使用AlexNet模型对于5种花进行分类
数据集整理
原始数据集中有5个文件夹,每个文件夹下有许多张对应类别花朵的图片


我们将每种图片随机抽取出10%作为测试用数据集,剩下的90%用作训练数据集

模型选择
选的AlexNet模型,其概览如下
AlexNet( (features): Sequential( (0): Conv2d(3, 48, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2)) (1): ReLU(inplace=True) (2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) (3): Conv2d(48, 128, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2)) (4): ReLU(inplace=True) (5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) (6): Conv2d(128, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (7): ReLU(inplace=True) (8): Conv2d(192, 192, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (9): ReLU(inplace=True) (10): Conv2d(192, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (11): ReLU(inplace=True) (12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) ) (classifier): Sequential( (0): Dropout(p=0.5, inplace=False) (1): Linear(in_features=4608, out_features=2048, bias=True) (2): ReLU(inplace=True) (3): Dropout(p=0.5, inplace=False) (4): Linear(in_features=2048, out_features=2048, bias=True) (5): ReLU(inplace=True) (6): Linear(in_features=2048, out_features=5, bias=True) ) )
整体分为2部分,第一部分 features 负责特征抽取,包含了5个卷积层和3个最大下采样层。
第二部分 classifier 负责对前边抽取出的特征进行分类,包含了3个全连接层。
网络接受一个 通道数×长×宽 = 3×224×224的 张量,输出一个 包含5个元素的张量。
损失函数
选用CrossEntropyLoss,这是一个由Softmax -> ln -> NLLLoss 合并在一起的函数,正由于这个损失函数里包含了Softmax,所以我们的模型中最后就不用再包含Softmax了。
Softmax后的数值都在0~1之间,所以ln之后值域是负无穷到0。 NLLLoss的结果就是把上面的输出与Label对应的那个值拿出来,再去掉负号,再求均值。
优化器
SGD优化器
就是简单的梯度下降法,缺点是在某些情况下梯度可能并未指向最低点,优化路径可能会非常曲折

SGD with Momentum
在梯度下降法的基础上,加入了动量的概念,每一次更新方向如果试图“拐大弯”,会被上一次更新方向抵消一部分,使得优化路径更平滑

AdaGrad
动态调整参数的学习率,参数的元素中变动较大(被大幅更新)的元素的学习率将变小

Adam
Adam优化器是结合了“动量”和“学习率自适应”两种方法的优化方法,另外它包含了二级动量,更新更平滑
数据预处理
对于测试集的图片进行随机裁剪、随机水平翻转,以增强数据集;
至于为什么要把输入数据都压缩到0.5附近,感觉可能是为了训练的时候更快收敛吧,因为各种激活函数的函数值突变区都在这个附近。如果一开始输入的值都很大的话,比如sigmoid函数的斜率在很大的地方几乎为0了,那样就更新不动了(梯度消失)

Batch数据加载
太大的batch_size可能会爆内存,听说选用2的幂次方可以更高效的利用运算性能

开始训练
笔记本不带GPU,跑不动,只训练了15个EPOCH,最终在测试集上的准确率平均在67%左右,似乎不是很高
但是最终拿从网上下载的花朵图片进行测试,每次模型都能正确预测并且给出的置信度都在95%以上,
我觉得可能是因为我选用的都是纯花朵的图片,而测试集中有许多图片花朵都不是主角,存在着大面积的人物、绿叶等干扰。
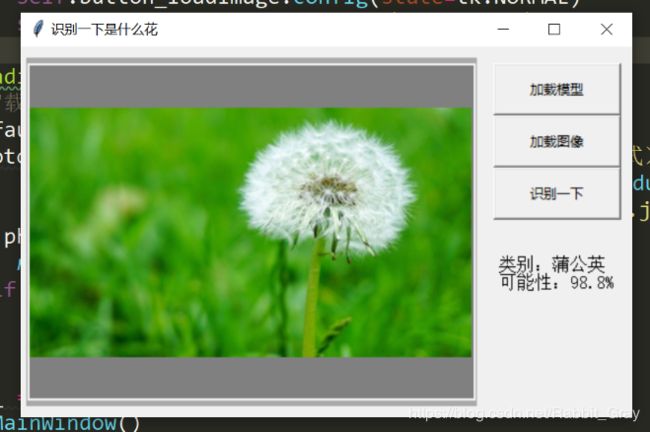
可视化界面
先加载模型,再加载图像,点击一下进行识别。
一些知识点
-
在模型的全连接层前加上Dropout层可以防止过拟合,Dropout的工作原理是每次前向传播的时候随机使一定比例的神经元失活(就好像不存在一样),这样的话每次训练都相当于在对于不同的模型训练,最终再取得模型的平均值
-
模型初始化的个权重参数一般按照高斯分布初始化
-
如果模型中有BN层,模型的bias就是不必要的,即使使用了bias,在BN层也会被抵消掉
-
预测的时候使用上下文管理器 with torch.no_grad(): 可以使模型不创建权重参数梯度数据,因为预测的时候模型的参数是不需要被更新的,所以也就用不着梯度,于是乎就节省了内存空间
-
使用net.train()和net.eval()来使模型进入训练模式和预测模式,区别是预测模式下的模型不会让Dropout层起作用,因为预测的话最好还是使用完整的模型比较好
-
PIL的ImageTk.PhotoImage(img)返回的对象必须一直被引用着,一旦失去引用,绘制到canvas上的图像立即就消失(PIL的大坑)
-
self.canvas.update() 获取组件宽高之前要先对于这个组件update() (tk的大坑)
先写这么多,回头再更