MySQL 存储过程和存储引擎
1. 存储过程
存储过程是 SQL 语句和控制语句的预编译集合,以一个名称存储并作为一个单元处理。
存储过程的优点:
- 增强 SQL 语句的功能和灵活性
- 实现较快的执行速度
- 减少网络流量
1.1 创建
创建存储过程语法:
CREATE [DEFINER = {user|CURRENT_USER}] PROCEDURE sp_name ([proc_parameter[,...]]) [characteristic ...] routine_body
proc_parameter:[IN|OUT|INOUT] param_name type参数
IN: 表示该参数的值必须在调用存储过程时指定;
OUT: 表示该参数的值可以被存储过程改变,并且可以返回;
INOUT: 表示该参数的值调用时指定,并且可以被改变和返回。
PS: 和创建函数类似。
过程体特点:
- 过程体由合法的 SQL 语句组成;
- 过程体可以是任意 SQL 语句;
- 过程体如果为复合结构则使用 BEGIN…END 语句;
- 复合结构可以包含声明,循环,控制结构。
例如创建一个无参的存储过程:
mysql> CREATE PROCEDURE sp1() SELECT VERSION;这里将 SELECT VERSION; 作为一个存储过程。
1.2 调用
调用存储过程的语法:
含参:CALL sp_name([parameter[,...]])
无参:CALL sp_name[()]例如,调用上面创建的无参存储过程 sp1:mysql> CALL sp1;
效果如下:
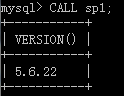
1.3 删除
删除存储过程 sp1:mysql> DROP PROCEDURE sp1;
1.4 含参存储过程
下面是含参存储过程的用法,较无参的略复杂。
修改分隔符语句:
mysql> DELIMITER //这里修改成了 //,也可修改为其他符号。
- 含一个参数的存储过程
这里创建含一个 IN 类型参数的存储过程(已修改分隔符为 //)。
mysql> CREATE PROCEDURE removeUserById(IN id INT UNSIGNED)
-> BEGIN
-> DELETE FROM users WHERE id = id;
-> END
-> //注意这里的两个 id 含义不同,前者为表的字段名 id,后者为定义的参数 id.
然而这样做是有问题的,调用后会把表中的数据全部删除!
因此使用的时候参数不能和表中的字段名相同。需要删除存储过程重新来过:
mysql> CREATE PROCEDURE removeUserById(IN p_id INT UNSIGNED)
-> BEGIN
-> DELETE FROM user WHERE id = p_id;
-> END
-> //调用:mysql> CALL removeUserById(2);
接下里查看效果,原来的表:
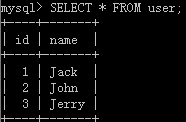
调用后的表:
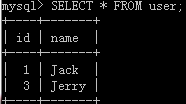
- 含两个参数的存储过程
这里有两个参数,分别为 IN 和 OUT 类型。
mysql> CREATE PROCEDURE remUserReturnNums(IN p_id INT UNSIGNED, OUT nums INT UNSIGNED)
-> BEGIN
-> DELETE FROM user WHERE id = p_id;
-> SELECT COUNT(id) FROM user INTO nums;
-> END
-> //调用存储过程:
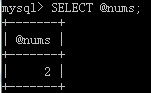
mysql> CALL remUserReturnNums(3, @nums);注:这里的调用方式和前面略有不同,其中的 @nums 为用户变量(名字可随意取,作用类似编程语言中的全局变量或成员变量)。
查看调用后的效果,原表:
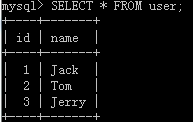
查看效果:
- 含三个参数的存储过程
这里有三个参数,分别为 IN, OUT, OUT 类型。
mysql> CREATE PROCEDURE removeUserByAge(IN p_age SMALLINT UNSIGNED, OUT deleteNums SMALLINT UNSIGNED, OUT count SMALLINT UNSIGNED)
-> BEGIN
-> DELETE FROM user WHERE age = p_age;
-> SELECT ROW_COUNT() INTO deleteNums;
-> SELECT COUNT(id) FROM user INTO count;
-> END
-> //需要注意的是,第三个 SQL 语句必须要加 FROM id,否则会出错。
其中,ROW_COUNT() 表示被更新记录的行数,用法:
mysql> SELECT ROW_COUNT();调用:mysql> CALL removeUserByAge(23, @a, @b)//
查看:
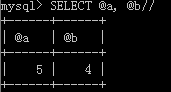
这两个参数表示删除了5个,还剩下4个。
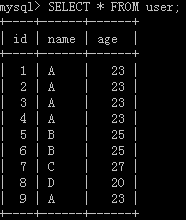
原表:
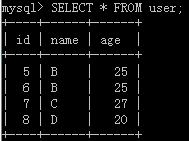
调用后结果:
存储过程与自定义函数的区别:
1. 存储过程实现的功能复杂些;函数的针对性更强。
2. 存储过程可以返回多个值;函数只有一个返回值。
3. 存储过程一般独立的来执行;而函数可以作为其他 SQL 语句的组成部分来实现。
2. 存储引擎
MySQL 可以将数据以不同的技术存储在文件(内存)中,这种技术就成为存储引擎。存储引擎就是一种存储和查询数据的技术。
每一种存储引擎使用不同的存储机制,索引技巧,锁定水平,最终提供广泛且不同的功能。
2.1 存储引擎种类
存储引擎主要有以下几种:
- MyISAM
- InnoDB
- Memory
- CSV
- Archive
2.2 并发处理
并发控制:当多个数据对记录进行修改时,保证数据的一致性和完整性。
锁:
- 共享锁(读锁):在同一时间段内,多个用户可以读取同一个资源,读取过程中数据不变。
- 排它锁(写锁):在任何时候只能有一个用户写入资源,当进行写锁时会阻塞其他的读锁或者写锁操作。
2.3 锁颗粒
锁颗粒又锁粒度,分两种:
1. 表锁:一种开销最小的锁策略。
2. 行锁:一种开销最大的锁策略。
2.4 事务的特性
- 原子性()
- 一致性
- 隔离性
- 持久性
2.5 索引
索引是对数据表中一列或多列的值进行排序的一种结构。可以比作一本书的目录。
2.6 设置存储引擎
- 在配置文件(my.ini)中更改
- 建表时设置,例如:
mysql> CREATE TABLE hi(
-> id SMALLINT
-> )ENGINE = MyISAM;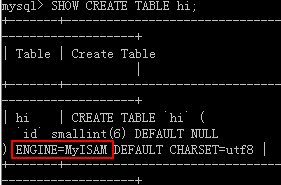
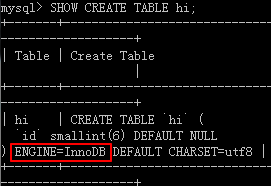
3. 建表之后更改,例如:
mysql> ALTER TABLE hi ENGINE = InnoDB;再查看,如下所示:
慕课网 MySQL 学习笔记