MySql学习(四) —— 函数、视图
本篇博客主要涉及MySql 函数(数学函数、字符串函数、日期时间函数、流程控制函数等),视图。
回到顶部
一、函数
1. 数学函数
对于数学函数,若发生错误,所有数学函数会返回 NULL
1.1 abs(x) 返回x的绝对值
1.2 bin(x) 返回x的二进制数
1.3 oct(x) 返回x的八进制数
1.4 hex(x) 返回x的十六进制数
1.5 ceiling(x) 返回大于x的最小整数值
1.6 floor(x) 返回小于x的最大整数值
1.7 exp(x) 返回e的x次方(e是自然数的底)
1.8 greatest(x1,x2,x3,...,xn) 返回集合中最大的值
1.9 least(x1,x2,x3,...,xn) 返回集合中最小的值
1.10 ln(x) 返回x的自然对数
1.11 log(x, y) 返回x的以y为底的对数
1.12 mod(x, y) 返回x/y的模(余数)
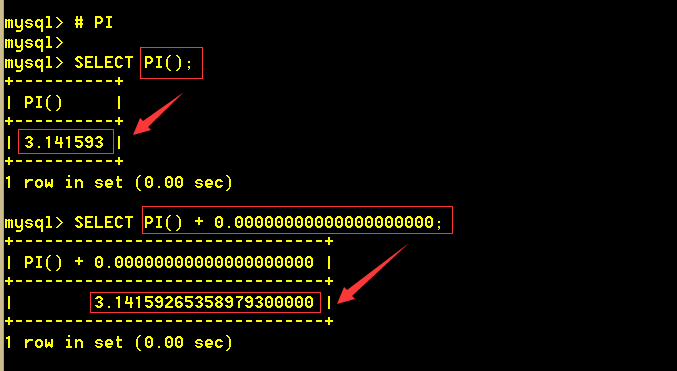
1.13 pi() 返回PI的值(圆周率)
1.14 rand() 返回一个随机浮点值 v ,范围在 0 到1 之间 (即, 其范围为 0 ≤ v ≤ 1.0)。若已指定一个整数参数 N ,则它被用作种子值,用来产生重复序列。
rand(N),随机数的产生取决于种子,种子不同,产生不同的随机数,种子相同,不管运行多少次都产生相同的随机数。所以,除非必要,否则不要设置随机种子。


若要在i ≤ R ≤ j 这个范围得到一个随机整数R ,需要用到表达式 FLOOR(i + RAND() * (j – i + 1))。
例如, 若要在7 到 12 的范围(包括7和12)内得到一个随机整数, 可使用以下语句:SELECT FLOOR(7 + (RAND() * 6));

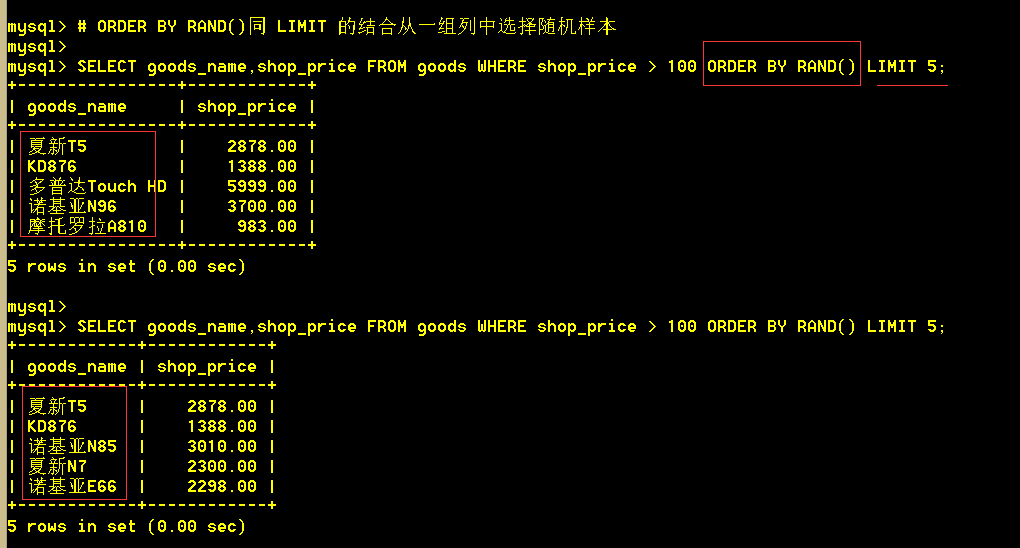
ORDER BY RAND()同 LIMIT 的结合从一组列中选择随机样本很有用;
在WHERE语句中,WHERE每执行一次, RAND()就会被再计算一次;
1.15 round(x), round(x, y) 返回x的四舍五入的有y位小数的值。若要接保留x值小数点左边的y 位,可将 y 设为负值。


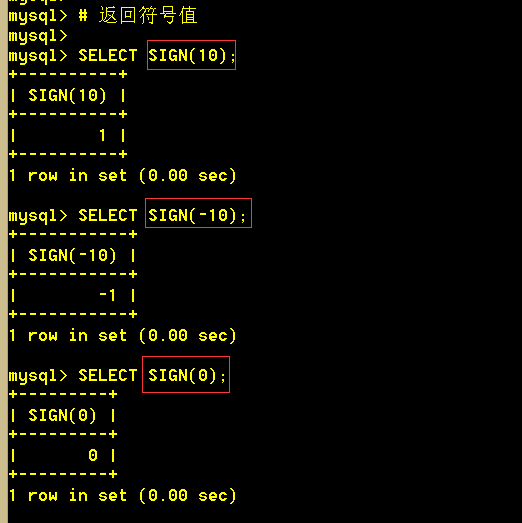
1.16 sign(x) 返回x作为-1、 0或1的符号,该符号取决于x的值为负、零或正。
1.17 sqrt(x) 返回非负数X 的二次方根

1.18 pow(x, y) 返回x 的y乘方的结果值
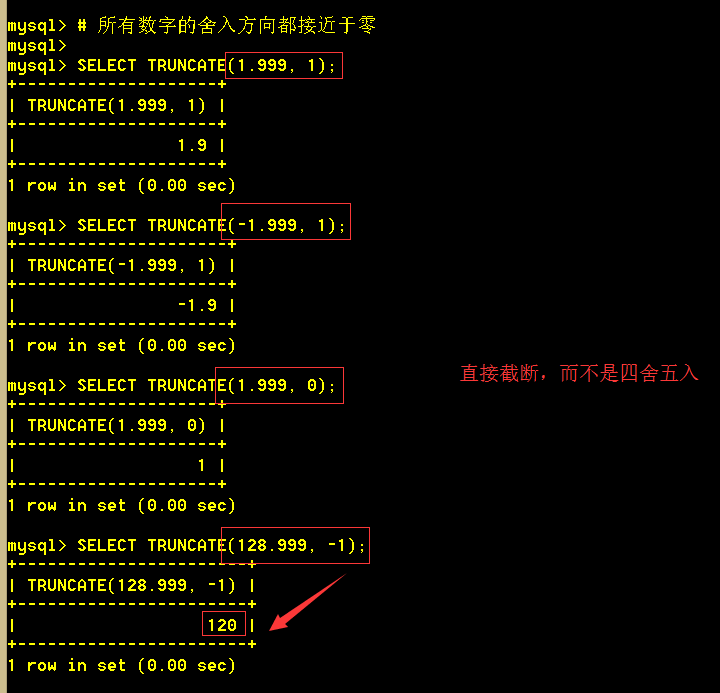
1.19 truncate(x, y) 返回被舍去至小数点后y位的数字x。若y 的值为 0, 则结果不带有小数点或不带有小数部分。可以将y设为负数,若要截去(归零) x小数点左起第y位开始后面所有低位的值。所有数字的舍入方向都接近于零。
2. 聚合函数(常用于group by从句的select查询中)
2.1 avg(expr) 返回expr 的平均值。若找不到匹配的行,则avg()返回 NULL
2.2 count(expr) 返回SELECT语句检索到的行中非NULL值的数目
2.3 min(expr) 返回表达式的最小值
2.4 max(expr) 返回表达式的最大值
2.5 sum(expr) 返回表达式的和
2.6 group_concat() 返回带有来自一个组的连接的非NULL值的字符串结果

3. 字符串函数
3.1 ascii(str) 返回值为字符串str 的最左字符的数值。假如str为空字符串,则返回值为 0 。假如str 为NULL,则返回值为 NULL。 ASCII()用于带有从 0到255的数值的字符。
3.2 length(str) 返回字符串字节长度

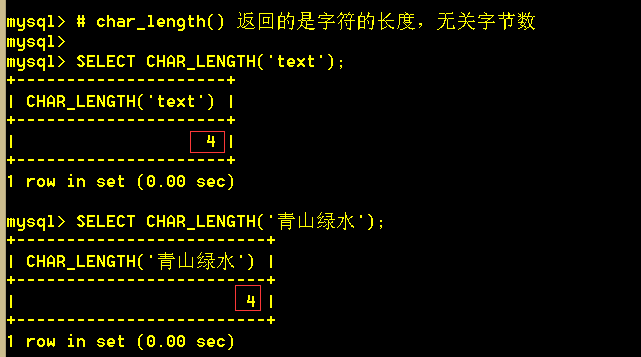
3.3 char_length(str) 返回字符串长度
3.2 bit_length(str) 返回值为二进制的字符串str 长度。

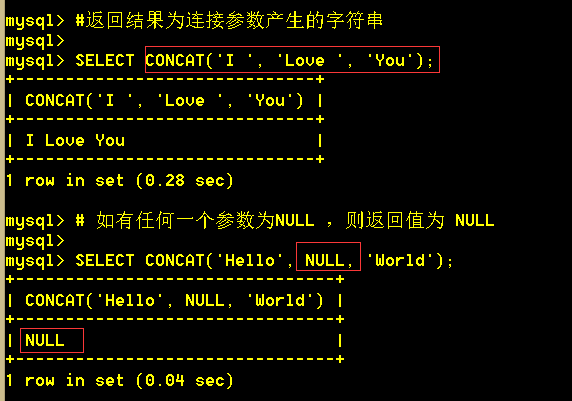
3.3 concat(s1,s2,s3,..,sn) 返回结果为连接参数产生的字符串。如有任何一个参数为NULL ,则返回值为 NULL。
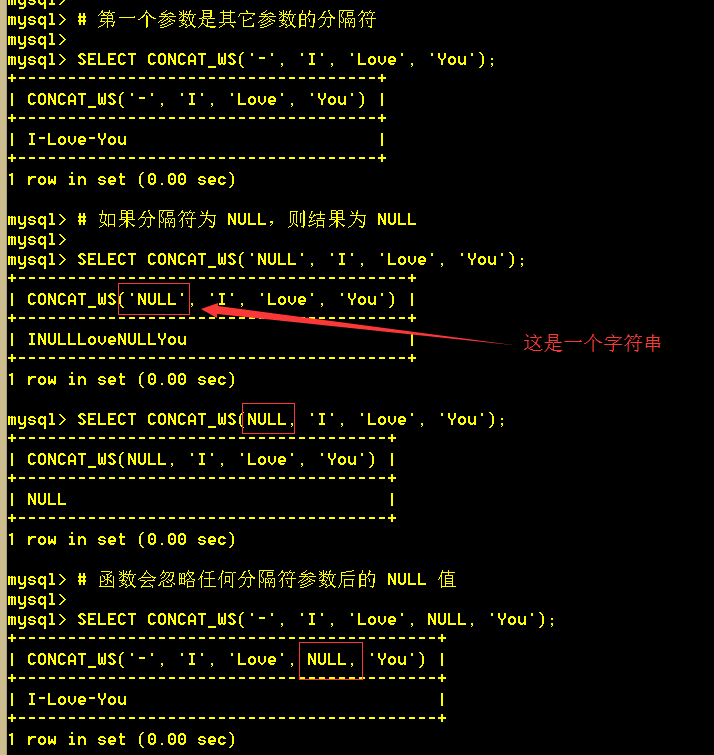
3.4 concat_ws(sep, s1, s2,..,sn) 代表Concat With Separator ,是concat()的特殊形式。第一个参数是其它参数的分隔符。分隔符的位置放在要连接的两个字符串之间。分隔符可以是一个字符串,也可以是其它参数。如果分隔符为 NULL,则结果为 NULL。函数会忽略任何分隔符参数后的 NULL 值。
3.5 insert(str, x, y, instr) 将字符串str从x位置开始,y个字符长度的子串替换为instr,返回结果。

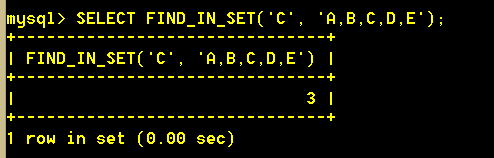
3.6 find_in_set(str, strList) strList是由一些被‘,’符号分开的自链组成的字符串,返回str在strList中的位置。
3.7 lcase(str) 或 lower(str) 返回小写字符串
3.8 ucase(str) 或 upper(str) 返回大写字符串
3.9 left(str, x) 返回str左边x个字符
3.10 right(str, x) 返回str右边x个字符
3.11 ltrim(str) 去掉str左边的空格
3.12 trim(str) 去掉str两边的空格
3.13 rtrim(str) 去掉str右边的空格
3.14 position(subStr in str) 返回子串subStr第一次在str中出现的位置
3.15 repeat(str, x) 返回str重复x的结果
3.16 reverse(str) 反转str
3.17 strcmp(s1, s2) 比较s1和s2
4. 日期时间函数
4.1 curdate() 或 current_date() 返回当前的日期
4.2 curtime() 或 current_time() 返回当前的时间
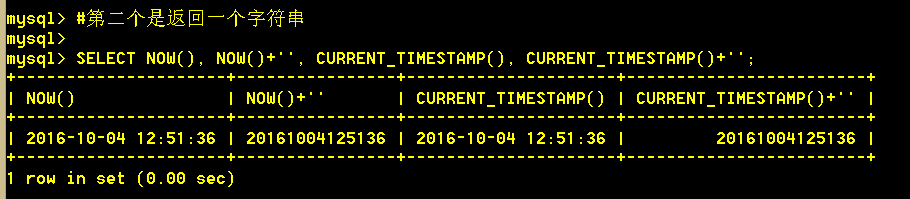
4.3 now() 或 current_timestamp() 返回当前日期和时间值,其格式为 'YYYY-MM-DD HH:MM:SS' 或YYYYMMDDHHMMSS , 具体格式取决于该函数是否用在字符串中或数字语境中。
4.4 year(date) 返回日期date的年份
4.5 month(date) 返回日期date的月份
4.6 monthname(date) 返回日期date的月份名
4.7 week(date) 返回date一年中的第几周
4.8 day(date) 或 dayofmonth(date) 返回date 对应的该月日期,范围是从 1到31
4.9 dayname(date) 返回date对应的工作日名称
4.10 dayofweek(date) 返回date (1 = 周日, 2 = 周一, ..., 7 = 周六)对应的工作日索引。
4.11 dayofyear(date) 返回date 对应的一年中的天数,范围是从 1到366。

4.12 date(date|datetime) 提取日期部分
4.13 datediff(expr1, expr2) 返回起始时间 expr和结束时间expr2之间的天数。

4.14 date_add(date|datetime, interval expr type) 执行日期运算。 date 用来指定起始时间。 expr 是一个表达式,用来指定从起始日期添加或减去的时间间隔值。 如果想要执行减运算,在expr前加个‘-’即可。 type 为关键词,它指示时间间隔的类型。
4.15 date_sub(date|datetime, interval expr type) date_add()执行加运算,date_sub()执行减运算

date_sub() 是date_add的逆过程

4.16 date_format(date, format) 根据format 字符串安排date 值的格式。


5. 加密函数
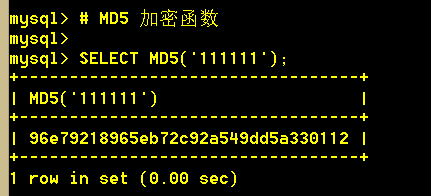
5.1 md5(str) MD5加密,碰撞性低,不可逆的;若参数为 NULL 则会返回 NULL。例如,返回值可被用作散列关键字。
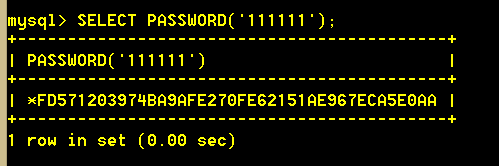
5.2 password(str) 从原文密码str 计算并返回密码字符串,当参数为 NULL 时返回 NULL。PASSWORD()函数在MySQL服务器中的鉴定系统使用;你不应将它用在你个人的应用程序中。
5.3 sha(str) 或 sha1(str) SHA1()可以被视为一个密码更加安全的函数,相当于 MD5()。

6. 流程控制函数
6.1 case [value] when [compare-value] then result [when [compare-value] then result]...[else result] end

6.2 if(expr1,expr2,expr3) 如果 expr1 是TRUE (expr1 <> 0 and expr1 <> NULL),则 IF()的返回值为expr2; 否则返回值则为 expr3。IF() 的返回值为数字值或字符串值。
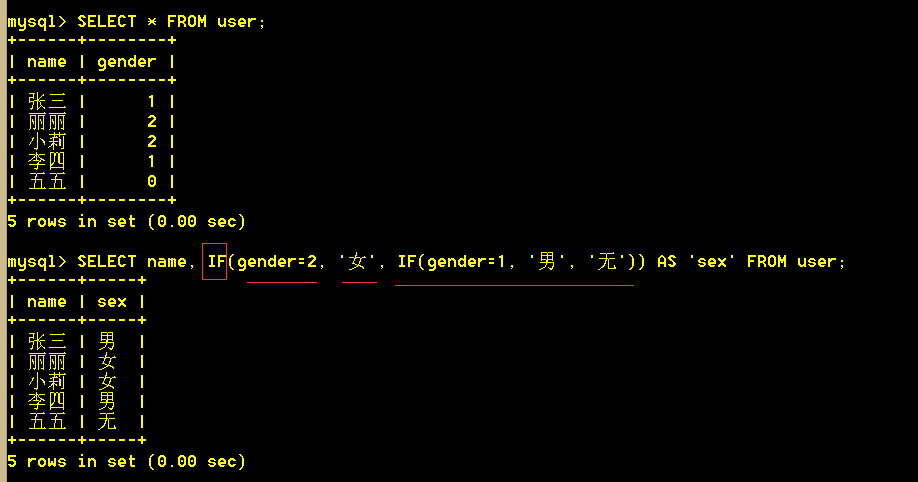
6.3 IFNULL(expr1, expr2) 假如expr1 不为 NULL,则 IFNULL() 的返回值为 expr1; 否则其返回值为 expr2。IFNULL()的返回值是数字或是字符串

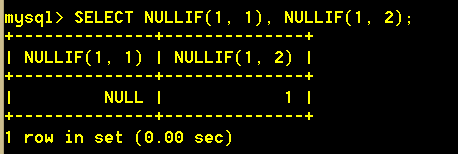
6.4 NULLIF(expr1, expr2) 如果expr1 = expr2 成立,那么返回值为NULL,否则返回值为 expr1。
7 系统信息函数
7.1 user() 或 current_user() 返回当前话路被验证的用户名和主机名组合。

7.2 charset(str) 返回字符串自变量的字符集。
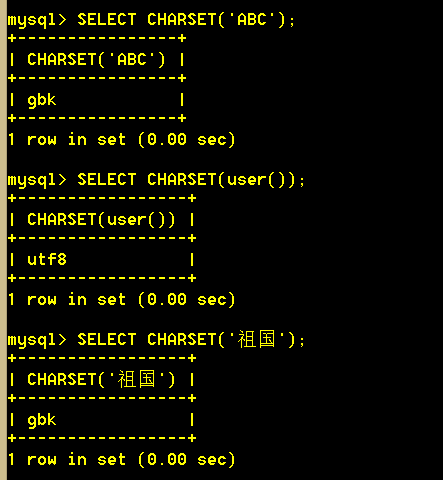
7.3 database() 返回使用 utf8 字符集的默认(当前)数据库名。

7.4 row_count() ROW_COUNT()返回被前面语句升级的、插入的或删除的行数。
7.5 version() 数据库版本
MySql函数总结:
1.mysql的函数肯定会影响查询速度,应该在建表的时候,通过合理的表结构减少函数的使用;例如添加冗余字段等。
2.如果确实要使用函数,比如时间的格式化,优先放在业务逻辑层处理,而不是sql查询语句中。
3.在查询时使用了函数,最大的一个坏处是,如果你针对某列查询,该列用上了函数,此列将不再使用索引。
回到顶部
二、视图(view)
在查询中,我们经常把查询结果当成临时表来看,视图可以看做一张虚拟表,是表通过某种运算得到的一个投影。临时表的数据不会变,而投影的数据会根据原表的数据变化而变化。
计算机数据库中的视图是一个虚拟表,其内容由查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据。但是,视图并不在数据库中以存储的数据值集形式存在。
1.创建视图的语法
create [algorithm = merge|temptable|undefined] view

视图一旦创建完毕,就可以将其当成一张表来看待。

2.视图在某些情况下,也是可以修改的,要求是视图的数据和表的数据一一对应;一一对应 是指:根据select关系,从表中取出的行,只能计算出视图中确定的一行;反之,视图中任意抽一行,能够根据select关系,反推出表中的确定的一行。




3. show create view

4. drop view
5. 使用create创建表的时候,生成三个文件,frm(表结构,自动定义等),MYD(数据),MYI(索引),可以看到视图只有一个表结构定义。

6. algorithm algorithm可取三个值:merge、temptable或undefined。如果没有algorithm子句,默认算法是undefined(未定义的)。算法会影响MySQL处理视图的方式。
对于一些简单的视图,它在发挥作用的过程中,并没有建立临时表,而只是把条件存起来,下次来查询,把条件合并,直接去查基表,建临时表相比之下开销较大。
如果不指定algorithm,则更倾向于使用merge。

algorithm=temptable 适合于较复杂的视图,比如有聚合函数的视图等,这种是无法合并条件去基表查询的,需要生成一张临时表。

视图总结:
1.视图一旦创建完毕,就可以将其当成一张表来看待。
2.视图可以简化查询,对于一些复杂的统计,可以先用视图生成一个中间结果,再查询视图。
3.更加精细的权限控制,例如可以用视图隐藏掉用户表的密码字段,而将其开放给别人。
4.数据量大,分表时可以用视图将所有表的查询结果保存到一个视图中。
5.表的数据变化,会影响到视图的变化;
6.视图在某些情况下,也是可以修改的,要求是视图的数据和表的数据一一对应。所谓的一一对应,必须是通过select关系,视图能在基表中查出对应的数据,基表也可以在视图中查询对应的数据;例如select句中有order by limit 等都是无法一一对应的。
7.视图定义服从下述限制:
SELECT语句不能包含FROM子句中的子查询。
SELECT语句不能引用系统或用户变量。
SELECT语句不能引用预处理语句参数。
8.某些视图是可更新的。也就是说,可以在诸如UPDATE、DELETE或INSERT等语句中使用它们,以更新基表的内容。对于可更新的视图,在视图中的行和基表中的行之间必须具有一对一的关系。还有一些特定的其他结构,这类结构会使得视图不可更新。

9. ALGORITHM(算法)
可选的ALGORITHM子句是对标准SQL的MySQL扩展。ALGORITHM可取三个值:MERGE、TEMPTABLE或UNDEFINED。如果没有ALGORITHM子句,默认算法是UNDEFINED(未定义的)。算法会影响MySQL处理视图的方式。
对于MERGE,会将引用视图的语句的文本与视图定义合并起来,使得视图定义的某一部分取代语句的对应部分。
对于TEMPTABLE,视图的结果将被置于临时表中,然后使用它执行语句;建临时表的开销有点大。
对于UNDEFINED,MySQL将选择所要使用的算法。如果可能,它倾向于MERGE而不是TEMPTABLE,这是因为MERGE通常更有效,而且如果使用了临时表,视图是不可更新的。
明确选择TEMPTABLE的1个原因在于,创建临时表之后、并在完成语句处理之前,能够释放基表上的锁定。与MERGE算法相比,锁定释放的速度更快,这样,使用视图的其他客户端不会被屏蔽过长时间。