SIGIR 2020 | 第四范式提出深度稀疏网络模型,显著提升高维稀疏表数据分类效果...

如今,在金融、零售、电商、互联网等领域的 AI 应用中,表数据都是最为常见且应用广泛的数据格式。将表数据进行准确的分类预测,对业务的提升起着至关重要的作用。
日前,第四范式提出了全新的深度神经网络表数据分类模型——深度稀疏网络(Deep Sparse Network,又名 NON),通过充分捕捉特征域内信息、刻画特征域间潜在相互作用、深度融合特征域交互操作的输出,获得超过 LR、GBDT 等常用算法以及 FFM、Wide&Deep、xDeepFM、AutoInt 等基于深度学习算法的分类效果,提升了表数据的预测准确度。

论文标题:Network On Network for Tabular Data Classificationin Real-world Applications
论文作者:罗远飞、周浩、涂威威、陈雨强、戴文渊、杨强
论文链接:https://arxiv.org/abs/2005.10114

表数据分类模型的现状
在表格数据中,每行对应一个实例(样本),每列对应一个特征域。表数据分类是根据实例的特征域,将其分到对应的类别中。表数据通常同时具有连续特征域和类别特征域,而类别特征域通常是高维稀疏的。例如在在线广告中,类别特征域“advertiser_id”可能包含数百万个不同的广告主 id。
过往,包括随机森林、GBDT 在内的树模型常用于表数据分类,它们对连续数值表数据有很好的效果,但对包含高维离散特征域的表数据不友好。一方面,树模型需要枚举所有特征域的所有特征,这对于高维的类别特征域来说效率很低。另一方面,由于类别特征域的稀缺性,对其进行分割所获得的收益较小。
因此,在实际应用场景中,对数几率回归(Logistic Regression,LR)成为了大规模稀疏表数据分类的常用方法之一,但由于其线性特性,它缺乏对特征域间非线性交互的学习能力。因此 LR 通常需要进行大量的特征工程,来刻画目标与特征域之间的非线性。
此外,FM 与 FFM 将稀疏输入特征嵌入到低维稠密向量中,并利用向量的内积显式学习特征间二阶交互。FM 和 FFM 取得了较好的效果,但由于它们的结构较浅,其表达能力也受到了限制。
近年来,基于深度学习的表格数据分类方法以其强大的表示能力和泛化能力得到了广泛的研究,并取得了一定的成功。包括 Wide&Deep、DeepFM(Deep Factorization Machine)、xDeepFM、AutoInt 在内的深度学习模型大多采用如下设计范式:
1)将每个特征域的输入映射为低维稠密向量;
2)使用 DNN 或 FM 等多种操作直接融合不同特征域对应的向量;
3)将各操作的输出进行线性加权,得到最终的预测结果。
然而此类方法有以下三个问题:
首先,现有方法直接融合不同特征域的向量表示,而未显式地考虑域内信息。我们将“每个特征域内的不同特征值,均属于同一个特征域”记为域内信息。对于每个特征域中的特征,它们的内在属性是都属于同一个特征域。
以在线广告场景为例,假设特征域 ‘advertiser_id’ 和 ‘user_id’ 分别表示广告商和用户的 ID,则特征域 ‘advertiser_id’(‘user_id’)中的不同的广告商 ID(用户 ID)都属于广告商(用户)这个特征域。此外,特征域有自己的含义,如 “advertiser_id” 和 “user_id” 分别代表广告主和用户,而不管域内特征的具体取值。
其次,大多数现有方法使用预定义的特征域交互操作组合(如 DNN、FM),而未考虑输入数据。事实上,预定义的操作组合并不适用于所有的数据,而是应该根据数据选择不同的操作,以获得更好的分类效果。
最后,现有方法忽略了特征域交互操作(如 DNN 和 FM)的输出之间的非线性。

全新模型结构带来出色的效果
为了解决上述问题,第四范式提出了深度稀疏网络,它由三部分组成:底层为域内网络(Field-wise Network),中层为域间网络(Across Field Network),顶层为融合网络(Operation Fusion Network)。
域内网络为每个特征域使用一个 DNN 来捕获域内信息,域间网络采用多种域间交互操作来刻画特征域间潜在的相互作用,最后,融合网络利用 DNN 对所选特征域交互操作的输出进行深度融合,得到最终的预测结果。

2.1 域内网络
现有的主流深度表数据分类方法中,特征域内信息没有被显示地考虑并加以利用。深度稀疏网络利用域内网络来显示地学习特征域内信息。在域内网络中,每个特征域都与一个 DNN 相连,并且每个特征域的 embedding 首先输入到该 DNN 中。鉴于 DNN 的强大的表达能力,特征域内信息可以被充分地学习。
在实际应用中,不同特征域对应的域内网络可以堆叠(stacking)起来,使用并行计算进行加速。另外,域内网络输出的 embedding 可以直接输入到域间网络,也可以通过和原始的 embedding 相互作用,来修正得到的 embedding,常见的修正方法有拼接、按位相乘、门操作等。
2.2 域间网络
域间网络采用多种交互操作来刻画特征域间的潜在相互作用,常见的特征域交互操作包括 LR、DNN、FM、Bi-Interaction 和多头自注意网络等。现有方法中,域间交互操作的方式是用户事先制定的。而在深度稀疏网络中,可以通过数据,自适应地选择最合适的操作组合,即在深度稀疏网络中,操作组合的选择是数据驱动的。
2.3 融合网络
现有的方法对不同操作的输出线性地加权求和,然后通过 sigmoid 函数得到最终的预测结果,而忽略了不同操作输出之间的非线性关系。在深度稀疏网络中,融合网络通过 DNN 对域间网络所选操作的输出进行深度融合,并得到最终的预测结果。
2.4 逐层监督训练
虽然 NON 模型结构增强了模型的表现力,但其模型复杂度也随之升高,训练更加困难。对此,第四范式引入逐层监督训练技术,即在神经网络的中间层引入额外的损失函数,使得中间层的表达更具判别性。经测试,该方案不仅能够增加模型最终预测效果,也使得模型能在更短的时间内,取得更好的效果。


实验
3.1 实验数据
本次实验共选取了六个数据集,包括三个流行的基准数据集 Criteo、Avazu、Movielens (ML-20M) ,以及三个实际业务数据集 Talkshow、Social、Sports。数据集从百万到千万级,具体统计信息如下表所示。

3.2 全新的结构设计提升泛化性能
经多个公开数据集验证,域内网络捕获的域内信息有助于提高模型的泛化性能;且随着 NON 不同的组件堆叠,模型的预测效果持续增长。
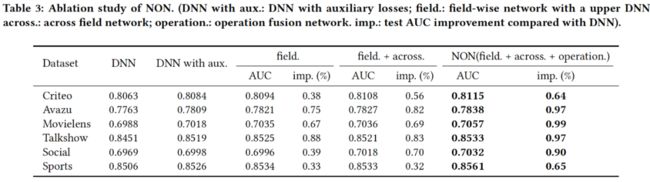
3.3 效果全面领先主流深度模型
与 FFM、DNN、Wide&Deep、NFM、xDeepFM、AutoInt 等模型相比,深度稀疏网络在实验数据集上均能获得最好的结果,AUC 可提高 0.64%~0.99%。

3.4 根据数据选定合适的特征域间交互操作
在域间网络中,深度稀疏网络将不同的交互操作视为超参数,并根据在具体数据上的预测效果,选择最适合的交互操作。其中,DNN 被视为必选,而其他操作(LR、Bi-Interaction和multi-head self-attention)被视为可选。同时,我们通过固定深度稀疏网络的其他层,只变换域间网络中不同的操作组合来进行更多验证。

可以看出没有一个操作组合能够在所有数据集上都取得最优效果,这表明了根据数据选择操作组合的必要性。而大数据集倾向于选择容量大、复杂的操作组合,小数据集倾向于轻量、简单的操作组合。
3.5 深度稀疏网络能够有效捕获域内信息
通过对域内网络处理前后特征值对应的向量进行可视化和比较,可以看出经过域内网络后,每个域内的特征在向量空间中更加接近,不同域间的特征也更容易区分。
通过进一步计算数据中特征的平均余弦距离(数值越大,相似度越高),域内网络可以使余弦距离提高一到两个量级,即能有效地捕获每个域内特征的相似性。

未来,第四范式还将基于软硬一体化技术持续优化深度稀疏网络,在保证模型效果、计算效率提升的同时,进一步降低算力成本,以推动新技术应用落地。
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
