Spark原理及理解
Spark原理及理解
Spark简述
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
--摘自百度百科
Spark与Hadoop的对比

Spark生态
Spark Core :包含Spark的基本功能;尤其是定义RDD的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和Spark Core之上的
Spark SQL:提供了类SQL的查询,与Spark进行交互的API,类似于Hive
Spark Streaming:SparkStreaming 是一个基于SparkCore之上的实时计算框架,可以从很多数据源消费数据并对数据进行实时的处理,具有高吞吐量和容错能力强等特点
MLlib:一个机器学习算法库,提供机器学习的各种模型和调优
GraphX:提供基于图的算法
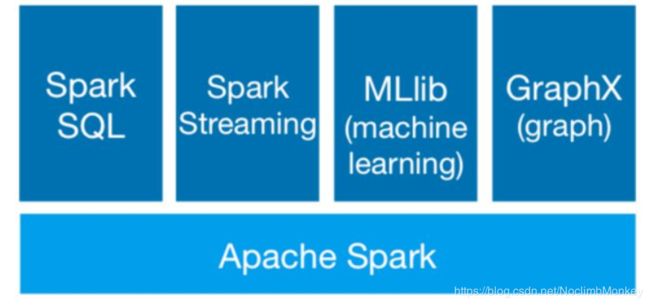
Spark架构
相关术语:
–Application:基于Spark的用户程序,其中包括一个 Driver 功能的代码和分布在集群中多个节点上运行的 Executor 代码。
–Driver:运行Application的main()函数并且创建SparkContext
–Executor:某个Application运行在worker节点上的一个进程, 该进程负责运行某些Task,可以理解为Spark资源返回的抽象形式
–Cluster Manager:在集群上获取资源的外部服务
RDD:弹性分布式数据集,分布式内存的一个抽象概念
DAG:有向无环图,反映RDD之间的依赖关系和执行流程
JOB:作业,按照DAG执行就是一个作业,job = DAG
task:任务,运行在Executor上的工作单元上,一个Task计算一个分区,包括piple上的一系列操作
Spark运行流程
(1)当一个Spark应用被提交时,首先需要为这个SparkApplication构建基本的运行环境,即由任务控制节点(Driver)创建一个SparkContext
(2)SparkContext向资源管理器注册申请运行Executor资源
(3)资源管理器为Executor分配资源并启动Executor进程,Executor运行情况将随着心跳发送到资源管理器上
(4)SparkContext根据RDD的依赖关系形成DAG,并提交给DAGscheduler进行解析划分成Stage,并把该Stage中的task组成的Taskset发送给TaskSchedule
(5)taskscheduler把task发放给Executor运行,同时SparkContext将应用程序代码发给Executor
(6)Executor将task丢入到线程池中,吧执行结果反馈给任务调度器,然后返回给DAG调度器,运行完毕后写入数据并释放所有资源

RDD --弹性分布式数据集
弹性分布式数据集,是Spark中的数据抽象,代表一个不可变,可分区,里面的元素可并行计算的集合
RDD提供了一个抽象的数据模型,让我们不必担心底层数据的分布式特性,只需要把具体的应用逻辑表达为一系列转换操作,不同RDD之间还可以形成依赖关系,进而实现管道化,从而避免了中间结果的存储,大大降低了数据复制,磁盘io和序列化开销,并且还提供了丰富的API
RDD主要属性(特性)
分片:一组分片(partition)/一个分区列表,数据集的基本组成单位,对于RDD来说,每一个分片都会被一个计算任务处理,分片数决定并行度
函数:RDD的计算是以分片为单位的,computer函数会被作用到每一个分区上
依赖关系:一个RDD会依赖于其他多个RDD,RDD的每一次转换都会生成一个新的RDD,所有RDD之间就会生成依赖关系,当一部分数据丢失的时候,可以通过依赖关系找回数据,这里体现了RDD的容错性
分区函数:一种是hash的,一种是基于范围的
最佳存储位置:对于一个hdfs来说,这个列表保存的就是每一个partiiton所在快的最佳存储位置,按照移动数据不如移动计算的理念,Spark在进行任务调度的时候,会尽可能选择那些存有数据的worker节点来进行计算
RDD创建方式
(1) 通过读取文件生成
val file = sc.textFile("/helloword.txt")
(2) 通过并行化的方式创建RDD
val array = Array(1,2,3,4,5)
val rdd = sc.parallelize(array)
(3)其他方式
通过其他的RDD转换而来等
RDD的操作函数主要分为两种:Transformation(转换) Action(行动算子)

Transformation转换算子返回值是另一个RDD,在进行操作的时候只会记录这样的操作,并不会马上提交进行计算
Action行动算子当遇到一个Action算子的时候数据才真正的开始计算
宽依赖:父RDD的一个分区会被子RDD的多个分区依赖(涉及到shuffle)
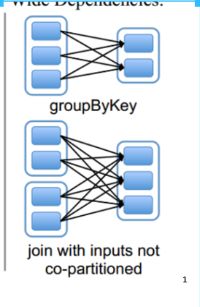
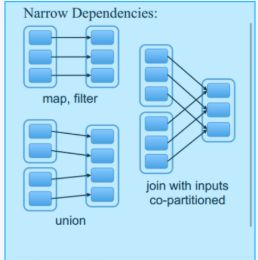
窄依赖:父RDD的一个分区只会被RDD的一个分区依赖

DAG:有向无环图
开始:通过SparkContext创建的RDD
结束:触发Action操作,一旦触发,就形成了一个完成的DAG
一个Spark应用中可以有一到多个DAG,取决于触发了多少次Action
一个DAG中会有不同阶段的stage,划分stage的依据就是宽依赖
一个stage中可以有多个task,一个分区对应一个task
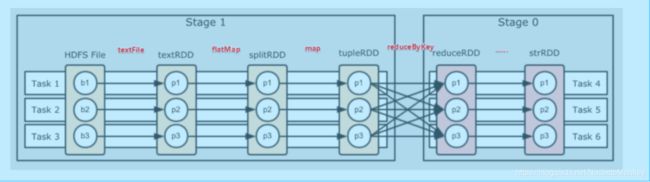
区分宽依赖和窄依赖就是看是否发生了shuffle,宽依赖会产生shuffle,类似于mapreduce,
map端操作将 RDD 里的各个元素进行映射, RDD 的各个数据元素之间不存在依赖,可以在集群的各个内存中独立计算,也就是并行化,reducebykey 之后的 Map 操作,为了计算相同 key 下的元素个数,需要把相同 key 的元素聚集到同一个 partition 下,所以造成了数据在内存中的重新分布,即 shuffle 操作.shuffle 操作是 spark 中最耗时的操作,应尽量避免不必要的 shuffle.
Spark性能调优
在网上看了很多调优的文章,根据自己的理解总结出以下几点
(1)针对资源参数方面的调优,这个需要根据自己实际的机器配置来,在提交spark任务的时候可以执行内存,核数等
(2)针对shuffle的优化,应该尽量避免shuffle操作,如果避免不了的话可以考虑使用更为优质的算子,比如在适当的时候选择reducebykey而不使用groupbykey,因为reducebykey会在map端进行预聚合,这样在发往reduce时会减少传输,提高效率,还有比如合理使用repartiiton和coalesce,如假设RDD有N个分区,需要重新划分为M个分区,
1.N小于M

像这种一般就是数据有不均匀的情况,这时就要使用shuffle为true的情况,
2.N>M
这时rdd之间是窄依赖关系,这时候就可以把shuffle关掉,提高效率
还有一些比如使用cache缓存,广播变量啊等等
spark的优化还有很多,总之就是根据原理对其中的一些步骤进行优化,提高效率,在此不再一一列举
声明:文章仅记录自己平时学习的过程的记录,如果有不对的或者侵权的地方请联系我改正,避免误导更多的人