GAN学习之路(五):Mask-Guided Portrait Editing withcGANs
文章目录
- 1. 相关概念
- 1.1 Portrait Editing
- 1.2 cGAN
- 1.3 MASK(掩膜)
- 2.文章idea
- 3. 三个子网络实现
- 3.1 局部嵌入子网络
- 3.2 掩膜引导生成子网络
- 3.3 背景融合子网络
- 4. 实验细节
- 4.1 训练策略
- 4.2 训练细节
- 4.2 实验结果
我们先看一下论文题目Mask-Guided Portrait Editing with CGAN,使用cGAN来进行掩膜引导的肖像编辑。肖像编辑是最终的目的,掩膜和cGAN是手段。
1. 相关概念
1.1 Portrait Editing
肖像编辑是图像处理里的热门话题,我的理解就是对人脸或者人脸的某一部分(鼻子、眼睛等等)进行处理,处理的手段包括美化、替换等等。肖像编辑由于其在电影、游戏、照片处理和共享等方面的潜在应用,在视觉和图形领域引起了广泛的关注。人们想获得让脸看起来更有趣、更有趣、更美丽的魔力。
1.2 cGAN
条件生成对抗网络是一种非常实用且流行的网络,比较详细的介绍在这里。虽然条件生成对抗网络能够生成人脸,但细节之处非常不真实。为了解决这个问题,一种可能的解决方案是使用掩膜来引导生成。一方面,掩膜提供了良好的积核约束,这有助于合成比较真实的轮廓。
1.3 MASK(掩膜)
MASK在深度学习是指图像分割的一个结果。图片中有个圆形物体,我们从纸上剪掉一个和该物体一模一样大小的圆,将这张纸蒙在图片中,也就是MASK。掩膜用于帮助在学习中为每个组件指定区域,为源图像和目标图像建立了组件级的对应。
2.文章idea
肖像编辑框架主要由三部分组成:局部嵌入子网络、掩码引导生成子网络和背景融合子网络,这三个子网络都是端到端的网络。
- 局部嵌入子网络:局部嵌入自网络包含五个自编码器,分别对应五个面部分量:左眼、右眼、嘴、皮肤(鼻子)、头发。
- 掩膜引导生成子网络:掩模引导生成子网络将局部嵌入的片段与目标掩膜重新组合在一起,生成前景人脸图像。掩膜用于帮助在学习中为每个组件指定区域。
- 背景融合子网络:主要负责融合背景和前景人脸,根据目标人脸掩膜生成自然的人脸图像。
掩膜会帮助所有三个子网络的面部生成。有了掩膜,作者的框架可以应用在很多地方,如下图a,作者可以在掩码的引导下生成新的面孔,而在下图b中,作者则改变了局部的一些特征,比如嘴等等;图c中作者则展示该边所有局部特征的一个生成结果。

综上所述:
- 文章提出了一种基于掩模引导的条件生成对抗网络(cGANs)的新框架,成功地解决了人脸合成中的多样性、质量和可控性问题。
- 该框架是通用的,可用于大量应用程序,如掩膜合成人脸、肖像编辑、人脸交换等等。
3. 三个子网络实现
下图是三个自网络的示意图:
损失函数是由最后的蓝色框线输出部分。
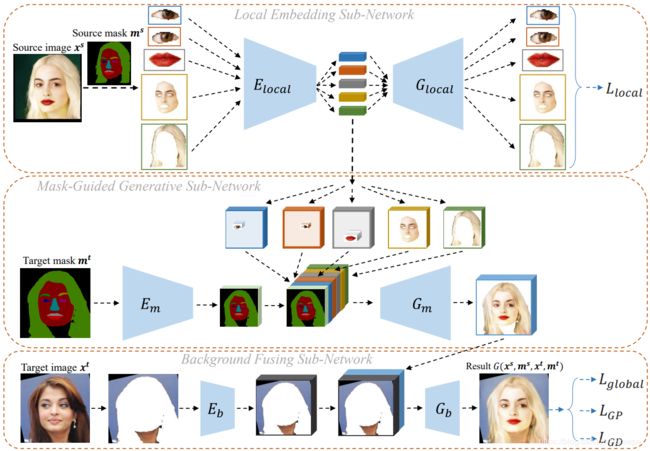
3.1 局部嵌入子网络
如上图的Local Embedding Sub-Network部分,我们首先将人脸 x s x^{s} xs输入 P F P_F PF网络中以获得掩膜 m s m^s ms( P F P_F PF是一个全卷积网络,使用Helen数据集训练,能够生成人脸掩膜的网络)。之后根据人脸掩膜,我们将人脸分为五部分 x i s x_i^s xis 其中i={0,1,2,3,4},分别表示{“左眼”,“右眼”,“嘴”,“皮肤和鼻子”,“头发”}五部分,对于每一部分,我们使用相应的自编码器网络{ E l o c a l i E_{local}^i Elocali, G l o c a l i G_{local}^i Glocali}。
利用五种自编码器网络,我们可以方便地改变生成的人脸图像中的任何一个面部成分,或重组来自不同面部的不同成分。
损失函数:
在该网络中,我们使用了 L l o c a l L_{local} Llocal损失函数来对 E l o c a l E_{local} Elocal进行约束:
L l o c a l = 1 2 ∣ ∣ x i s − G l o c a l i ( E l o c a l i ( x i s ) ) ∣ ∣ 2 2 L_{local}=\frac{1}{2}{||x_i^s - G_{local}^i(E_{local}^i(x_i^s))||}_2^2 Llocal=21∣∣xis−Glocali(Elocali(xis))∣∣22
其原理和自编码器一模一样,就是为了保持输入和输出相同。
3.2 掩膜引导生成子网络
这个网络主要负责将局部嵌入自网络 E l o c a l i E_{local}^i Elocali生成的人脸五部分特征 x i s x_i^s xis以及目标掩膜特征张量融合在一起。其中,掩膜特征张量是目标掩膜 m t m^t mt经过编码器 E m E_m Em输出的结果。掩膜引导生成子网络分为以下几步:
- 从目标掩膜 x t x^t xt(我个人觉得应该是 m t m^t mt,但原文是 x t x^t xt)中获取五个分量的中心位置 { c i } i = 1 , 2 , 3 , 4 , 5 \{c_i\}_{i=1,2,3,4,5} {ci}i=1,2,3,4,5;
- 准备五个3D张量,所有的张量使用0填充, { f ^ i } i = 1...5 \{\hat f_i\}_{i=1...5} {f^i}i=1...5,每个张量的高宽与掩膜特征张量相同,和每个部分的组件的通道数相同;
- 我们根据五个分量的中心位置 { c i } i = 1 , 2 , 3 , 4 , 5 \{c_i\}_{i=1,2,3,4,5} {ci}i=1,2,3,4,5,将人脸五部分特征 x i s x_i^s xis分别放在五个新建张量 { f ^ i } i = 1...5 \{\hat f_i\}_{i=1...5} {f^i}i=1...5的相应位置上;
- 我们将所有的3D张量和目标掩膜特征张量拼接起来得到一个融合后的张量;
- 最后,我们将融合后的张量输入到 G m G_m Gm中来生成前景图像。
3.3 背景融合子网络
将生成的前景面粘贴到目标图像的背景中,最直接的方法是从目标图像 x t x^t xt中复制背景,然后根据目标口罩将其与前景面结合起来。但这样会导致前景和背景的边界非常明显,可能的原因有二:
- 颈部皮肤存在于肖像背景中,我们可能融合得到的图像会有肤色的不同;
- 掩膜得到的结果不一定很完美,也许会有头发残存于背景中。
为了解决这个问题,我们就创造了背景融合子网络,步骤如下:
- 使用掩膜解析网络 P F P_F PF得到肖像背景部分;
- 将背景部分输入到编码器 E b E_b Eb中来得到背景部分的特征张量;
- 将背景部分特征张量与前景人脸肖像部分拼接,输入到生成网络 G b G_b Gb中,得到最终的结果。
损失函数:
在该网络中,我们使用了 L g l o b a l L_{global} Lglobal、 L G P L_{GP} LGP、 L G D L_{GD} LGD损失函数来进行约束,:
- L g l o b a l = 1 2 ∣ ∣ G ( x s , m s , x t , m t ) − x s ∣ ∣ 2 2 L_{global}=\frac{1}{2}{||G(x^s,m^s,x^t,m^t)-x^s||}_2^2 Lglobal=21∣∣G(xs,ms,xt,mt)−xs∣∣22 ,这里的 G ( x s , m s , x t , m t ) G(x^s,m^s,x^t,m^t) G(xs,ms,xt,mt)就是我们最终的输出(也是背景融合子网络的输出),而 x s x^s xs是我们的源输入图像;
- 从论文题目可以看出,论文提出的网络要使用cGAN,于是就在这里,我们将详细解释cGAN是如何使用在本项目中。论文使用了Pix2PixHD的多尺度判别器(目测是指两个判别器这样,我会在文后进行详细解释),这里的条件生成网络的条件是指 m t m^t mt,那么,两个判别器的损失函数为: L D i = − E x t ∼ P r [ l o g D i ( x t , m t ) ] − E x t , x s ∼ P r [ l o g ( 1 − D i ( G ( x s , m s , x t , m t ) , m t ) ) ] L_{D_i}=-E_{x^t\sim P_r}[logD_i(x^t,m^t)]-E_{x^t,x^s\sim P_r}[log(1-D_i(G(x^s,m^s,x^t,m^t),m^t))] LDi=−Ext∼Pr[logDi(xt,mt)]−Ext,xs∼Pr[log(1−Di(G(xs,ms,xt,mt),mt))],生成器G的损失函数为 L s i g m o i d = − E x t , x s ∼ P r [ l o g ( D i ( G ( x s , m s , x t , m t ) , m t ) ) ] L_{sigmoid}=-E_{x^t,x^s\sim P_r}[log(D_i(G(x^s,m^s,x^t,m^t),m^t))] Lsigmoid=−Ext,xs∼Pr[log(Di(G(xs,ms,xt,mt),mt))];由于原始的生成器G损失可能会导致梯度不稳定的问题,因此,作者还提出了分类器D在最后一层输出的特征层表示为 f D i ( x t , m t ) f_{D_i}(x^t,m^t) fDi(xt,mt),那么作者提出了特征匹配损失(feature matching loss)为 L F M = 1 2 ∣ ∣ f D i ( G ( x s , m s , x t , m t ) , m t ) − f D i ( x t , m t ) ∣ ∣ 2 2 L_{FM}=\frac{1}{2}{||f_{D_i}(G(x^s,m^s,x^t,m^t),m^t)-f_{D_i}(x^t,m^t)||}_2^2 LFM=21∣∣fDi(G(xs,ms,xt,mt),mt)−fDi(xt,mt)∣∣22因此,G最终的输出为 L G D = L s i g m o i d + λ F M L F M L_{GD}=L_{sigmoid}+\lambda_{FM}L_{FM} LGD=Lsigmoid+λFMLFM。
- 我们之前提到了一个全卷积网络 P F P_F PF用来进行语义分割,这个网络本质是U-Net网络,也就是自编码器结合跳跃连接,它是在Helen人脸数据集上进行训练,其中的损失函数为 L P = − E x ∼ P r [ ∑ i , j l o g P ( p i , j ∣ P F ( x ) i , j ) ] L_P = -E_{x\sim P_r}[\sum_{i,j}logP(p_{i,j}|P_F(x)_{i,j})] LP=−Ex∼Pr[∑i,jlogP(pi,j∣PF(x)i,j)],这里的(i,j)是指相应位置的像素。在经过Helen人脸数据集后,我们希望最终生成的人脸经过 P F P_F PF后可以与目标掩膜一样,那么最终的损失函数为 L G P = − E x ∼ P r [ ∑ i , j P ( M i , j t ∣ P F ( G ( x s , m s , x t , m t ) ) i , j ) ] L_{GP}=-E_{x\sim P_r}[\sum_{i,j}P(M_{i,j}^t|P_F(G(x^s,m^s,x^t,m^t))_{i,j})] LGP=−Ex∼Pr[∑i,jP(Mi,jt∣PF(G(xs,ms,xt,mt))i,j)]
最终的生成模型G的损失函数为:、
L G = λ l o c a l L l o c a l + λ g l o b a l L g l o b a l + λ G D L G D + λ G P L G P L_G=\lambda_{local}L_{local}+\lambda_globalL_{global}+\lambda_{GD}L_{GD}+\lambda_{GP}L_{GP} LG=λlocalLlocal+λglobalLglobal+λGDLGD+λGPLGP,在作者的论文指出,实验中 λ l o c a l , λ g l o b a l , λ G D , λ G P = { 10 , 1 , 1 , 1 } \lambda_{local},\lambda_{global},\lambda_{GD},\lambda_{GP}=\{10,1,1,1\} λlocal,λglobal,λGD,λGP={10,1,1,1}
4. 实验细节
4.1 训练策略
m s m^s ms和 m t m^t mt是 x s x^s xs和 x t x^t xt通过 P F P_F PF得到,因此网络的输入其实是 x s x^s xs和 x t x^t xt。论文借鉴了自编码器的思想,论文需要两种类型的输入:
- 匹配数据:一种是 x s x^s xs和 x t x^t xt是同一幅图像;对于匹配数据,我们使用全部的 L G L_G LG损失
- 非匹配数据:一种是 x s x^s xs和 x t x^t xt不是同一幅图像;对于非匹配数据,我们将 λ g l o b a l \lambda_{global} λglobal和 λ F M \lambda_{FM} λFM设置为0。
这两种输入交替输入,输入一次匹配数据,再输入一次非匹配数据,交替进行。
4.2 训练细节
我们使用Helen数据进行 P F P_F PF的训练以及评估。Helen数据集包括2330张人脸数据(2000张训练集,330张测试集)。但由于2000张人脸图像的有效性有限,因此我们首先使用这2000张人脸图像来训练解析网络 P F P_F PF,然后使用解析网络从VGGFace2获得额外的20000张人脸图像的语义掩码。在实验过程中,我们总共使用了22000张人脸图像进行训练。解析网络具体训练过程如下:
- 使用JDA人脸检测器检测面部区域;
- 定位五个面部标志(两只眼睛、鼻尖和两个嘴角);
- 作者使用了基于面部标志的相似变换将人脸对齐到一个规范位置;
- 裁剪出一个256x256的面部区域来做试验;
在作者的实验中,五个张量(左眼、右眼、嘴、皮肤和头发)的输入大小由每个组件的最大大小决定。因此在实验中作者使用48x32,48x32,144x80,256x256,256x256的大小来表示左眼、右眼、嘴、皮肤和头发。

上图是论文作者提出的网络与Pix2PixHD以及bicycleGAN进行对比的结果,Pixel2PixHD以及bicycleGAN的输入是掩膜(traget mask),而作者的网络输入是(source image和target image)。
4.2 实验结果
如上图,掩膜右边是实验的生成的结果,第一列是target image,第二列是traget mask。

当然,本论文同时支持两种肖像编辑:
- 改变人脸的某一部分的掩膜,如上图的前两行;
- 将其他人脸的某一部分掩膜组件替换本人脸的一部分,如下面两行;

上图第一列是输入图像和输入的掩膜,第二列分别将胡子添加和改变头发,第三列改变嘴唇和改变眼妆。

上图是两张图像进行了一个交换,也就是两张图像分别为 x t x^t xt和 x s x^s xs的时候。

上图第一列是 x t x^t xt,第二列是 x s x^s xs,第三列是输出。