【阅读笔记】Reasoning With Neural Tensor Networks for Knowledge Base Completion
前言
论文地址
Poster
Abstract
这篇论文里,作者介绍了一个适用于推理两个实体关系的神经网络(Neural Tensor Network).相比之前的工作要么将实体表示成离散的最小单元或者是单个的实体向量,而这篇论文实验表明当实体被表现成他们词向量的平均值时实验的效果会提升。最后,论文证明当这些词向量通过大量非监督学习的语料学习结果作为参数的初始化值,对于预测知识库里两个实体是否有关系的评估结果有明显的提升。总之论文里模型结果优于以前模型,并且在判断WordNet和FreeBase里隐藏的关系准确率有86.2%和90.0%。
Introduce
例如WordNet,Yago,Google Knowledge Graph等类似的实体和知识库提供了丰富的资源去…提供信息检索和知识结构给用户,但是仍然面临着关系不完整和缺乏知识推理能力的问题。
… (省略不重要介绍)
作者提供一个可以准确的预测现有知识库里额外的真实信息的模型。模型主要通过将一个在知识库里的实体表现成一个向量,同时向量的形式也可以表现出自身信息和与其他实体的关系,而每一对实体的关系通过一个新定义的神经张量网络的参数来准确表达。
总之,该论文第一个贡献是提出了一个新的神经网络neural tensor network(NTN),它综合了几个以前的神经网络模型并提出一个强于标准神经网络层的更有力去模型化信息之间的关系的方法。
第二个贡献是提供了一个全新的方式去展现知识库里的实体,之前类似8,9,10他们只是把实体表现成一个变量,然而如果实体的名称有相同的子串则不能 sharing statistical strength。
第三个贡献是将大量未标记的文本以词向量嵌入形式并入训练。
Related Work
直接看论文就好!
Neural Models for Reasoning over Relations
神经网络结构
网络的结构采用一个双线性模型(bilinear models):
g ( e 1 , R , e 2 ) = u R T f ( e 1 T W R [ 1 : k ] e 2 + V R [ e 1 e 2 ] + b R ) ( 1 ) g(e_1,R,e_2)=u^T_Rf(e_1^TW_R^{[1:k]}e_2+V_R\begin{bmatrix} e_1 \\ e_2 \\ \end{bmatrix}+b_R)~~~~~~~~~~~~~(1) g(e1,R,e2)=uRTf(e1TWR[1:k]e2+VR[e1e2]+bR) (1)
其中g为网络的输出,表示对该关系R的打分。e1,e2为两个实体的特征向量,维度都为d,初始化可以是随机值,也可以是通过第三方工具训练后的向量,在训练中还需不断调整。 f= tanh是隐藏层的激活函数。
第一层权重为V,偏置为b,第二层权重为u右括号第一项为Tensor项。
论文中给出的对应图示为:

损失函数的思想:
利用这个网络可以进行知识库推理学习,对于每一个给定三元关系 (e_i,R_k,e_j) ,随机用别的实体替换掉实体e1或者e2构造一个新的负样本,对于构造负样本得分倾向于比正样本要小,并且正样本得分趋近于1,负样本得分趋近于0.于是使用最大化边际函数(max-margin objective functions)的形式具体如下所示:
J ( Ω ) = ∑ i = 1 N ∑ c = 1 C m a x ( 0 , 1 − g ( T ( i ) ) + g ( T c ( i ) ) ) + λ ∣ ∣ Ω ∣ ∣ 2 2 ( 2 ) J(\Omega)=\sum^N_{i=1}\sum^C_{c=1}max(0,1-g(T^{(i)})+g(T_c^{(i)}))+\lambda ||\Omega||^2_2~~~~~~~~~~~~~(2) J(Ω)=i=1∑Nc=1∑Cmax(0,1−g(T(i))+g(Tc(i)))+λ∣∣Ω∣∣22 (2)
最后我们需要朝着最小化这个损失函数进行优化,表达式里N是所有正例样本数,对于每一个正例样本随机构造C个负例样本。其中Ω是所有参数的集合u,W,V,b,E。第1,3,4是一般的bp网络的权重参数,最后一个是实体的特征向量,是输入,第二个是张量。T^{(i)}_c 是第i个样本对应的负例。
然后论文使用梯度下降或者L-BFGS求解使损失函数最小化的参数,训练出来的一个参数集对应一个关系。
重新审视词向量
作者介绍了两种关于随机初始化实体向量时提高模型准确率的方法:
-
由多个单词复合构成的实体向量初始化化用多个词向量的平均值构成 (Word vector)
作者同时也尝试用RNN学习复合词构成的实体的向量,但是由于某些原因实际效果并不好,不如直接取词向量的平均值。
-
先用无监督学习预训练出实体的向量去初始化实体里的词向量 (WV-init)
参考word representations: a simple and general method for semi-supervised learning论文
Experiments
本论文选取WordNet和FreeBase两个样本集去预测新的关系。
在WordNet使用112581条三元组关系 (e_1,R,e_2) 去训练,这些三元组来自38696个不同实体和11个不同类型的关系。与前任工作不同,作者过滤掉了一些关系,比如在WordNet三元关系里重复出现相同的实体的关系等
Relation Triplets Classification 三元组关系的判断
本论文通过替换正样例中实体生成负样例,通过设置门槛 T R T_R TR ,判断关系是否存在。
g ( e 1 , R , e 2 ) > = T R g(e_1,R,e_2) >= T_R g(e1,R,e2)>=TR
在测试三元组关系是否存在的任务上对比了文中提到五种不同模型准确率,发现本论文提出NTN模型大幅度优于其他的模型。

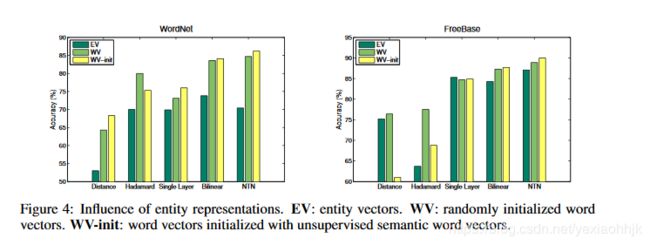
同时作者对比了在WordNet和Freebase里不同关系在同一个数据集上的准确率,结论如图所示,不同关系准确率不一样:

同时作者发现,实体向量初始化的方式的不同对准确率有很大影响,对比三种实体向量不同的初始化方式:
- EV:(Entity Vector) : 整个实体作为一个单独向量表示
- WV(Word Vector) : 词向量是随机初始化得到,然后用词向量的平均值表示实体向量
- WV-init : 相比WV词向量时初始化是用无监督学习得到
Examples of Reasoning
上面判断三元关系准确性的任务里,已经证明本轮文模型对于预测一个三元关系是否存在有较高准确率。
作者在这一块用了两个实验主观的展示TNT的推理能力:
- 选择一个实体和关系,然后将其他所有实体与这个实体关系打分值降序排列,如下表

从这个表看出,主观看出,其中大多数推断的关系都是可信的。
- 通过knowledge base已有训练过的三元关系,去推理实体间未知的关系,举例如下:

如图通过黑线已有的关系,推理出红线未知的关系,并且用词向量(word vector)表示实体向量(entity vector)后,相同的词语组成的实体的潜在语义关系也得以保存。
总结:
这篇论文主要创新点是,相比前人在知识库里使用实体去预测关系,作者引入了一个损失函数为双线性的三层神经网络(NTN)模型,并且对于实体向量初始化的处理采用非监督模型训练得到的词向量的平均值,大大提高了系统准确率。
阅读后思考:
- 用这个神经网络训练进行三元组关系推理时候的阈值 T R T_R TR是怎么确定的?