正则表达式基础详解
正则基础的元字符
我们开发者做校验,判断等等绕不过的一个东西就是正则表达式,那么我们首先来介绍一下最基本的正则表达式的元字符。
字符 描述
. 匹配除换行符以外的任意字符
\w 匹配字母、数字、下划线。等价于'[A-Za-z0-9_]‘
\W 匹配非字母、数字、下划线。等价于 '[^A-Za-z0-9_]'
\s 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]
\S 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]
\d 匹配一个数字字符。等价于 [0-9]
\D 匹配一个非数字字符。等价于 [^0-9]
除了这些还有些有特定功能的元字符。
-
限定符
字符 描述
*| 重复零次或更多次
+| 重复一次或更多次
?| 重复零次或一次
{n}| 重复n次
{n,}| 重复n次或更多次
{n,m}| 重复n次到m次
-
定位符
字符|描述
-|-
^|匹配字符串的开始位置
$|匹配字符串的结束位置
\b|匹配单词的边界,即字与空格之间的位置
\B|匹配非单词的边界
-
特殊字符
有自身功能的字符,匹配的时候需要转义
^ $ () [] {} * + . ? | \
-
分组字符
字符|描述
-|-
()|子表达式
[]|字符簇
{}|重复
-
运算符
字符|描述
-|-
\||或
正则运算的优先级
字符|描述
-|-
\|转义字符
(),(?:),(?=), []|圆括号和方括号
*,+,?,{n},{n,},{n,m}|限定符
^,$|定位符和其他字符
\||或
正则表达式的零宽断言
零宽断言也叫预查,类似于定位符,匹配不消耗字符
字符|描述
-|-
(?:pattern)|匹配 pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用 "或" 字符 (\|) 来组合一个模式的各个部分是很有用。例如,'industr(?:y\|ies) 就是一个比 'industry\|industries' 更简略的表达式。
(?=pattern)|正向肯定预查(look ahead positive assert),在任何匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如,"Windows(?=95\|98\|NT\|2000)"能匹配"Windows2000"中的"Windows",但不能匹配"Windows3.1"中的"Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
(?!pattern)|正向否定预查(negative assert),在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如"Windows(?!95\|98\|NT\|2000)"能匹配"Windows3.1"中的"Windows",但不能匹配"Windows2000"中的"Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。
(?<=pattern)|反向(look behind)肯定预查,与正向肯定预查类似,只是方向相反。例如,"(?<=95\|98\|NT\|2000)Windows"能匹配"2000Windows"中的"Windows",但不能匹配"3.1Windows"中的"Windows"。
(?
正则表达式的匹配模式
-
严格匹配
^\d+$ 通过定位符限制匹配方式从头到尾必须完全按照正则表达式来进行匹配
-
贪婪匹配
\d+ 正则表达式中含有限定符时,通常的行为是(在使整个表达式能得到匹配的前提下)匹配尽可能多的字符
-
懒惰匹配
\d+? 在限定符后边加?会被转化为懒惰匹配,意思是在符合正则表达式的前提下匹配尽可能少的字符
通过常用的正则表达式来探索正则的使用
邮箱校验
邮箱一般格式为(字母,数字,中间可能有-.符号)@(字母,数字,中间可能有-.符号).(cn,com等后缀为结尾)
^([a-zA-Z0-9]+[_|\.]?)*[a-zA-Z0-9]+@([a-zA-Z0-9]+[-|_|\.]?)*[a-zA-Z0-9]+\.[a-zA-Z]{2,3}$

域名校验
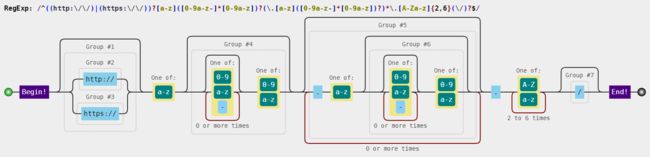
域名一般格式为 (可能有http://或者https://为开头)字母开头(中间可能有字母,数字,中划线)(字母作为前半部分结尾).(cn,com,top等后缀)(/最后可以有斜杠结尾也可以没有)
^((http:\/\/)|(https:\/\/))?a-z?(\.[a-z]([-a-z0-9]*[a-z0-9])?)+(\/)?$

如果要更加严格的匹配后缀可以用下边的
^((http:\/\/)|(https:\/\/))?a-z?(\.[a-z]([-a-z0-9][a-z0-9])?)\.[a-zA-Z]{2,6}(\/)?$
普通密码校验
规则 必须包含英文跟数字,不能为纯英文或者纯数字,不能有空字符
^(?=\S*[a-zA-Z])(?=\S*\d)[a-zA-Z0-9]{6,18}$

规则 必须包含英文或数字,字符,不能为纯英文或者纯数字,不能有空字符
^(?=\S*[a-zA-Z0-9])(?=\S*[^a-z0-9\s])\S{6,18}$

强密码校验
规则 必须包含英文,数字,大写字母或字符,不能有空字符
^(?=\S*[a-z])(?=\S*\d)(?=\S*[^a-z0-9\s])\S{6,18}$

上述的(?=\S)中的\S也可以用.代替
普通IP校验
规则 0.0.0.0~255.255.255.255
^((?:(?:25[0-5]|2[0-4]\d|[01]?\d?\d)\.){3}(?:25[0-5]|2[0-4]\d|[01]?\d?\d))$

^((25[0-5]|2[0-4]\d|1\d{2}|[1-9]\d|\d)\.){3}(25[0-5]|2[0-4]\d|1\d{2}|[1-9]\d|\d)$

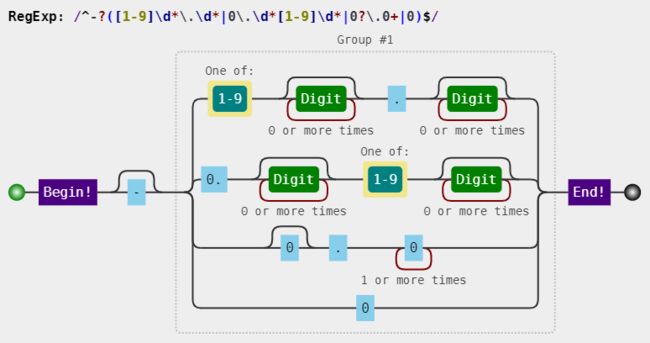
浮点数
^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$
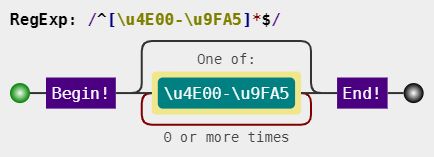
中文
^[\u4e00-\u9fa5]{0,}$
慎用正则
最近被大佬科普了一下正则的缺点,发现正则表达式虽然使用很方便,但也会导致一些不可预估的问题,所以要慎用!!!
为什么出现这些问题,要从正则表达式引擎说起,正则表达式是一个很方便的匹配符号,但要实现这么复杂,功能如此强大的匹配语法,就必须要有一套算法来实现,而实现这套算法的东西就叫做正则表达式引擎。简单地说,实现正则表达式引擎的有两种方式:DFA 自动机(Deterministic Final Automata 确定型有穷自动机)和 NFA 自动机(Non deterministic Finite Automaton 不确定型有穷自动机)。
DFA与NFA
总的来说,DFA可以称为文本主导的正则引擎,NFA可以称为表达式主导的正则引擎。
怎么讲?
我们常常说用正则去匹配文本,这是NFA的思路,DFA本质上其实是用文本去匹配正则。哪个是攻,哪个是受,大家心里应该有个B数了吧。
我们来看一个例子:
'tonight'.match(/to(nite|knite|night)/);
如果是NFA引擎,表达式占主导地位。表达式中的t和o不在话下。然后就面临三种选择,它也不嫌累,每一种都去尝试一下,第一个分支在t这里停止了,接着第二个分支在k这里也停止了。终于在第三个分支柳暗花明,找到了自己的归宿。
换作是DFA引擎呢,文本占主导地位。同样文本中的t和o不在话下。文本走到n时,它发现正则只有两个分支符合要求,经过i走到g的时候,只剩一个分支符合要求了。当然,还要继续匹配。果然没有令它失望,第三个分支完美符合要求,下班。
大家发现什么问题了吗?
只有正则表达式才有分支和范围,文本仅仅是一个字符流。这带来什么样的后果?就是NFA引擎在匹配失败的时候,如果有其他的分支或者范围,它会返回,记住,返回,去尝试其他的分支。而DFA引擎一旦匹配失败,就结束了,它没有退路。
这就是它们之间的本质区别。其他的不同都是这个特性衍生出来的。
首先,正则表达式在计算机看来只是一串符号,正则引擎首先肯定要解析它。NFA引擎只需要编译就好了;而DFA引擎则比较繁琐,编译完还不算,还要遍历出表达式中所有的可能。因为对DFA引擎来说机会只有一次,它必须得提前知道所有的可能,才能匹配出最优的结果。
所以,在编译阶段,NFA引擎比DFA引擎快。
其次,DFA引擎在匹配途中一遍过,溜得飞起。相反NFA引擎就比较苦逼了,它得不厌其烦的去尝试每一种可能性,可能一段文本它得不停返回又匹配,重复好多次。当然运气好的话也是可以一遍过的。
所以,在运行阶段,NFA引擎比DFA引擎慢。
最后,因为NFA引擎是表达式占主导地位,所以它的表达能力更强,开发者的控制度更高,也就是说开发者更容易写出性能好又强大的正则来,当然也更容易造成性能的浪费甚至撑爆CPU。DFA引擎下的表达式,只要可能性是一样的,任何一种写法都是没有差别(可能对编译有细微的差别)的,因为对DFA引擎来说,表达式其实是死的。而NFA引擎下的表达式,高手写的正则和新手写的正则,性能可能相差10倍甚至更多。
也正是因为主导权的不同,正则中的很多概念,比如非贪婪模式、反向引用、零宽断言等只有NFA引擎才有。
所以,在表达能力上,NFA引擎秒杀DFA引擎。
当今市面上大多数正则引擎都是NFA引擎,应该就是胜在表达能力上。
但是因为NFA引擎比较灵活,很多语言在实现上有细微的差别。所以后来大家弄了一个标准,符合这个标准的正则引擎就叫做POSIX NFA引擎,其余的就只能叫做传统型NFA引擎咯。
我们来看看JavaScript到底是哪种引擎类型吧。
'123456'.match(/\d{3,6}/);
// ["123456", index: 0, input: "123456", groups: undefined]
'123456'.match(/\d{3,6}?/);
// ["123", index: 0, input: "123456", groups: undefined]
《精通正则表达式》书中说POSIX NFA引擎不支持非贪婪模式,很明显JavaScript不是POSIX NFA引擎。
区分DFA引擎与传统型NFA引擎就简单咯,捕获组你有么?花式零宽断言你有么?
结论就是:JavaScript的正则引擎是传统型NFA引擎。
NFA的回溯机制
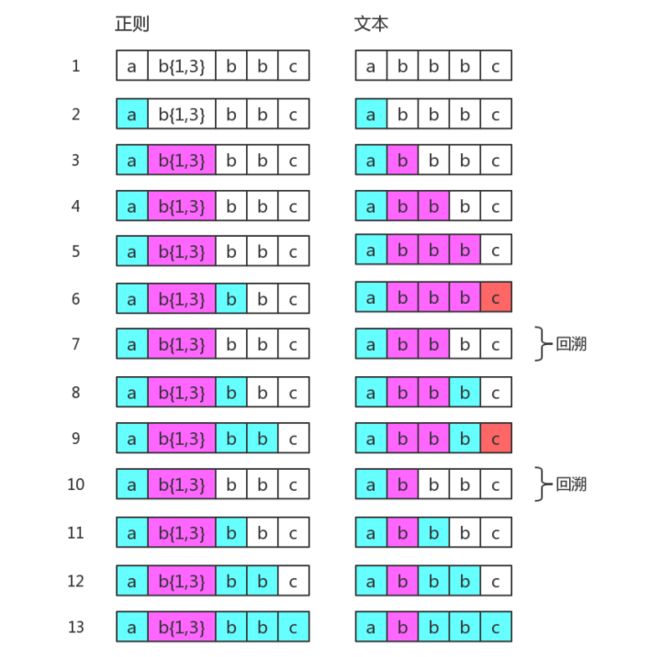
举个例子来看一下NFA的回溯机制
假设我们的正则是 /ab{1,3}c/,而当目标字符串是 "abbbc" 时,就没有所谓的“回溯”。其匹配过程是:

如果目标字符串是"abbc",中间就有回溯。其匹配过程是:

再举个栗子: /ab{1,3}bbc/ 目标字符串是"abbbc",匹配过程是:
ReDoS
由于回溯机制就导致了ReDoS(Regular expression Denial of Service) 正则表达式拒绝服务攻击。
开发人员使用了正则表达式来对用户输入的数据进行有效性校验, 当编写校验的正则表达式存在缺陷或者不严谨时, 攻击者可以构造特殊的字符串来大量消耗服务器的系统资源,造成服务器的服务中断或停止。
每个恶意的正则表达式模式应该包含:
-
使用重复分组构造
-
在重复组内会出现
-
重复
-
交替重叠
有缺陷的正则表达式会包含如下部分:
-
(a+)+
-
([a-zA-Z]+)*
-
(a|aa)+
-
(a|a?)+
-
(.*a){x} | for x > 10
注意: 这里的a是个泛指
实例
下面我们来展示一些实际业务场景中会用到的缺陷正则。
-
英文的个人名字:
- Regex: ^[a-zA-Z]+(([\'\,\.\-][a-zA-Z ])?[a-zA-Z])$
- Payload: aaaaaaaaaaaaaaaaaaaaaaaaaaaa!
-
Java Classname
- Regex: ^(([a-z])+.)+A-Z+$
- Payload: aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa!
-
Email格式验证
- Regex: ^(0-9a-zA-Z@(([0-9a-zA-Z])+([-\w][0-9a-zA-Z])*\.)+[a-zA-Z]{2,9})$
- Payload: a@aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa!
-
多个邮箱地址验证
- Regex: ^[a-zA-Z]+(([\'\,\.\-][a-zA-Z ])?[a-zA-Z])\s+<(\w[-._\w]\w@\w[-._\w]\w\.\w{2,3})>$|^(\w[-._\w]\w@\w[-._\w]\w\.\w{2,3})$
- Payload: aaaaaaaaaaaaaaaaaaaaaaaa!
-
复数验证
- Regex: ^\d*0-9*$
- Payload: 1111111111111111111111111!
-
模式匹配
- Regex: ^([a-z0-9]+([\-a-z0-9][a-z0-9]+)?\.){0,}([a-z0-9]+([\-a-z0-9][a-z0-9]+)?){1,63}(\.[a-z0-9]{2,7})+$
- Payload: aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa!
防范手段只是为了降低风险而不能百分百消除 ReDoS 这种威胁。当然为了避免这种威胁的最好手段是尽量减少正则在业务中的使用场景或者多做测试, 增加服务器的性能监控等。
-
降低正则表达式的复杂度, 尽量少用分组
-
严格限制用户输入的字符串长度(特定情况下)
-
使用单元测试、fuzzing 测试保证安全
-
使用静态代码分析工具, 如: sonar
-
添加服务器性能监控系统, 如: zabbix
几个正则可视化与检测网站
可视化工具
-
https://jex.im/regulex
-
https://regexper.com (网络需自由)
-
- https://aoxiaoqiang.github.io/reg (替代工具)
-
https://www.debuggex.com
检测网站
-
https://regex101.com/
参考链接
-
《JavaScript 正则表达式迷你书》
-
https://cloud.tencent.com/developer/article/1041326
-
https://cloud.tencent.com/developer/article/1529463
-
https://juejin.im/post/5becc2aef265da6110369c93