【李宏毅机器学习笔记】 12、Unsupervised Learning - Linear Methods
【李宏毅机器学习笔记】1、回归问题(Regression)
【李宏毅机器学习笔记】2、error产生自哪里?
【李宏毅机器学习笔记】3、gradient descent
【李宏毅机器学习笔记】4、Classification
【李宏毅机器学习笔记】5、Logistic Regression
【李宏毅机器学习笔记】6、简短介绍Deep Learning
【李宏毅机器学习笔记】7、反向传播(Backpropagation)
【李宏毅机器学习笔记】8、Tips for Training DNN
【李宏毅机器学习笔记】9、Convolutional Neural Network(CNN)
【李宏毅机器学习笔记】10、Why deep?(待填坑)
【李宏毅机器学习笔记】11、 Semi-supervised
【李宏毅机器学习笔记】 12、Unsupervised Learning - Linear Methods
【李宏毅机器学习笔记】 13、Unsupervised Learning - Word Embedding(待填坑)
【李宏毅机器学习笔记】 14、Unsupervised Learning - Neighbor Embedding(待填坑)
【李宏毅机器学习笔记】 15、Unsupervised Learning - Auto-encoder(待填坑)
【李宏毅机器学习笔记】 16、Unsupervised Learning - Deep Generative Model(待填坑)
【李宏毅机器学习笔记】 17、迁移学习(Transfer Learning)
【李宏毅机器学习笔记】 18、支持向量机(Support Vector Machine,SVM)
【李宏毅机器学习笔记】 19、Structured Learning - Introduction(待填坑)
【李宏毅机器学习笔记】 20、Structured Learning - Linear Model(待填坑)
【李宏毅机器学习笔记】 21、Structured Learning - Structured SVM(待填坑)
【李宏毅机器学习笔记】 22、Structured Learning - Sequence Labeling(待填坑)
【李宏毅机器学习笔记】 23、循环神经网络(Recurrent Neural Network,RNN)
【李宏毅机器学习笔记】 24、集成学习(Ensemble)
------------------------------------------------------------------------------------------------------
【李宏毅深度强化学习】视频地址:https://www.bilibili.com/video/av10590361?p=24
课件地址:http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML16.html
-------------------------------------------------------------------------------------------------------
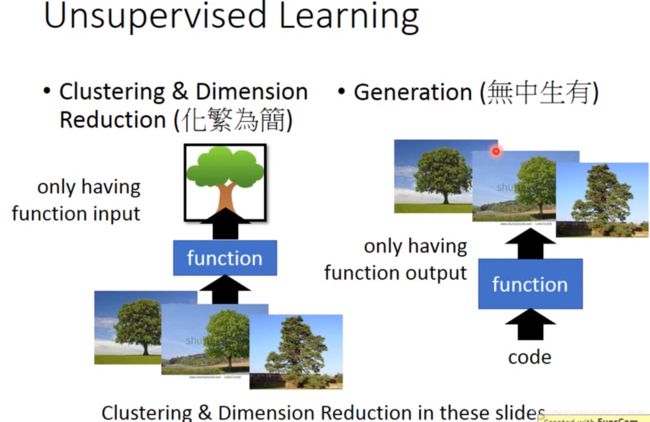
Unsupervised Learning 可以分为两类。
一类是有输入实例(现实的树),输出更抽象的东西,即化繁为简。
一类是输入一个code,然后输出具体的实例,即无中生有。
聚类(Clustering)
K-means

K-means做聚类,需要先人为确定要聚类成多少类。K代表多少类。
- 数据集X,里面N个unlabel的data
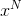
- 初始化每一个聚类的中心(随机从data里挑一些出来即可)
- 遍历所有data,计算每一个data和这些中心的距离。如果距离近的话则属于此中心所代表的类别。
- 更新中心,把所有属于 i 类的data加起来,取平均。
- 重复3、4步。
Hierarchical Agglomerative Clustering(HAC)
如上图,由下往上看。
- 计算5个data两两之间的相似性,将比较像的data做平均,得到它们之间的上一层节点。重复这个过程。
- 人为地选择要切在哪里。比如切在红线,则代表前三个data和后两个data分为两类。如果且在蓝色则代表前两个data、第三个data、后两个data,总共分为三类。
Dimension Reduction

刚才做聚类时,是强制性的把某一个data归类于某一个class。这样时不准确的。因为一个data可能同时拥有多个class的特性,所以应该把它写成如图中vector一样。
这种从高维的vector(比如图像)转化成低维的vector,就叫做Dimension Reduction 。
做Dimension Reduction的好处

如上图,左边是data以螺旋状分布在3维空间里。但其实如右边的样子,以2维的空间就可以描述这些信息,这样就把简化了问题。
怎么做Dimension Reduction?

既然是做 Dimension Reduction ,那就要求输入 x 的维度比输出的 z 的维度要少。有两个方法可以做到这件事,是feature selection和Principal Component Analysis(PCA)。
feature selection

feature selection的方法很简单:把data的分布列出来,如上图,可以看到data分散在x2的维度中,而没有在x1的维度,所以就可以把x1维去掉。
不足:这个方法只能对于比较简单的情况起作用,像右边data分布复杂些就处理不了
Principal Component Analysis(PCA)
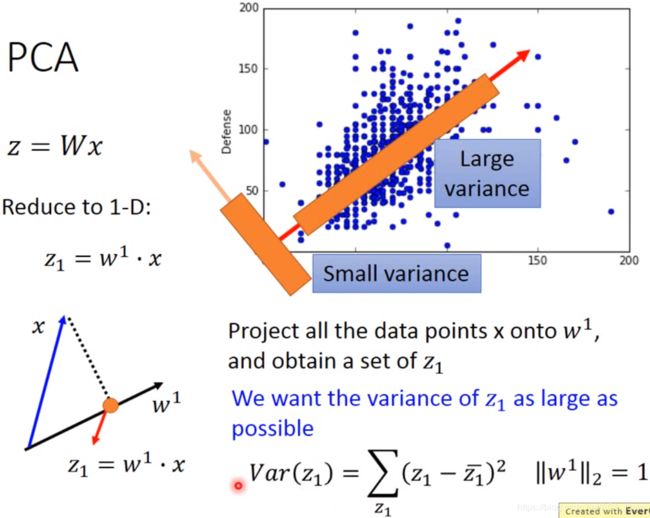
PCA方法就是找一个W,使得输入的 x 能降维到输出时的 z 。
以降维到一维为例子:如上图左边所示,z 就相当于 x 投影到 ![]() 上的结果。
上的结果。
而从右图中可以发现,不同的 w 会让降维后的 z 呈现不同的分布。为了不让投影后的结果(即z) 太“拥挤”(即原本不同x之间的差异性被消除了),所以需要找一个能让 z 的方差尽可能大的 w 。
另外,w的L2-norm需要强制等于1(具体理由等下再说)。
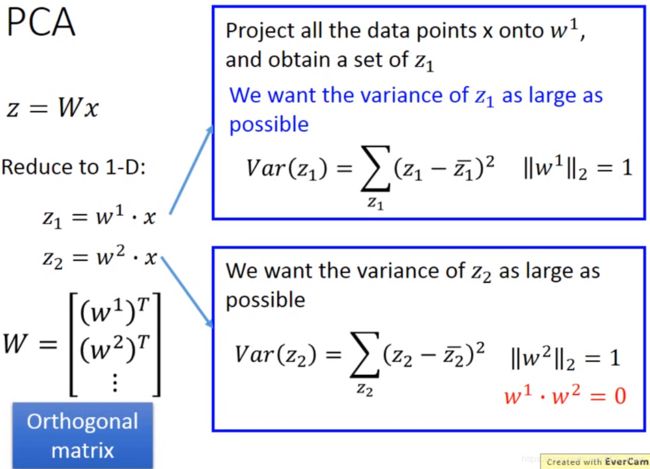
刚才说的是 x 降维到 1 维的例子。这里想讲的是降维到 2 维的情况。
其实做法都差不多,还是找一个能让  的方差尽可能大的
的方差尽可能大的 ![]() 。但是强制要求这个
。但是强制要求这个 ![]() 和
和 ![]() 之间的内积为0。
之间的内积为0。
现在知道了PCA粗略的过程,下面看具体怎么找 w (这部分涉及数学,看不懂也没关系,你也可以直接跳过“警告”部分)。
---------------------------------------数学警告------------------------------------------------

如图,z1 的方差的整理过程。
所以原来要最大化Var(z1)的问题转化成最大化![]() 。
。
而最大化这个式子,有一个简单的方法就是无脑把w变大,这显然是错误的,所以要加一些限制:
刚才有说过这个,就是强制 w 的L2-norm要等于1,这样w就不能无限变大了。


上面是求解的过程,建议想深入了解的话看视频吧
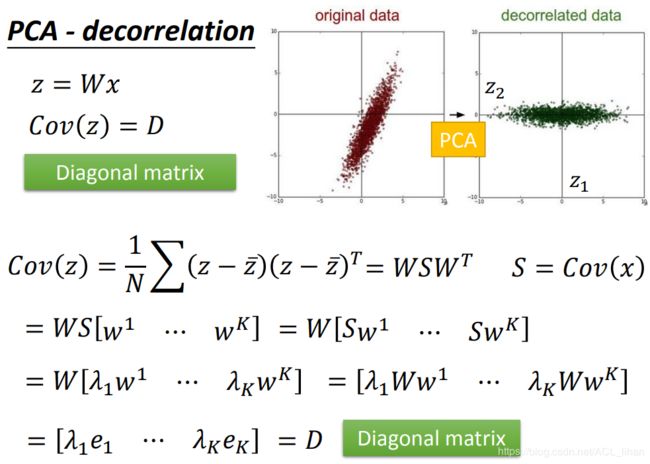
做完PCA后, 会使得数据的相关性减少,就是说不同维度之间的协方差是0 。
所以把input data做完PCA后,再丢给model训练,这样就可以减少参数量。
---------------------------------------数学警告结束------------------------------------------------
未完待续。。