机器学习笔记2—— 欠拟合与过拟合
局部加权回归
现在思考关于根据实数 x 预测 y 的问题。
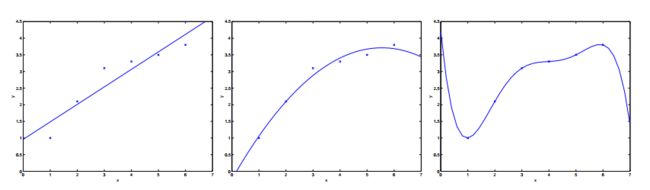
上图中最左侧的图显示了函数 y=θ0+θ1x 拟合数据集的结果。我们可以看到数据并没有真的停靠在直线上,所以这种拟合效果并不是非常好。
相反地,如果我们添加额外的特征 x2 ,然后用函数拟合 y=θ0+θ1x1+θ2x2 ,我们会得到一个稍微更好的拟合数据的结果(看中间的图)。看上去我们添加的特征越多,拟合的效果就越好。然而,添加过多的特征也有问题。最右侧的图中显示了包含五个特征的函数的拟合结果 y=∑5j=0θjxj 。我们可以看到即使拟合的曲线完美的经过了所有的数据点,我们也不会认为这是一个非常好的预测房价的假设。
在没有正式定义这种现象代表什么的前提下,我们称左侧图是欠拟合的案例,即创建的模型明显没有捕获到数据;称右侧图中的现象为 过拟合 的例子(这节课之后我们会介绍规定的这些符号的一些理论知识,并且会更小心的定义,对于一个假设来说这究竟意味着是好的还是坏的)。
综上的案例与讨论,我们意识到特征的选择对确保一个学习算法表现良好非常重要(当我们讨论到模型选择时,我们也会了解一些自动选择良好特征的算法)。
在这一小节中,我们要讨论关于局部加权线性回归(LWR)算法,这种算法在训练数据足够的前提下,能削弱特征选择的影响。这一过程比较简短,更多关于LWR算法的特性需要你们在作业中发现。
在原始的线性回归算法中,为了对一系列输入值 x 做出预测,我们会:
- 调整参数 θ 以最小化 ∑i(yi−θTxi)2
2.输出 θTx
相反的是,局部加权线性回归算法执行下列步骤:
- 调整参数 θ 以最小化 ∑iw(i)(y(i)−θTx(i))2
2.输出 θTx
这里的 w(i) 是非负的权值。可以看出,如果对于特定值 i 权值 w(i) 非常大,无论如何取 θ ,我们都很难让 (y(i)−θTx(i))2 减小。如果权值很小,那么误差项 (y(i)−θTx(i))2 在拟合过程中会被忽略掉。
对于权值来说一个恰当的选择是:
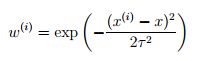
要知道权值的大小取决于我们尝试预测的特定点 x 。如果 |x(i)−x| 很小,那么权值 w(i) 会趋近于1;相反如果如果 |x(i)−x| 很大,权值 w(i) 会很小,因此,参数 θ 应该调整为越靠近查询点 x 的训练样本权值越高。(要知道尽管权值的表现形式与高斯分布相似,但权值 w(i) 与高斯分布并没有直接关系,且权值 w(i) 也不是随机变量、正态分布或是其他形式的分布。)随着训练样本与查询点 x 距离越远,参数 τ 控制权值下降的速度。 τ 被称作带宽参数,这一符号的概念需要你们做作业去了解。
局部加权线性回归是我们了解到的第一个非参数算法的例子。我们之前知道的(未加权)线性回归属于参数学习算法,因为在拟合数据的过程中,存在需要不断调整、且数量有限的参数( θi ’s)。一旦我们确定并存储这些参数 θi ’s,我们不会继续维持着数据集来做预测。相反,通过局部加权线性回归算法做预测,需要一直维持着整个数据集。非参数算法的形式指出了事实:随着做预测的数据集的规模越大,需要维持的数量级就越多。
概率解释
当我们面对回归问题时,为什么会认为线性回归和最小二乘成本函数J可能是合理的选择呢?在这一小节,我们会给出一系列的概率解释,根据最小二乘回归推导出一个非常自然的算法。
假设目标变量和输入变量之间的关系由如下等式表示:
等式中的 ε(i) 代表误差项,用来捕获未建模的影响(比如如果有一些与预测房价非常相关的特征,但我们并没有选择)或是随机噪声。根据高斯分布(也叫做正态分布)的零均值和方差 σ2 ,可以进一步假设 ε(i) 是独立同分布的(独立且相同的分布)。
疑问:为什么符合高斯分布呢?吴恩达的解释有两个:1.便于数学处理 2.中心极限定理等众多理论可以证明,高斯分布是一个合理的假设。
可以将上述假设写成 ε(i) ~ N(0,σ2) ,即误差项 ε(i) 的概率密度函数如下:
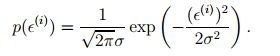
这意味着:

符号 p(y(i)|x(i);θ) 讲义中的解读解释如下:this is the distribution of y(i) given x(i) and parameterized by θ 。可解释为在给出 x(i) 的前提下,以 θ 为参数的概率。
我们不能以 θ 为条件( p(y(i)|x(i);θ) ),因为 θ 不是一个随机变量。我们也可以将 y(i) 的分布写成 y(i)|x(i);θ ~ N(θTx(i),σ2) .
拟合模型
在给出X(设计矩阵,包括所有的 x(i) )和参数 θ 的前提下如何得到 y(i) 的分布呢?数据的概率为 p(y|X;θ) 。可以看做对于固定参数值 θ 的函数 y 。当我们认为这是一个关于 θ 的函数,我们会称之为似然函数:
因为每个误差项之间都是独立的(误差项对应的y值同样如此),所以等式同样可以写成:
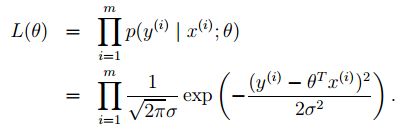
现在,给出这样的概率模型,如何选择一种合理的方式选择最佳参数 θ 呢?最大似然估计的原则就是:挑选出的参数 θ 应该让数据出现的概率尽可能的高,也就是说,我们要选择参数 θ 使 L(θ) (似然性)最大化。
除了最大化 L(θ) ,也可以最大化 L(θ) 的任何严格递增函数。尤其是,如果最大化对数似然性,那么在求偏导的过程中比最大化似然性本身要简单的多:

因此,最大化 L(θ) 与最小化 1/2 ∑mi=1(y(i)−θTx(i)) 得到了相同的结果,我们可以认出这是原始最小二乘成本函数 J(θ) 。
总结:在对数据进行概率解释的情况下,最小二乘回归对应了最大似然估计 θ 。因此,这只是众多假设之一,可以证明最小二乘回归做最大似然估计是一个非常自然的方法(概率的假设是没有必要的,最小二乘是一个非常好的和合理的算法,有可能确实有其他的自然假设可以用来证明它。)
在我们之前的讨论中,最终参数 θ 的选择并不依赖于方差 σ2 ,而且即使在方差未知的前提下我们也得到了同样结论。我们会在讲述指数家族与广义线性模型时利用这一事实。
分类与逻辑回归
现在我们将讨论分类问题。这就是一个回归问题,除了我们想要预测的 y 值是少量的离散值。
现在,我们来关注二分类问题,这里预测值只取0和1两个值(大多数我们在这里说的问题都会概括成多类案例。)举例来说,如果我们尝试创建一个邮件垃圾分类模型,那么输入变量可能是一封邮件的一些特征,而输出变量有两种情况:1表明是垃圾邮件,0表明不是。0也被称作负向类,1被称作正向类,有时会被记为符号“-”和“+”。已知输入变量 x(i) ,相应的输出变量 y(i) 被称为训练样本的标签。
逻辑回归
在忽略输出值为离散值的前提下,这个问题近似于分类问题,可以用以前的线性回归算法来尝试预测 y 。然而,很容易证明这种方式的效果非常差。直观来说,当已知 y∈{0,1} 时,预测函数 hθ(x) 取大于1或者小于0的值不会有任何意义。
为了改变这种情况,我们修改一下预测函数 hθ(x) 的格式。我们将选择:

此处有

上面的函数被称作逻辑函数或是S形曲线。
下面用图显示出函数 g(z)
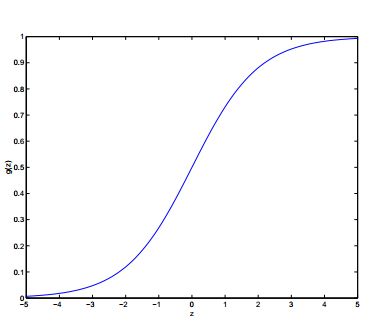
我们可以注意到,当 z→∞ ,值趋近于1,相反当 z→−∞ 时,值趋近于0。因此假设 hθ(x) 也介于值0到1之间。按照以往的习惯,我们会让 x0=1 ,所以有 θTx=θ0+∑nj=1θjxj 。
现在令函数 g 为已知,其他值在0到1之间平稳增长的函数也可以用,但是由于一系列原因我们会在之后用到(当我们讨论广义线性模型时,我们会讨论生成学习算法),逻辑算法也是自然算法中的一种。
在继续讲课之前,这里有一个关于逻辑函数导数的有用的性质,我们写作 g′ :
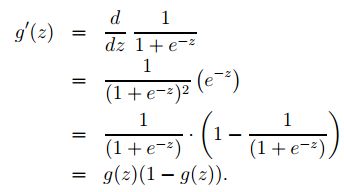
所以,给定逻辑回归模型,如何选择参数 θ 呢?我们见证了之前关于最小二乘与最大似然的假设,现在为分类模型做一组概率假设,然后通过最大似然估计调整参数值。
让我们假设:
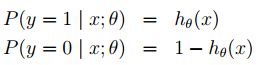
也可以更简洁的写成:
假设m个训练样本独立生成,我们可以写出关于参数的似然性:
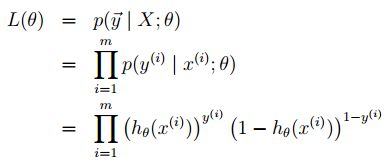
同样,非常容易最大化它的对数似然性:

我们如何最大化似然性呢?与之前的线性回归案例的求导相同,我们可以使用梯度上升方法。通过使用向量符号,得到更新的公式: θ:=θ+α▽θl(θ) (需要知道更新公式中是正号而不是负号,因为我们的目的是最大化而不是最小化。)
让我们以一组训练样本(x,y)开始,然后将导数代入随机梯度上升规则中:

上述推导公式中,我们用了公式 g′(z)=g(z)(1−g(z)) 。因此我们得到随机梯度上升规则:
如果我们把更新规则与最小二乘更新规则对比,我们会发现两者形式上是相同的;但两者其实并不是同一个算法,因为 hθ(x(i)) 在此处定义为非线性函数 θTx(i) 。但是,不同的算法和学习问题得到了同样的更新规则这一点还是让人惊讶的。这是巧合还是背后有什么深层次的原因呢?我们会在之后讲广义线性模型时回答这个疑问。
扩展:感知学习算法
现在我们要歪个楼讲一个历史遗留的感兴趣的算法,然后继续回到之前的学习理论话题。思考如果改变逻辑回归算法让其输出的值除了0就是1。为了达到这个目的,将 g 的定义改为阈值函数:
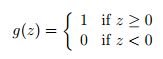
如果我们仍旧让 hθ(x(i))=g(θTx) ,但改成用这个定义的函数 g ,继续用这个更新规则
那么这就是感知学习模型
。
在1960年,“感知学习模型”在大脑个人神经元领域中并不被看好。在之后讲述学习理论是我们会讲到如何利用这一模型进行分析。还是要清楚,即便感知模型与其他算法再如何相似,它都是一个与逻辑回归、最小二乘线性回归不同类型的算法;尤其是,很难给这个算法赋予有意义的概率解释,也很难得到感知模型的最大似然估计算法。