Real-time human pose recognition in parts from single depth images 中文翻译【译】【中译】微软kinect中用的算法
Real-time human pose recognition in parts from single depth images 中文翻译
----------------贴图好麻烦,好多公式截图的,暂时没时间加进来------------
Abstract
我们给出了从单深度图像(a single depth image)中快速准确预测出人体关节3D位置的新方法,且没有使用时间信息。我们使用物体识别方法,设计了身体组件(part)的中间表示,从而将困难的姿势估计问题映射为简单些的逐像素分类问题(per-pixel classification problem)。大型、丰富多样的训练数据集保证了分类器估计身体组件时具有姿势、身材、衣着等不变性。最后,通过重投影分类器的(身体组件估计)结果,我们生成了几个人体关节的可信3D估计(proposals)。 系统在消费硬件上能以200帧每秒的速度运行。我们的评估在合成和真实测试集上都高度准确,我们同时也研究了几个训练参数的作用。与相关工作相比,我们取得了最好的准确性,并且比“确切全骨架最近邻”匹配( exact whole-skeleton nearest neighbor matching)具有更好的通用性。
1. Introduction
鲁棒互动人体跟踪的应用包括游戏、人-机交互、安全、远程呈现和健康保健等。近来由于实时深度摄像机的 引入,这个问题得到了极大的简化[16,19,44,37,28,12]。然而,即使现在的最好系统也有局限性。特别是,直到Kinect[21] (Kinect是微软在2010年6月14日对XBOX360体感周边外设正式发布的名字。)发布,还没有任何一个系统能在消费硬件上以互动速度 (interactive rates)处理正在进行各种运动(general body motions)的所有身材和体型的人体。一些系统通过帧到帧的跟踪获得了很高的速度,但苦于无法快速重新初始化因而不鲁棒。本文中,我们专注于组件的姿势识别(we focus on pose recognition in parts):从单深度图像中检测出每个骨骼关节的少量3D候选位置。我们设计了每帧初始化和恢复的技术,以作为任何适当跟踪算法[7,39,16,42,13]的补充,从而可以进一步融入时间和运动的一致性中。这里给出的算法形成了Kinect游戏平台[21]的核心组件。
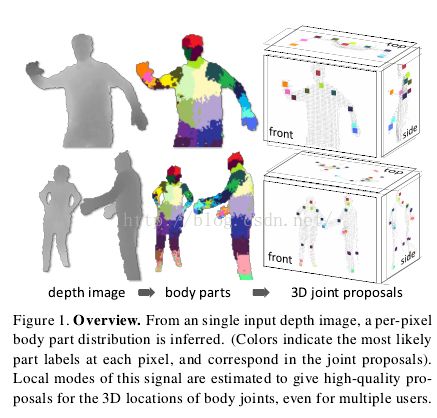
如图1所示,受近来物体识别工作将物体分成多个组件策略(如[12,43])启发,我们的方法受两个关键设计目标驱动:计算高效且鲁棒。单幅输入深度图像被分割成稠密概率身体组件标签,组件定义为与感兴趣骨骼关节空间上相近的身体部分。将推理出的组件重投影到世界空间,我们局部化每个组件分布的空间模式,从而形成每个骨骼关节3D位置的带可信权重的预测(proposals,可能有几个)。
我们将身体组件的分割(从身体分割出各组件)当作逐像素分类问题(no pairwise terms or CRF have proved necessary)。对每个像素分别评估避免了不同身体关节间的组合搜索,尽管单个身体组件在不同情形下的外观仍千差万别。我们从运动捕捉数据库中采样出不同身材和体型人物的各种姿势(人体的深度 图),然后生成逼真的合成深度图作为训练数据。我们训练出了一个深随机决策森林分类器,为避免过拟合,我们使用了数十万幅训练图像。区别式深度比较图像特征简单产生3D变换不变性的同时维持了计算的高效性。为获得更高的速度,可以使用GPU在每个像素上并行运行分类器[34]。推理出的逐像素分布的空间模式使用mean shift[10]计算,由此空间模式给出3D关节的预测。
我们算法的一个优化实现在Xbox360 GPU上能以每帧不超过5ms的速度运行(即200帧每秒),这比现有方法至少快一个数量级以上。该(算法的)实现一帧接一帧地运行,每帧中人物的身材和 体型都很不相同。学习出的区别型方法自然地处理自遮挡和从帧图像抠出的姿势(and the learned discriminative approach naturally handles self-occlusions and poses cropped by the image frame.)。我们在真实和合成深度图像上(对算法)进行了评估, 这些深度图像包含了各种人物的具有挑战性的姿势。甚至在没有使用时间或运动约束的情况下,3D关节的预测(proposals)也既精确又稳定。我们研究 了几个训练参数的作用,指出了拥有大型训练集时,多深的(决策)树仍能避免过拟合。(实验)表明在理想环境和现实环境下,我们的(身体)组件预测至少与 “确切最近邻”方法一样通用(We demonstrate that our part proposals generalize at least as well as exact nearest-neighbor in both an idealized and realistic setting),并且比现有技术水平有了实质提高。并且,在轮廓图像(silhouette images)上实验的结果表明我们的方法有更通用的应用。
我们的主要贡献是:使用新颖的身体组件中间表示将姿势估计问题变成了物体识别问题,为低计算代价和高精度从空间上定位感兴趣的关节而设计了这个中间表示。我们从实验也获得了几个启示:(i)合成深度训练数据是真实数据的极好代理(代 替品);(ii) 用各种合成数据成比例增大学习问题对(获得)高精确性很重要;和(iii)我们基于组件的方法甚至比精妙的确切最近邻方法更通用。
Related Work. 关于人类姿势的估计已经有了大量文献([22,19]中有述评)。近来引入的深度摄像机进 一步推动了研究的发展[16,19,28]。??与我们的方法最相似,Plagemann等[28]构建3D mesh(网络)来发现测地极值(geodesic extrema)兴趣点,这些兴趣点分类为3种组件:头、手和脚。他们的方法对各组件的位置和方向都进行了估计,但没区分左右,使用兴趣点也限制了组件的选择。
使用传统强度像机方面也取得了进展,尽管通常付出了更高的计算代价。Bregler和Malik[7]使用已知初始姿势的扭曲和指数地图(maps)跟踪人物。Ioffe和Forsyth[17]将平行边进行分组,并作为身体部分(segment)的候选,然后使用投影分 类器裁剪这些身体部分(候选)的组合。Mori和Malik[24]使用形状上下文描述符匹配样本。Ramanan和Forsyth[31]将身体部分的 候选当作平行线对,然后在帧间聚集外观。Shakhnarovich等[33]估计上半身姿势,通过参数敏感哈希(散列)匹配插值k-NN姿势。 Agarwal和Triggs[1]学习了一个从核化图像轮廓特征到姿势的回归(函数)。Sigal等[39]使用本征外观模板检测器估计头、上臂和小腿 (low legs)。Felzenszwalb和Huttenlocher[11]运用图画结构高效地估计姿势。Navaratnam等使用未标注数据的边际统计 提高姿势估计(的性能)。Urtasum和Darrel[41]提出使用高斯过程的局部混合来回归人物姿势。[40]使用自动上下文来获取粗糙的身体组件标签,但它不是用来定位关节的,并且给每帧分类时需要约40秒。Rogez等[32]在循环人类运动模式和摄像机角度集(torus)上定义了分类层次结构,然后基于该结构训练了随机决策森林。Wang和Popovi′c[42]跟踪了一只戴彩色手套的手。我们的系统可以视作从深度图象自动推理出虚拟彩色衣服的颜色。Bourdev和Malik[6]由3D姿势和2D图像外观的紧族(tight clusters)获取了“姿势群”,他们可以使用SVMs检测。
2. Data
姿势估计研究往往关注克服训练数据缺乏的技术[25],这是因为两个问题。第一,使用计算机图形学技术[33,27,26]生成逼真的强度图像往往受限于衣服、头发和皮肤造成的颜色和纹理的极大多变性,从而往往使生成的图像退化为2D轮廓[1]。尽管深度摄像机极大地减小了这种困难,仍然存在相当可观的身体 和服装shape变化。第二个限制是合成身体姿势图像需要以动作捕获(mocap)的数据作为输入。尽管存在模拟人类运动的技术(如[38]),却无法模 拟人类的所有自主运动。
在本节我们回顾一下深度图像,并且解释了我们如何使用真实运动捕获数据生成各种基本角色模型,从而合成一个大型且多样化的数据集。我们相信这个数据集在规模和多样性方面都超过了现有水平,且实验表明这样大型的数据集在我们的评估中有多重要。
2.1. Depth imaging
深度图像技术在过去的几年中有了极大的发展,随着Kinect[21]的发布最终成为了大众消费品。深度图像中的像素记录(indicate)了场景的校准深度,而不是场景强度或颜色的值(measure)。我们使用的Kinect摄像机每秒能捕获640×480规格图像30帧,其深度分辨率为几厘米(a few centimeters)。
深度摄像机较传统强度传感器有几个优势:工作光强水平低,提供校准后的尺度估计(giving a calibrated scale estimate),具有颜色和纹理不变性,解决了姿势的轮廓模糊问题。它们还极大简化了背景减除操作,本文我们将这一点作为前提之一。对我们的方法更重 要的是,我们可以直接合成人物的逼真深度图像,从而可以轻易的建起大型的训练数据集。
2.2. Motion capture data
人体可以做出很多姿势,这些是很难模仿的。因此,我们捕获人类运动构成一个大型运动捕获(mocap)数据库。我们的目的是包含人们在娱乐场景下所能做的所有姿势。数据库包含几百段内容为驾驶、跳舞、踢、跑、和导航菜单等的视频序列的约500k帧图像。
我们希望我们半局部的身体组件分类器多少能推广到未见过的姿势。特别的,我们并不需要记录不同肢体的所有可能组合;实际上已证实较多的各种姿势已经足够了。进一步的,我们不需要记录运动捕获(mocap)关于垂直轴的旋转变化、左右镜像、场景位置、身材和体型、或摄像机位置,所有这些都可以(半)自动添加。
因为分类器没有使用时间信息,我们关注静止的姿势而不是运动。通常,一macap帧到下一帧之间的姿势变化小得可以忽略。因此,我们使用“最远邻 (furthest neighbor)”聚集[15]从初始mocap数据中除去大量相似、冗余的姿势,“最远邻”聚集将姿势p1和p2之间的距离定义为,即身体关节j的最大欧氏距离。我们使用100k姿势的子集以确保任何两个姿势之间的距离不小于5cm。
为了使用尚未发现的姿势空间区域提炼(refine)mocap(运动捕获)数据库,我们发现必须迭代执行包括运动捕获、从我们的模型采样、训练分类器和测 试关节预测准确性的过程。我们早期的实验使用了CMU运动捕获数据库[9]。尽管覆盖的姿势空间远远不够,它还是给出了可接受的结果。
2.3. Generating synthetic data
我们建立了一个随机渲染管道,从中我们可以对全标注训练图像集采样。我们建立该管道有两个目的:真实性和多样性。为使训练出的模型良好工作,采样必须与真实摄像机图像十分相似,并且良好覆盖我们在测试时希望识别的外观多样性。我们的特征对深度/尺度和平移变化都进行了显式处理(见下述),但是其它不变性没能有效编码。因此,我们从(训练)数据学习摄像机、姿势、体型和身材的不变性。
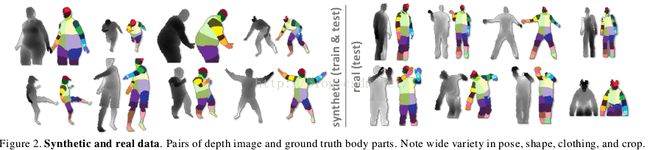
合成管道首 先随机采样一组参数,然后使用标准计算机图形学技术从纹理映射3D网络渲染深度和(见下述)身体组件图像。使用[4],运动捕获重新指向覆盖身材和体型的 15个基础网格。(The mocap is retargetting to each of 15 base meshes spanning the range of body shapes and sizes, using [4].)在身高和体重上使用的进一步轻微随机变化覆盖了额外的身材可变性。其它随机参数包括mocap帧、摄像机姿势、摄像机噪声、服装和发型。在补充材料中我们给出了这些变化的更多细节。图2比较了管道的各种输出与手工标注的摄像机图像。
3. Body Part Inference and Joint Proposals
在本节给出我们的身体组件中间表示、描述区别式深度图像特征、回顾决策森林及其在身体组件识别中的应用,最后讨论怎样使用一个模式(mode)发现算法生成关节位置的估计(proposals)。
3.1. Body part labeling
本文的一个主要贡献是我们的身体组件中间表示。我们定义了稠密覆盖身体的几个局部身体组件标签,如图2的颜色编码。一些组件定义是用来直接定位感兴趣的特定 骨架关节的,其他的是用来填补身体空白或者通过组合来预测其他关节的。我们的中间表示将问题转化成一个能很容易使用高效分类算法解决的问题。在4.3节我们证明了这种转换的惩罚代价很小。
组件在纹理映射中描述,纹理映射融合了渲染时的各种特征(The parts are specified in a texture map that is retargeted to skin the various characters during rendering.)。深度和身体组件图像 对作为全标注数据来训练分类器(见下述)。本文中的实验使用了31个人体组件:LU/RU/LW/RW头,颈,L/R肩,LU/RU/LW/RW 手臂, L/R肘, L/R腕, L/R手, LU/RU/LW/RW 躯干, LU/RU/LW/RW 腿, L/R 膝, L/R 踝, L/R脚 (Left, Right, Upper, loWer)。明确左右组件使分类器可以区分身体的左右侧。
当然,为适用特定的应用,这些组件的精确定义可以修改。如在上半身跟踪场景中,所有下半身的组件都可以去掉。组件应该充分小以准确定位身体关节,但是也不能太多以免浪费分类器的能力。
3.2. Depth image features
受[20]中使用特征启发,我们使用简单的深度比较特征。对于给定的像素x,特征计算如下: 其中dI(x)是图像I在像素x处的深度,参数描述了偏移u和v。使用规范化偏移保证了特征是深度不变的:对身体的一个给定点,无论它离摄像机近还是远,(特征计算)都会给出一个固定的世界空间偏移。特征因此也是3D变换不变的(modulo perspective effects,模型的视角影响,)。对背景中或图像边界之外的偏移像素,深度探针将给出一个大的正常数。
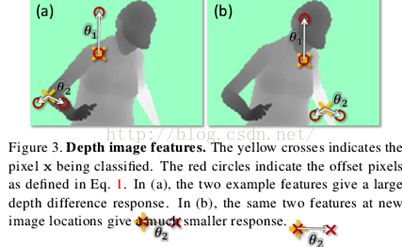
图3图示了不同像素位置x的两个特征。特征(见式1)对接近身体顶部位置的像素x会有较大正响应,但对较低身体位置处像素点的响应则接近0。特征将有助于发现细竖直结构,如手臂。
任意单个这样的特征都只能提供关于像素属于身体哪个组件的微弱信号,但是在决策森林中组合起来后,他们就足以准确区分所有训练组件。设计这些特征充分考虑到了计算效率:不需要预处理;(计算)每个特征最多只需要读取3个图像像素和执行5个算术运算;特征(计算)可以直接使用GPU实现。如果采用更大的计算代价,则可以采用潜在的性能更强的基于诸如区域深度积分、曲率的特征,或者使用局部描述符,如[5]中所采用的。
3.3. Randomized decision forests
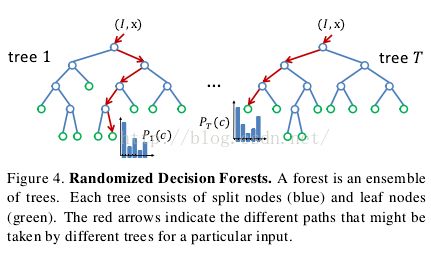
随机决策树和森林[35,;30,2,8]被证实是对于很多任务的快速有效多类分类器[20,23,;36],且可以在GPU[34]上高效;实现;如图4所示,森林是T 棵决策树的总体,每棵树都有分支节点和叶子节;点;征和一个阈值T组成;图像I的像素x进行分类时,从根节点开始不断计算 公式1得到特征值,然后根据(特征值)与阈值T的比较结果往左或者往右分支。树t的叶子节点存储了身体组件标签c的训练出的分布。对所有树的分布求平均值并作为最终的分类:
Training.每棵树都在一个不同的随机的合成样本库上训练得到。从每幅图像中随机选择2000个样本像素构成大致在各身体组件上均匀分布的随机子集。每棵树都使用下面的算法训练[20]:
1. 随机给出一组(a set of)分支候选(特征参数和阈值),
2. 使用每个将样本集分成左子集和右子集,
3. 通过求解最大信息增益问题确定:
其中香农熵(Shannonentropy)在所有的身体组件标签的规范化直方图上进行计算
4. 如果最大增益仍然很大(足够大),并且树的深度没有达到最大值,则在左右子集和中继续递归。
为降低训练时间,我们采用了分布式实现。在1000个核的集群上从1百万幅图像中将3棵树训练到20层花了大约1天。
3.4. Joint position proposals
前述身体组件识别推理出逐像素信息。现在需要将所有像素的这些信息汇聚起来形成3D骨架关节位置的可靠预测。这些预测是我们算法的最终输出,可以在跟踪算法中进行自初始化和从失败中恢复。
一个简单的选择是使用知名的校准深度为每个组件累加概率(分布)团的全局3D中心。然而,无关像素会严重降低这样一个全局估计的质量。因此,我们采用了基于带权高斯核均值转移(mean shift)[10]的局部模式发现方法。
我们定义了如下的(逐个)身体组件的密度估计量:
其中是3D世界空间中的坐标,N是图像像素数量,是像素权重,是图像像素xi到世界空间的重新投影,给定深度。bc是训练出的每个组件的宽度。像素权重同时考虑了在像素上推理出的(属于哪个身体组件的)概率和像素在世界空间中的表面积:
这保证了密度估计是深度不变的,而且使关节预测的准确性有了一个虽小却意义重大的提高。根据身体组件定义不同,可以通过在少数组件集合中预累加得到后验概率P(c|I,x)。例如,在我们的实验中,可以融合覆盖头的四个身体组件来定位头关节。
使 用mean shift在这个概率密度(估计)中高效发现模式。对于组件c,我们训练出一个概率阈值,所有概率高于该阈值的像素都作为(mean shift)的起始点。当像素权重之和达到每个模式(mode)时就得到了最终的可信估计。这被证明比采用模态密度估计更可靠。
检测出的模式(实际上)位于身体的表面。因此,使用训练出的z偏移将每个模式还原到现场(即身体表面)从而产生最后的关节位置预测。这个简单高效的方法在实践中工作得很好。宽度bc,概率阈值,和表面-to-内部的z偏移都在一个保留的5000幅图像的验证集中使用网格搜索(grid search)优化。(As an indication, 得到的平均宽度为0.065m,概率阈值为0.14,z偏移为0.039m。)
4. Experiments
本节描述评估我们方法性能所进行的实验。我们给出了在几个具有挑战性的数据集上的定性和定量结果,并与最近邻方法和当前最高水准[13]进行了比较。在补充 材料中我们给出了进一步的结果。除非特别指明,以下的参数都是如下都是这样设置的:3棵树,20层深,每棵树使用300k幅训练图像,每幅图像2000个 训练样本像素,2000个候选特征θ,每个特征50个候选阈值τ。
Test Data。我们使用具有挑战性的合成和真实深度图像评估我们的方法。对于我们的合成测试集,我们合成了5000幅深度图像,并带有了真实的身体标签和关节位置。用来产生这些合成图象的原始mocap姿势(图像)从训练数据中剔了出来。我们的真实测试集包含 15个不同人物(subjects)的8088帧真实深度图像,手工标注了稠密身体组件和7个上半身人体关节位置。我们也在[13]中的真实深度数据上进 行了测试。结果表明在合成数据上出现的效果(effects)可以镜像到真实数据上;进一步的,因为在姿势和体型上的极端变化,到目前为止我们的合成测试 数据集是最难的。因为在主要的娱乐场景中用户都是面向摄像机(0°)的,在绝大多数实验中我们将用户的旋转角度限制在±120°,尽管我们也评估了全 360°的情形。
误差度量(Error metrics)。我们同时量化了分类和关节预测精度。我们给出了每类的平均精度,即,真实组件标签与最可能推理组件标签之间模糊矩阵 (confusion matrix)的对角线(diagonal,都不知道具体指什么)。虽然大小不同,该度量却同等地衡量每个身体组件,尽管对组件边界的误标注降低了绝对数量。我们给出了以置信度阈值为自变量的关节估计的recall-precision(测全率-测准率,再现率-精度)曲线。我们量化了每个关节(预测)的 平均精度,或者全部关节(预测)的平均的平均精度(mean Average Precision,mAP)。离真实位置D厘米内的第一个关节预测会当作真正(true positive),而其他也在D厘米之内的预测则会当作假正(false positive)。这是惩罚正确位置附近的多个虚假预测,因为它们会使downstream跟踪算法变慢。所有D厘米之外的关节(预测)也视作假正。注 意所有预测(不知是最可信的)都计算到度量中去。在图像中不可见的关节不会当作假负。下面我们设置D=0.1m,approximately the accuracy of the hand-labeled real test data ground truth.(冒出这么一句,都不知道什么意思啊)。分类(classification)与关节预测准确性之间的强相关性(参见图6(a)和图8(a) 中的蓝色曲线)表明下面从观察所得的针对某一个的趋势对另一个同样适用。

4.1. Qualitative results
图5给出了我们算法的一些例子推理。请注意,在很大的身体和摄像机姿势、景深、cropping(裁剪)、身材和体型(如瘦小的小孩和壮硕的成年人)变化范围 上都有很高的分类和关节预测准确性。底部一列给出了身体组件分类失败的一些形式(modes)。第一个例子是没能区分出深度图像中的细微变化,像交叉的手 臂。常常(就象第二和第三个失败的例子)最可能的身体组件是不正确的,但是在分布P(c|I,x)中还是有足够多的正确概率团可以生成准确的(关节)预 测。第四个是没能很好推广到未见过的姿势的例子。但是(设置好的)置信度防止了(gates)很差预测的出现,以再现率(recall, 测全率)的损失为代价维持了高的精确性。
注意我们没有使用任何时间或运动约束。尽管如此,补充材料中视频序列每帧图像的结果表明几乎每个关节都被准确预测,且抖动惊人的小。
4.2. Classification accuracy
我们研究了几个训练参数对分类准确性的影响。在合成测试集和真实测试集上的趋势高度相关,并且真实测试集一致地显得比合成测试集更“容易”,也是是因为其中的姿势变化少些。
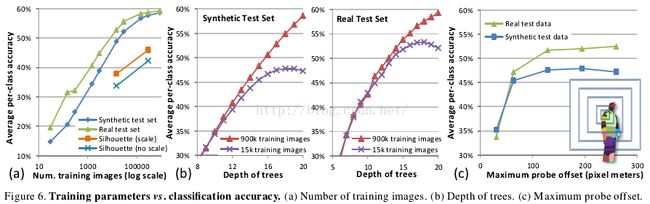
Number of training images.训练图像数量。在图6(a)中,我们展示了准确性大约与随机生成图像数量之间呈对数关系,尽管训练图像增加到大约100k幅时准确性开始停止提高。下面就会展示,这种饱和很可能是3棵20层决策树构成的森林本身模型能力有限所致。
Silhouette images.轮廓图像。图6(a)也给出了我们的方法在合成轮廓图像上表现出来的品质。在合成轮廓图像中,式1所计算出来的特征可以是带尺度(以平均深度度量)的、也可 以是不带尺度的(固定深度)。设定10像素真正(true positive)阈值,采用2D衡量标准,对应的预测准确性分别是:有尺度的为0.539mAP,不带尺度的为0.465mAP。尽管深度模糊明显使预 测更艰难,这些结果仍表明了我们方法对其他图像形态(other imaging modalities)也有较好的适用性。
Depth of trees.树的深度。使 用15k和900k幅图像,图6(b)展示了树深度对测试准确性的影响。在所有训练参数中,深度似乎具有最显著的作用,因为它直接影响着分类器的建模能 力。只使用15k幅训练图像时在17层左右就出现了过拟合,将训练集增多到900k则避免了过拟合。精度在20层处的较高梯度表明训练更多层能得到更好的 结果,当然有附加的较小的计算代价加上较大的额外存储代价。从实用方面看,感兴趣的是,直到大约10层,训练集的大小关系不大,这告诉了我们一个高效训练策略。
Depth of trees.最大探针偏移。训练时允许的深度探针偏移范围对准确性有很大影响。图6(c)给出了在5k幅训练图像上的比较结果。这里,最大探针偏 移(‘maximum probe offset’)指式1中u和v允许赋予的x和y坐标的最大绝对值。图中右侧的同心盒子是5个测试的最大偏移集,使用图像中左肩处的像素对它们进行了较 准;最大的偏移几乎覆盖了整个身体。(记得最大偏移随像素的世界深度变化而缩放)。随着最大探针偏移增加,分类器可以使用更多空间上下文来做决定,尽管训 练数据不够最终会导致过拟合。精度随最大探针偏移增大而提高,尽管在约129像素大小处就不再增大。

4.3. Joint prediction accuracy
图7给出了在合成测试集上的平均精度,达0.731mAP。我们对比了理想化的配置——即给出了真实身体组件标签的情况和使用推理出的身体组件的真实配置情况。我们确实付出了小小的代价来适用身体组件的中间表示,但是很多关节的推理结果有很高的准确性并且接近(理论上的)上界。在真实测试集上,我们有头、肩、肘和手的真实标签。在这些真实组件上mAP达0.984,而在推理出的身体组件上的mAP也达到了0.914。正如预期一样,在这个较易的测试集上,这些数据理所当然较高。

Comparison with nearest neighbor.与最近邻(方法)比较。为说明以组件方式识别姿势是需要的,并且使读者了解(calibrate)我们测试集的难度,在图8(a)中我们与“确切最近邻全身匹配方法”的两个变种进行了比较。首先,作为理想情况,将“真实测试骨架(ground truth test skeleton)”与使用优化刚性变换对齐到3D世界空间(optimal rigid translational alignment in 3D world space)的训练样本骨架进行比较。当然,在实际操作(即姿势估计)中是无法得到(真实)测试骨架的。作为可实现系统的例子,其次我们使用 chamfer匹配[14]对比测试图像与训练样本。Chamfer匹配需计算深度边(depth edges)和12个方向量化值(bins)。为使chamfer匹配容易些。我们随时去掉已处理的(cropped)训练和测试图像。我们使用团 (mass)的3D中心对齐图像,且发现进一步的局部刚性变换只会降低准确性。
我们采用组件识别的算法,直到150k幅训练图像的规模,都比理想骨架匹配方法扩展性更好(generalizes better)。正如上文提到的,我们使用更深的树能获得更好的结果,但是,(仅使用20层深度的树)我们已经能鲁棒地推理出身体关节位置和自然地处理 cropping和变换。最近邻chamfer匹配方法比我们算法的速度要慢得多(2fps)。层次匹配[14]确实快些,但是它需要大规模样本集来达到 相当的准确性。
Comparison with [13].与[13]比较。[13]的作者提供的数据和结果可直接比较。他们的算法使用[28]给出的身体组件预测,然后利用运动和时 间信息跟踪骨架。他们的数据来自于飞行时间(time-of-flight)深度像机,该像机具有跟我们的结构光线传感器(structured light sensor)完全不同的噪声统计特性。没对我们的训练数据和算法作任何改变,图8(b)显示出了在关节预测准确性上有可观的提高,且我们的算法快10倍以上。
Full rotations and multiple people. 全旋转和多人情况。为评估360o旋转场景,我们在900k幅包含全旋转的图像上训练了一个森林,并在5k幅合成全旋转图像 (with held out poses)上进行了测试。尽管有极大的左-右模糊,我们的系统还是获得了0.655mAP,这表明我们的分类器能准确学习到区分正面背面姿势的细微视觉 线索。分类后的残余左-右不确定性可以通过多重假设自然传播给跟踪算法。因为逐像素分类器适用性强,就算没有在训练时包含多人的情况,我们的方法仍然能在 包含多人的图像中预测出关节的位置。结果见图1和补充材料。
Faster proposals. 快速预测。基于简单的自底向上聚类,我们实现了一个更快生成预测的替代方法。与 身体组件分类器联合,该方法在Xbox GPU上的速度为~200fps,在8核的当前桌面CPU上使用mean shift时的速度为~50fps。节省了计算量的情况下,尽管使用mean shift方法为0.731mAP,该方法在合成测试集上也取得了可比的0.677mAP(Given the computational savings, the 0.677 mAP achieved on the synthetic test set compares favorably to the 0.731 mAP of the mean shift approach.)。
5. Discussion
我们已经知道,从单深度图像超实时给出身体关节的3D位置有多大的准确性。我们引入身体组件识别作为人姿势估计的中间表示。使用了一个高度多样性的合成训练集从而能训练出很深的决策森林而不会过拟合,并学习出了姿势和;对于未来的工作,我们计划进一步研究源mocap 数;
练出很深的决策森林而不会过拟合,并学习出了姿势和身材的不变 性。通过在(概率)密度(函数)中检测模式(mode)给出最终的带可信权重的3D关节预测集。实验结果显示了真实数据和合成数据之间、中间分类和最后的 关节预测精度之间都存在很高的相关性。我们突出表明了将整体骨架分解成不同部件的重要性,并在具有竞争力的测试集上得到了最好的精度。
对于未来的工作,我们计划进一步研究源mocap数据的不变性,合成管道中潜在生成模式(the generative Model)的特性,以及特定组件的定义。是否存在一个具有相当效率的直接回归出关节位置的方法尚不得而知。也许隐变量的一个全局估计比如人的粗略方向能 用来约束身体组件推理和消除局部姿势估计的模糊性。
Acknowledgements. We thank the many skilled engineers in Xbox, particularly Robert Craig, Matt Bronder, Craig Peeper, Momin Al-Ghosien, and Ryan Geiss, who built the Kinect tracking system on top of this research. We also thank John Winn, Duncan Robertson, Antonio Criminisi, Shahram Izadi, Ollie Williams, and Mihai Budiu for help and valuable discussions, and Varun Ganapathi and Christian Plagemann for providing their test data.
References
[1] A. Agarwal and B. Triggs. 3D human pose from silhouettes by relevance vector regression. In Proc. CVPR, 2004. 2
[2] Y. Amit and D. Geman. Shape quantization and recognition with randomized trees. Neural Computation, 9(7):1545–1588, 1997. 4
[3] D. Anguelov, B. Taskar, V. Chatalbashev, D. Koller, D. Gupta, and A. Ng. Discriminative learning of markov random fields for segmentation of 3D scan data. In Proc. CVPR, 2005. 2
[4] Autodesk MotionBuilder. 3
[5] S. Belongie, J. Malik, and J. Puzicha. Shape matching and object recognition using shape contexts. IEEE Trans. PAMI, 24, 2002. 4
[6] L. Bourdev and J. Malik. Poselets: Body part detectors trained using 3D human pose annotations. In Proc. ICCV, 2009. 2
[7] C. Bregler and J. Malik. Tracking people with twists and exponential maps. In Proc. CVPR, 1998. 1, 2
[8] L. Breiman. Random forests. Mach. Learning, 45(1):5–32, 2001. 4
[9] CMU Mocap Database. http://mocap.cs.cmu.edu/. 3
[10] D. Comaniciu and P. Meer. Mean shift: A robust approach toward feature space analysis. IEEE Trans. PAMI, 24(5), 2002. 1, 5
[11] P. Felzenszwalb and D. Huttenlocher. Pictorial structures for object recognition. IJCV, 61(1):55–79, Jan. 2005. 2
[12] R. Fergus, P. Perona, and A. Zisserman. Object class recognition by unsupervised
scale-invariant learning. In Proc. CVPR, 2003. 1
[13] V. Ganapathi, C. Plagemann, D. Koller, and S. Thrun. Real time motion capture using a single time-of-flight camera. In Proc. CVPR, 2010. 1, 5, 7, 8
[14] D. Gavrila. Pedestrian detection from a moving vehicle. In Proc. ECCV, June 2000. 7
[15] T. Gonzalez. Clustering to minimize the maximum intercluster distance. Theor. Comp. Sci., 38, 1985. 3
[16] D. Grest, J. Woetzel, and R. Koch. Nonlinear body pose estimation from depth images. In In Proc. DAGM, 2005. 1, 2
[17] S. Ioffe and D. Forsyth. Probabilistic methods for finding people. IJCV, 43(1):45–68, 2001. 2
[18] E. Kalogerakis, A. Hertzmann, and K. Singh. Learning 3D mesh segmentation and labeling.
ACM Trans. Graphics, 29(3), 2010. 2
[19] S. Knoop, S. Vacek, and R. Dillmann. Sensor fusion for 3D human body tracking with an articulated 3D body model. In Proc. ICRA, 2006. 1, 2
[20] V. Lepetit, P. Lagger, and P. Fua. Randomized trees for real-time keypoint recognition. In Proc. CVPR, pages 2:775–781, 2005. 4
[21] Microsoft Corp. Redmond WA. Kinect for Xbox 360. 1, 2
[22] T. Moeslund, A. Hilton, and V. Kr¨uger. A survey of advances in vision-based human motion capture and analysis. CVIU, 2006. 2
[23] F. Moosmann, B. Triggs, and F. Jurie. Fast discriminative visual codebooks using randomized clustering forests. In NIPS, 2006. 4
[24] G. Mori and J. Malik. Estimating human body configurations using shape context matching. In Proc. ICCV, 2003. 2
[25] R. Navaratnam, A.W. Fitzgibbon, and R. Cipolla. The joint manifold model for
semi-supervised multi-valued regression. In Proc. ICCV, 2007. 2
[26] H. Ning, W. Xu, Y. Gong, and T. S. Huang. Discriminative learning of visual words for 3D human pose estimation. In Proc. CVPR, 2008. 2
[27] R. Okada and S. Soatto. Relevant feature selection for human pose estimation and
localization in cluttered images. In Proc. ECCV, 2008. 2
[28] C. Plagemann, V. Ganapathi, D. Koller, and S. Thrun. Real-time identification and localization of body parts from depth images. In Proc. ICRA, 2010. 1, 2, 7
[29] R. Poppe. Vision-based human motion analysis: An overview. CVIU, 108, 2007. 2
[30] J. R. Quinlan. Induction of decision trees. Mach. Learn, 1986. 4
[31] D. Ramanan and D. Forsyth. Finding and tracking people from the bottom up. In Proc. CVPR, 2003. 2
[32] G. Rogez, J. Rihan, S. Ramalingam, C. Orrite, and P. Torr. Randomized trees for human pose detection. In Proc. CVPR, 2008. 2
[33] G. Shakhnarovich, P. Viola, and T. Darrell. Fast pose estimation with parameter sensitive hashing. In Proc. ICCV, 2003. 2
[34] T. Sharp. Implementing decision trees and forests on a GPU. In Proc. ECCV, 2008. 1, 4
[35] B. Shepherd. An appraisal of a decision tree approach to image classification. In IJCAI, 1983. 4
[36] J. Shotton, M. Johnson, and R. Cipolla. Semantic texton forests for image categorization and segmentation. In Proc. CVPR, 2008. 4
[37] M. Siddiqui and G. Medioni. Human pose estimation from a single view point, real-time range sensor. In CVCG at CVPR, 2010. 1, 2
[38] H. Sidenbladh, M. Black, and L. Sigal. Implicit probabilistic models of human motion for synthesis and tracking. In ECCV, 2002. 2
[39] L. Sigal, S. Bhatia, S. Roth, M. Black, and M. Isard. Tracking looselimbed people. In Proc. CVPR, 2004. 1, 2
[40] Z. Tu. Auto-context and its application to high-level vision tasks. In Proc. CVPR, 2008. 2
[41] R. Urtasun and T. Darrell. Local probabilistic regression for activityindependent human pose inference. In Proc. CVPR, 2008. 2
[42] R.Wang and J. Popovi′c. Real-time hand-tracking with a color glove. In Proc. ACM SIGGRAPH, 2009. 1, 2
(参考 http://3y.uu456.com/bp-dbf7c3edaeaad1f346q33f22-1.html 整理的 )