深度学习基础之深度学习概述(一)——慕课学习笔记
1.1深度学习的引出
机器学习(Machine Lerning) 是对研究问题进行模型假设,利用计算机从训练数据中学习得到模型参数。并最终对数据进行预测和分析的一门学科。

从简单线性分类器到深度学习(一)
问题:根据繁华程度(x1)、交通便利度(x2)、与市中心距离(x3)、楼层(x4 )预
测房价的高低(x1-x4为输入,w为各个输入的权重):

则可以写出如下表达式:

从简单线性分类器到深度学习(二)
加入中间层(隐藏层)(U为中间层与输入层对应的权重,h为输出层与中间层对应的权重):

深度学习网络往往包含多个中间层(隐藏层),且网络结构要更复杂一些。
●深度学习(Deep learning) :
- 一种实现机器学习的技术,是机器学习重要的分支。
- 源于人工神经网络的研究,深度学习的模型结构是一种含多隐层的神经网络。
- 通过组合低层特征形成更加抽象的高层特征。

深度学习应用领域:聊天机器人(siri)(语音识别、自然语言处理),自动驾驶,搜索引擎,计算机视觉机器人,棋类机器人(谷歌开发的AlphaGo),人脸识别等等。
1.2数据集及其拆分
lris(鸢尾花)数据集:山鸢尾(lris setosa),变色鸢尾(lris versicolor),维吉尼亚鸢尾(iris virginica)。
●每个样本包含4个特征(单位: cm), 1个类别标签(类别编码)。
●共有150个样本,3类,每类50个样本。

分类特征:花萼(sepal) 和花瓣(petal) 的宽度和长度
数据集在数学上通常表示为{(x1,y1), (x2,y2), …(xi,yi), … (xm, ym)}的形式,

类别标签的ground truth与gold standard

数据集与有监督学习

有监督学习中数据通常分成训练集、测试集两部分。
- 训练集(training set)用来训练模型,即被用来学习得到系统的参数取值。
- 测试集(testing set)用于最终报告模型的评价结果,因此在训练阶段测试集中的样本应该是unseen的。
有时对训练集做进一步划分为训练集和验证集(validation set)。验证集与测试集类似,也是用于评估模型的性能。区别是验证集主要用于模型选择和调整超参数,因而一般不用于报告最终结果。
可以使用sklearn进行训练集、测试集的拆分
可以在anaconda上安装sklearn外部库搭建环境。
训练集、测试集的拆分——留出法
- 将数据随机分为两组,一组做为训练集,一组做为测试集
- 利用训练集训练分类器,然后利用测试集评估模型,记录最后的分类准确率为此分类器的性能指标
留出法的优点是处理简单。而不足之处是在测试集上的预测性能的高低与数据集拆分情况有很大的关系,所以基于这种数据集拆分基础上的性能评价结果不够稳定。
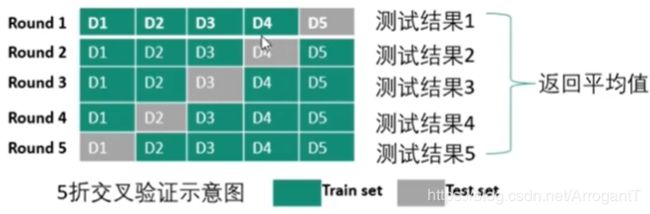
训练集、测试集的拆分——K折交叉验证
- 数据集被分成K份(K通常取5或者10)
- 不重复地每次取其中一份做测试集,用其他K-1份做训练集训练,这样会得到K个评价模型
- 将上述步骤2中的K次评价的性能均值作为最后评价结果
K折交叉验证的上述做法有助于提高评估结果的稳定性
分层抽样策略(Stratified k-fold)
将数据集划分成k份,特点在于,划分的k份中,每一份内各个类别数据的比例和原始数据集中各个类别的比例相同。

用网格搜索来调超参数(一)
超参数:指在学习过程之前需要设置其值的一些变量,而不是通过训练得到的参数数据。如深度学习中的学习速率等就是超参数。
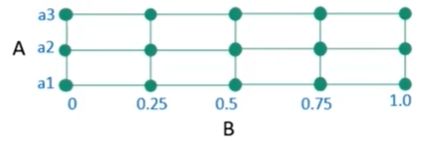
网格搜索:
假设模型中有2个超参数: A和B。A的可能取值为{a1, a2, a3}, B的可能取
值为连续的,如在区间[0-1]。由于B值为连续,通常进行离散化,如变为
{0, 0.25, 0.5, 0.75, 1.0}。
如果使用网格搜索,就是尝试各种可能的(A, B)对值,找到能使的模型取
得最高性能的(A, B)值对。
用网格搜索来调超参数(二)
网格搜索往往需要与k折交叉验证相结合:
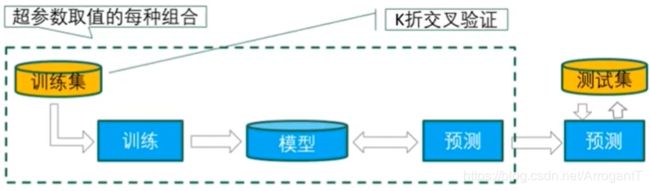
网格搜索与K折交叉验证结合调整超参数的具体步骤:
- 确定评价指标;
- 对于超参数取值的每种组合,在训练集上使用交叉验证的方法求得其K次评价的性能均值;
- 最后,比较哪种超参数取值组合的性能最好,从而得到最优超参数的取值组合。
1.3分类及其性能度量
分类问题是有监督学习的一个核心问题。分类解决的是要预测样本属于哪
个或者哪些预定义的类别。此时输出变量通常取有限个离散值。
分类的机器学习的两大阶段:
1)从训练数据中学习得到一个分类决策函数或分类模型,称为分类器(classifier) ;
2)利用学习得到的分类器对新的输入样本进行类别预测。
两类分类问题与多类分类问题。多类分类问题也可以转化为两类分类问题解决,如采用一对其余(One-Vs- Rest)的方法:将其中一个类标记为正类,然后将剩余的其它类都标记成负类。
分类性能度量一准确率
假设只有两类样本,即正例(positive)和负例(negative)。通常以关注
的类为正类,其他类为负类:

表中AB模式:第二个符号表示预测的类别,第一个表示预测结果对了(True)还是错了(False)

分类性能度量一精确率和召回率

精确率反映了模型判定的正例中真正正例的比重。在垃圾短信分类器中,是指预测出的垃圾短信中真正垃圾短信的比例。
召回率反映了总正例中被模型正确判定正例的比重。医学领域也叫做灵敏度(sensitivity) 。在垃圾短信分类器中,指所有真的垃圾短信被分类器正确找出来的比例。
分类性能度量一P-R曲线


要得到P-R曲线,需要一系列Precision和Recall的值。这些系列值是通过阈值来形成的。对于每个测试样本,分类器一般都会给了“Score”值,表示该样本多大概率上属于正例。
绘制P-R曲线:
- 从高到低将“Score"值排序并依此作为阈值threshold;
- 对于每个阈值,“Score"值大于或等于这个threshold的测试样本被认为正例,其它为负例。从而形成一组预测数据。

阈值为0.9:

阈值为0.8:

等等,每次调整都计算一组Precision和Recall的值,对应P-R曲线上的点。
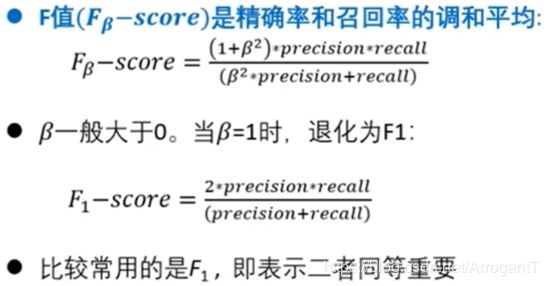
分类性能度量一F值
分类性能度量—ROC


ROC曲线绘制步骤与P-R曲线绘制类似,只需每次更改阈值,依据公式算出对应值即可。
分类性能度量一ROC-AUC计算

分类性能可视化


分类报告
分类报告(lassification report)显示每个类的分类性能。包括每个类标签的精确率、召回率、F1值等。
