.sqrt(tf.add(tf.square(gx), tf.square(gy)))
返回的数据格式为: [1,176,176,4]: 4 = 2*2 (第一个2是self.Prob_C的in_channel:2,第二个2是multi-channel,通过tf.nn.depthwise_conv2d方法,返回通道数为:in_channel*multi_channel)
通过对指定的维度reduction_indices=3,来求和,注意:keep_dims=True
self.Prob_Grad = tf.tanh(tf.reduce_sum(self.im_gradient(self.Prob_C), reduction_indices=3, keep_dims=True)) : [1,176,176,1],值在[0,1]之间
对于真值图self.label_C:
self.contour_th = 1.5 阈值,大于1.5取True,否则取False,然后再转化为1,或0
self.label_Grad = tf.cast(tf.greater(tf.reduce_sum(self.im_gradient(self.label_C),reduction_indices=3, keep_dims=True),self.contour_th), tf.float32) : [1,176,176,1] 值是1或者是0,我们来直观的感受一下哈


我们得到了self.Prob_Grad的边界图和self.label_Grad边界图,接下来算两个边界图的IOU,我们希望IOU越高越好,所以要最小化 这个项 1- IoU
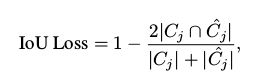
inter: 表示IoU Loss 的分子,union 表示分母;注意到tf.square(pred),对pred求其平方,对gt平方,我能理解,因为gt值1或者0,平方后,值是不变的,那对pred平方呢?
我们来思考一下,我们要的是 pred边界 和 gt边界的重合情况,|Cj|:指的是gt的边界像素点的强度之和,|Cj_hat|:指的是gt的边界像素点的强度之和,
那么,如果没有平方,pred里的像素值不仅边界对其|Cj_hat|有影响,非边界的像素点值对其也有影响,所以,引入平方后,降低非边界像素点(假如,0.001平方后,接近0)对其的影响。
self.C_IoU_LOSS = self.Loss_IoU(self.Prob_Grad, self.label_Grad)
def Loss_IoU(self, pred, gt):
inter = tf.reduce_sum(tf.multiply(pred, gt))
union = tf.add(tf.reduce_sum(tf.square(pred)), tf.reduce_sum(tf.square(gt)))
if inter == 0:
return 0
else:
return 1 - (2*(inter+1)/(union + 1))