语义分割之《CCNet: Criss-Cross Attention for Semantic Segmentation》论文阅读笔记
论文地址:CCNet: Criss-Cross Attention for Semantic Segmentation
代码地址:CCNet github
文章目录
- 一、简介
- 二、结构
- 1、CCNet结构
- 2、Criss-Cross Attention
- 3、Recurrent Criss-Cross Attention
- 4、代码
- 三、结果
一、简介
CCNet是2018年11月发布的一篇语义分割方面的文章中提到的网络,该网络有三个优势:
- GPU内存友好;
- 计算高效;
- 性能好。
CCNet之前的论文比如FCNs只能管制局部特征和少部分的上下文信息,空洞卷积只能够集中于当前像素而无法生成密集的上下文信息,虽然PSANet能够生成密集的像素级的上下文信息但是计算效率过低,其计算复杂度高达O((H*W)*(H*\W))。因此可以明显的看出,CCNet的目的是高效的生成密集的像素级的上下文信息。
Cirss-Cross Attention Block的参数对比如下图所示:

CCNet论文的主要贡献:
- 提出了Cirss-Cross Attention Module;
- 提出了高效利用Cirss-Cross Attention Module的CCNet。
二、结构
1、CCNet结构
CCNet的网络结构如下图所示:
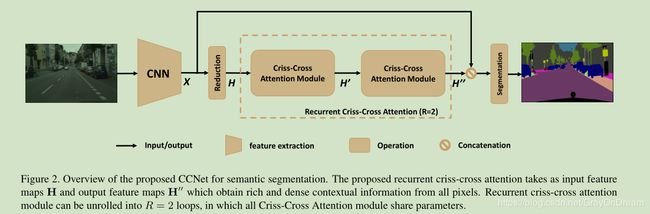
CCNet的基本结构描述如下:
- 1、图像通过特征提取网络得到feature map的大小为 H ∗ W H*W H∗W,为了更高效的获取密集的特征图,将原来的特征提取网络中的后面两个下采样去除,替换为空洞卷积,使得feature map的大小为输入图像的1/8;
- 2、feature map X分为两个分支,分别进入3和4;
- 3、一个分支先将X进行通道缩减压缩特征,然后通过两个CCA(Cirss-Cross Attention)模块,两个模块共享相同的参数,得到特征 H ′ ′ H^{''} H′′;
- 4、另一个分支保持不变为X;
- 5、将3和4两个分支的特征融合到一起最终经过upsample得到分割图像。
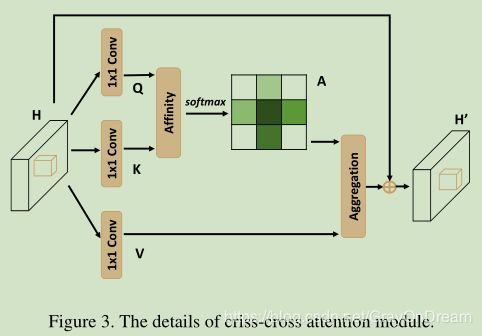
2、Criss-Cross Attention
Criss-Cross Attention模块的结构如下所示,输入feature为 H ∈ R C ∗ W ∗ H H\in \mathbb{R}^{C*W*H} H∈RC∗W∗H, H H H分为 Q , K , V Q,K,V Q,K,V三个分支,都通过1*1的卷积网络的进行降维得到 Q , K ∈ R C ′ ∗ W ∗ H {Q,K}\in \mathbb{R}^{C^{'}*W*H} Q,K∈RC′∗W∗H( C ′ < C C^{'}
d i , u = Q u Ω i , u T d_{i,u}=Q_u\Omega_{i,u}^{T} di,u=QuΩi,uT
其中 Q u ∈ R C ′ Q_u\in\mathbb{R}^{C^{'}} Qu∈RC′是在特征图Q的空间维度上的u位置的值。 Ω u ∈ R ( H + W − 1 ) C ′ \Omega_u\in\mathbb{R}^{(H+W-1)C^{'}} Ωu∈R(H+W−1)C′是 K K K上 u u u位置处的同列和同行的元素的集合。因此, Ω u , i ∈ R C ′ \Omega_{u,i}\in\mathbb{R}^{C^{'}} Ωu,i∈RC′是 Ω u \Omega_u Ωu中的第 i i i个元素,其中 i = [ 1 , 2 , . . . , ∣ Ω u ∣ ] i=[1,2,...,|\Omega_u|] i=[1,2,...,∣Ωu∣]。而 d i , u ∈ D d_{i,u}\in D di,u∈D表示 Q u Q_u Qu和 Ω i , u \Omega_{i,u} Ωi,u之间的联系的权重, D ∈ R ( H + W − 1 ) ∗ W ∗ H D\in \mathbb{R}^{(H+W-1)*W*H} D∈R(H+W−1)∗W∗H。最后对 D D D进行在通道维度上继续进行softmax操作计算Attention Map A A A。
另一个分支 V V V经过一个1*1卷积层得到 V ∈ R C ∗ W ∗ H V \in \mathbb{R}^{C*W*H} V∈RC∗W∗H的适应性特征。同样定义 V u ∈ R C V_u \in \mathbb{R}^C Vu∈RC和 Φ u ∈ R ( H + W − 1 ) ∗ C \Phi_u\in \mathbb{R}^{(H+W-1)*C} Φu∈R(H+W−1)∗C, Φ u \Phi_u Φu是 V V V上u点的同行同列的集合,则定义Aggregation操作为:
H u ′ ∑ i ∈ ∣ Φ u ∣ A i , u Φ i , u + H u H_u^{'}\sum_{i \in |\Phi_u|}{A_{i,u}\Phi_{i,u}+H_u} Hu′i∈∣Φu∣∑Ai,uΦi,u+Hu
该操作在保留原有feature的同时使用经过attention处理过的feature来保全feature的语义性质。
3、Recurrent Criss-Cross Attention
单个Criss-Cross Attention模块能够提取更好的上下文信息,但是下图所示,根据criss-cross attention模块的计算方式左边右上角蓝色的点只能够计算到和其同列同行的关联关系,也就是说相应的语义信息的传播无法到达左下角的点,因此再添加一个Criss-Cross Attention模块可以将该语义信息传递到之前无法传递到的点。

采用Recurrent Criss-Cross Attention之后,先定义loop=2,第一个loop的attention map为 A A A,第二个loop的attention map为 A ′ A^{'} A′,从原feature上位置 x ′ , y ′ x^{'},y^{'} x′,y′到权重 A i , x , y A_{i,x,y} Ai,x,y的映射函数为 A i , x , y = f ( A , x , y , x ′ , y ′ ) A_{i,x,y}=f(A,x,y,x^{'},y^{'}) Ai,x,y=f(A,x,y,x′,y′),feature H H H中的位置用 θ \theta θ表示,feature中 H ′ ′ H^{''} H′′用 u u u表示,如果 u u u和 θ \theta θ相同则:
H u ′ ′ ← [ f ( A , u , θ ) + 1 ] ⋅ f ( A ′ , u , θ ) ⋅ H θ H_u^{''}\leftarrow[f(A,u,\theta)+1]\cdot f(A^{'},u,\theta)\cdot H_{\theta} Hu′′←[f(A,u,θ)+1]⋅f(A′,u,θ)⋅Hθ
其中 ← \leftarrow ←表示加到操作,如果 u u u和 θ \theta θ不同则:
H u ′ ′ ← [ f ( A , u x , θ y , θ x , θ y ) ⋅ f ( A ′ , u x , u y , u x , θ y ) + f ( A , θ x , u y , θ x , θ y ) ⋅ f ( A ′ , u x , u y , θ x , θ y ) ] ⋅ H θ H_u^{''}\leftarrow[f(A,u_x,\theta_{y}, \theta_{x}, \theta_{y})\cdot f(A^{'},u_x,u_{y}, u_{x}, \theta_{y})+f(A,\theta_x,u_{y}, \theta_{x}, \theta_{y})\cdot f(A^{'},u_x,u_{y}, \theta_{x}, \theta_{y})]\cdot H_{\theta} Hu′′←[f(A,ux,θy,θx,θy)⋅f(A′,ux,uy,ux,θy)+f(A,θx,uy,θx,θy)⋅f(A′,ux,uy,θx,θy)]⋅Hθ
Cirss-Cross Attention模块可以应用于多种任务不仅仅是语义分割,作者同样在多种任务中使用了该模块,可以参考论文。
4、代码
下面是Cirss-Cross Attention模块的代码可以看到ca_weight便是Affinity操作,ca_map便是Aggregation操作。
class CrissCrossAttention(nn.Module):
""" Criss-Cross Attention Module"""
def __init__(self,in_dim):
super(CrissCrossAttention,self).__init__()
self.chanel_in = in_dim
self.query_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
self.key_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim//8 , kernel_size= 1)
self.value_conv = nn.Conv2d(in_channels = in_dim , out_channels = in_dim , kernel_size= 1)
self.gamma = nn.Parameter(torch.zeros(1))
def forward(self,x):
proj_query = self.query_conv(x)
proj_key = self.key_conv(x)
proj_value = self.value_conv(x)
energy = ca_weight(proj_query, proj_key)
attention = F.softmax(energy, 1)
out = ca_map(attention, proj_value)
out = self.gamma*out + x
return out
Affinity操作定义如下:
class CA_Weight(autograd.Function):
@staticmethod
def forward(ctx, t, f):
# Save context
n, c, h, w = t.size()
size = (n, h+w-1, h, w)
weight = torch.zeros(size, dtype=t.dtype, layout=t.layout, device=t.device)
_ext.ca_forward_cuda(t, f, weight)
# Output
ctx.save_for_backward(t, f)
return weight
@staticmethod
@once_differentiable
def backward(ctx, dw):
t, f = ctx.saved_tensors
dt = torch.zeros_like(t)
df = torch.zeros_like(f)
_ext.ca_backward_cuda(dw.contiguous(), t, f, dt, df)
_check_contiguous(dt, df)
return dt, df
Aggregation操作定义如下:
class CA_Map(autograd.Function):
@staticmethod
def forward(ctx, weight, g):
# Save context
out = torch.zeros_like(g)
_ext.ca_map_forward_cuda(weight, g, out)
# Output
ctx.save_for_backward(weight, g)
return out
@staticmethod
@once_differentiable
def backward(ctx, dout):
weight, g = ctx.saved_tensors
dw = torch.zeros_like(weight)
dg = torch.zeros_like(g)
_ext.ca_map_backward_cuda(dout.contiguous(), weight, g, dw, dg)
_check_contiguous(dw, dg)
return dw, dg
其中使用ext是c库文件:

RCC模块的实现如下所示:
class RCCAModule(nn.Module):
def __init__(self, in_channels, out_channels, num_classes):
super(RCCAModule, self).__init__()
inter_channels = in_channels // 4
self.conva = nn.Sequential(nn.Conv2d(in_channels, inter_channels, 3, padding=1, bias=False),
InPlaceABNSync(inter_channels))
self.cca = CrissCrossAttention(inter_channels)
self.convb = nn.Sequential(nn.Conv2d(inter_channels, inter_channels, 3, padding=1, bias=False),
InPlaceABNSync(inter_channels))
self.bottleneck = nn.Sequential(
nn.Conv2d(in_channels+inter_channels, out_channels, kernel_size=3, padding=1, dilation=1, bias=False),
InPlaceABNSync(out_channels),
nn.Dropout2d(0.1),
nn.Conv2d(512, num_classes, kernel_size=1, stride=1, padding=0, bias=True)
)
def forward(self, x, recurrence=1):
output = self.conva(x)
for i in range(recurrence):
output = self.cca(output)
output = self.convb(output)
output = self.bottleneck(torch.cat([x, output], 1))
return output
CCNet的整体结构:
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes):
self.inplanes = 128
super(ResNet, self).__init__()
self.conv1 = conv3x3(3, 64, stride=2)
self.bn1 = BatchNorm2d(64)
self.relu1 = nn.ReLU(inplace=False)
self.conv2 = conv3x3(64, 64)
self.bn2 = BatchNorm2d(64)
self.relu2 = nn.ReLU(inplace=False)
self.conv3 = conv3x3(64, 128)
self.bn3 = BatchNorm2d(128)
self.relu3 = nn.ReLU(inplace=False)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.relu = nn.ReLU(inplace=False)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=True) # change
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=1, dilation=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=1, dilation=4, multi_grid=(1,1,1))
#self.layer5 = PSPModule(2048, 512)
self.head = RCCAModule(2048, 512, num_classes)
self.dsn = nn.Sequential(
nn.Conv2d(1024, 512, kernel_size=3, stride=1, padding=1),
InPlaceABNSync(512),
nn.Dropout2d(0.1),
nn.Conv2d(512, num_classes, kernel_size=1, stride=1, padding=0, bias=True)
)
def forward(self, x, recurrence=1):
x = self.relu1(self.bn1(self.conv1(x)))
x = self.relu2(self.bn2(self.conv2(x)))
x = self.relu3(self.bn3(self.conv3(x)))
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x_dsn = self.dsn(x)
x = self.layer4(x)
x = self.head(x, recurrence)
return [x, x_dsn]
三、结果
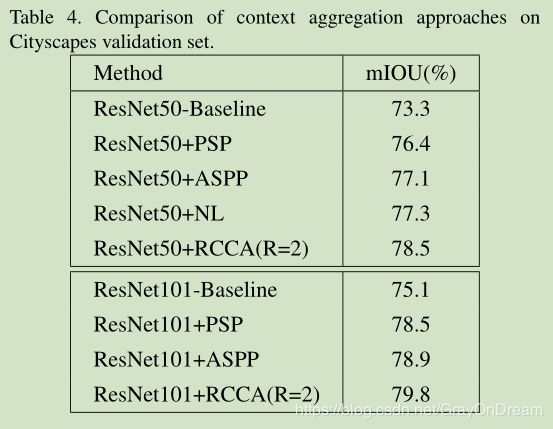
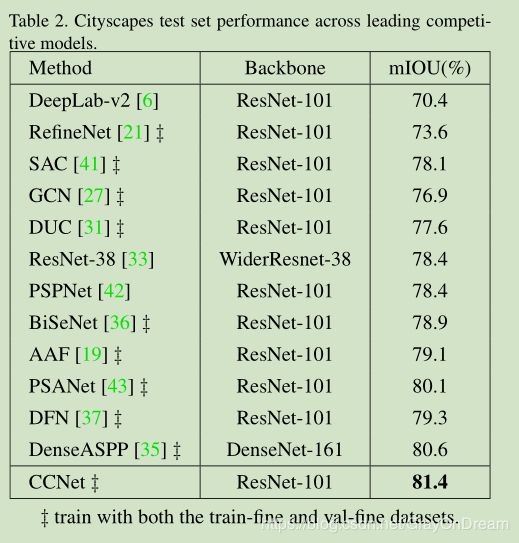
与主流的方法的比较:
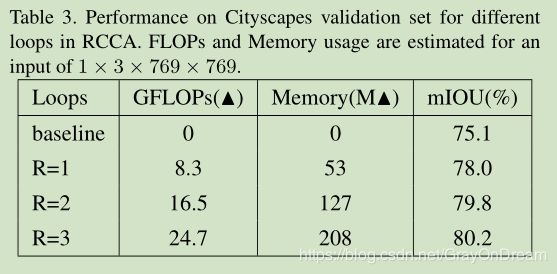
下面是不同loop时的效果可以看到loop=2时的效果要比loop=2好。下面是不同loop的attention map。