好好学习,天天向上
本文已收录至我的Github仓库DayDayUP:github.com/RobodLee/DayDayUP,欢迎Star,更多文章请前往:目录导航
这篇文章主要是记录一下最近在学的Elasticsearch。没有什么复杂的原理,只是简单的使用。
简介
Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用Elasticsearch的水平伸缩性,能使数据在生产环境变得更有价值。Elasticsearch 的实现原理主要分为以下几个步骤,首先用户将数据提交到Elasticsearch 数据库中,再通过分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据,当用户搜索数据时候,再根据权重将结果排名,打分,再将返回结果呈现给用户。
环境搭建
这一小节主要介绍如何在docker下安装及配置Elasticsearch、IK分词器以及Kibana。
安装与配置Elasticsearch
我之所以选择在docker下安装是因为docker比较简单么,方便部署。怎么安装docker我就不说了,不知道的请自行百度。
docker pull elasticsearch:5.6.8 # 第一步肯定是要下载喽
# -d 后台运行 -i 交互式模式 9200外部访问端口http(Web管理平台端口) 9300容器端口tcp(服务默认端口)
# --name 给容器起个名字,这里叫elasticsearch
docker run -di --name=elasticsearch -p 9200:9200 -p 9300:9300 elasticsearch:5.6.8
在docker下安装就是这么简单,几行命令就搞定了。

可以看到,es可以正常访问了。但是光安装好还不行,从5.0版本开始es就默认关闭了远程连接,所以需要手动地开启远程连接。有可能我们会进行一些跨域的操作,所以还要进行跨域配置。
docker exec -it elasticsearch /bin/bash # 进入到elasticsearch容器中
cd config # 切换到config目录下
# 如果使用vi命令时出现bash: vi: command not found的话,就安装一下vim
apt-get update
apt-get install vim
vi elasticsearch.yml # 编辑配置文件,冒号后面是有一个空格的
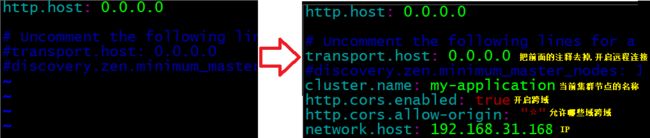
这个时候,由于虚拟机配置的问题,可能导致ES运行不起来,所以需要把系统参数调大一点。这一步是在虚拟机下操作的,不是在es容器中操作的,如果是在容器中,先输入exit命令退出容器。
vi /etc/security/limits.conf # 编辑limits.conf文件,添加两行内容

vi /etc/sysctl.conf # 编辑sysctl.conf文件,添加一行内容

OK!现在就可以了。
sysctl -p # 修改内核参数马上生效
docker update --restart=always elasticsearch # 设置开机自启
docker restart elasticsearch # 重启elasticsearch
安装IK分词器
Elasticsearch的标准分词器是不支持中文分词的。比如将“今天天气不错”进行分词,就会分成“今”,“天”,“天”,“气”,“不”,“错”。这显然是不对的,所以我们需要安装中文的分词器来支持中文。现在中文分词器用得最多的就是IK,那我们就来安装IK分词器。

从图中可以看出,5.x版本对应5.x版本的IK分词器。所以从https://github.com/medcl/elasticsearch-analysis-ik/releases里面找到和ES相同版本的IK,下载下来

下载完成之后,通过SecureFX等软件传到虚拟机里面,当然也可以敲命令发送,只不过麻烦点,位置随意,我放在了root目录下。传过之后
yum install -y unzip zip # 如果没有安装upzip的话就先安装
unzip elasticsearch-analysis-ik-5.6.8.zip # 解压,解压后的文件夹名为elasticsearch
mv elasticsearch ik # 为了方便辨认,重命名为ik,当然,不重命名或是命名为其它的也是可以的
# 安装ik的方式很简单,只要复制到es的plugins文件夹下即可
docker cp ./ik elasticsearch:/usr/share/elasticsearch/plugins
docker restart elasticsearch # 重启elasticsearch

现在分词器已经正常工作了,图中指定的分词模式为“ik_max_word”,IK还为我们提供了另外一种分词模式“ik_smart”,这种相较于前者分词粒度粗一些,前者更细。但是有可能这两种分词模式的分词结果都不是我们想要的,就可以添加自定义的词库。
docker exec -it elasticsearch /bin/bash # 进入到elasticsearch容器中
cd plugins/ik/config # 切换到ik的配置目录下
vi IKAnalyzer.cfg.xml # 编辑该文件
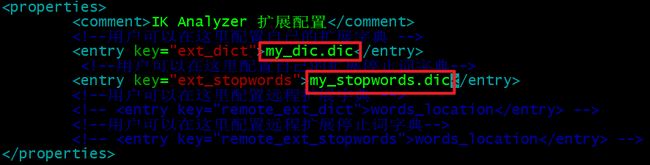
在这个文件中我们可以配置自定义词库以及停用词库。比如我们可以在my_dic.dic(在ik/config目录中)文件中添加分词
这样重启一下ES后就可以使用我们的自定义分词了。
Kibana
docker pull kibana:5.6.8 # 下载kibana的镜像
# 安装kibana
docker run -it -d -e ELASTICSEARCH_URL=http://192.168.31.168:9200 --name kibana --restart=always -p 5601:5601 kibana:5.6.8
然后通过http://192.168.31.168:5601就可以正常访问了。
基本概念
用过MySQL的都知道,我们是对表中的一行行数据进行增删查改操作,ES也是类似的,只不过我们是对文档进行增删查改操作。ES和MySQL的对应关系如下:
| MySQL(数据库服务器) | Elasticsearch(搜索引擎) |
|---|---|
| Databases(数据库) | Indices(索引库) |
| Tables(表) | Types(类型) |
| Rows(一行行的数据) | Documents(文档) |
| Columns(字段) | Fields(字段) |
Index(索引)
Elasticsearch 数据管理的顶层单位就叫做索引,它是拥有几分相似特征的文档的集合。可以理解为MySQL中的数据库。
Type(类型)
Type是索引的一个逻辑分区,就是将一些字段组合起来标识为一个Type。比如姓名、学号、班级、年级可以组合成一个Type叫做student。相当于MySQL中的数据表。
Document(文档)
文档就是Index中真实存放数据的地方,是一个信息单元。比如user这个Type有姓名、年龄、号码这三个字段。那么“张三,25,18512345678”就是一个文档。相当于MySQL中数据表中的一条数据。
Field(字段)
字段就是属性名。比如id、name、title、phone_number等。是Type的组成单位。
倒排索引
ES之所以能够实现快速,高效的搜索,是因为基于倒排索引的原理。如果我们想知道哪些网站有“腾讯老干妈”的新闻,在没有搜索引擎的帮助下我们只能一个网站一个网站找......这样拿着网站的网址(key)去找“腾讯老干妈”(value)的过程就叫做正排索引。但是平时我们百度一搜不就出来了吗。之所以我们可以这样做,是因为百度事先已经做好倒排索引了,就是把出现过“腾讯老干妈”的网站全部记录下来
| 腾讯 | 腾讯新闻,网易新闻,百度新闻,17173,哔哩哔哩........... |
|---|---|
| 老干妈 | 腾讯新闻,网易新闻,百度新闻,豆果美食 |
我们搜索“腾讯老干妈”的时候,先分词,分成“腾讯”,“老干妈”,然后去倒排索引库里面查找出url,再求出交集返回给用户。这样拿着“腾讯老干妈”(value)去查找网站(key)的过程就叫做倒排索引。
基本操作
如果我们想操作ES,可以提供的Restful接口直接访问,也就是直接发送HTTP请求,或者是在kibana中使用DSL语句,这两种方式都是可以的。比如查询索引库

创建索引及Type
当安装好MySQL之后,我们需要在里面创建数据库,然后在数据库里面创建表,再为表添加一些字段,才可以使用。同样的,在ES中,先创建索引,然后再索引里面创建一个Type,Type里面再添加一些字段。
http://192.168.31.200:9200/user # put请求 http://IP:Port/index_name
PUT /user # DSL语句 PUT /index_name
使用上面两种方式都可以创建一个叫“user”的索引,但是现在索引里面还没有数据,相当于创建了数据库还没有创建表。所以现在来创建一个Type:

使用图中的方式就可以为user所以添加一个叫sutdent的Type,可以看到,使用HTTP或者DSL语句都是一样的,所以下面就不再演示HTTP请求的方式,只演示DSL。
当然,也可以在创建索引的同时添加一个或多个Type:
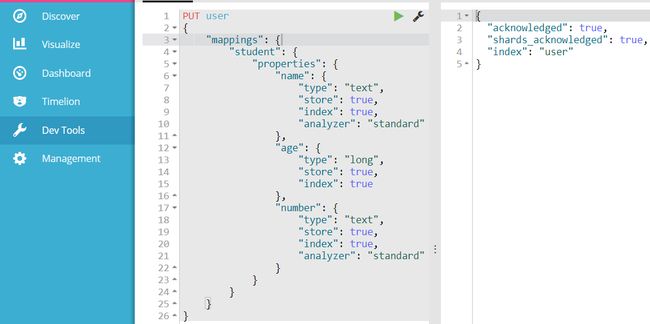
删除索引
DELETE index_name
添加文档
在MySQL中,我们添加数据是向表中添加一行行的数据,在ES中,这一条条的数据叫做Document。
POST index_name/type_name/document_id # 这个document_id是文档的id不是id字段值
{
json格式的数据
}
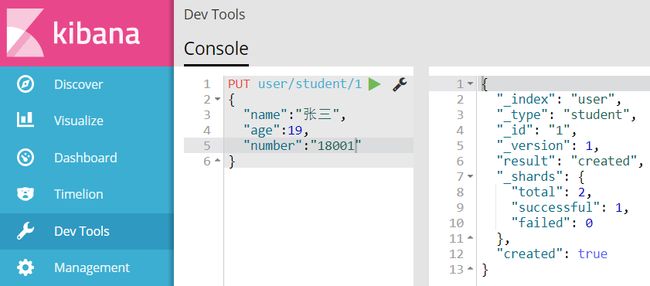
这样就成功添加了一条Document。
删除文档
DELETE index_name/type_name/document_id

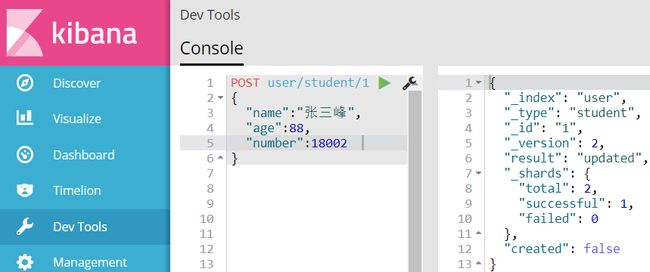
修改文档
POST index_name/type_name/document_id
数据查询
和MySQL一样,查询的内容比增删改要多得多。
查询所有数据
GET _search # 查询所有索引中的数据
GET index_name/_search # 查询一个索引下的所有数据
GET index_name/type_name/_search # 查询一个索引下的一个Type下的所有数据

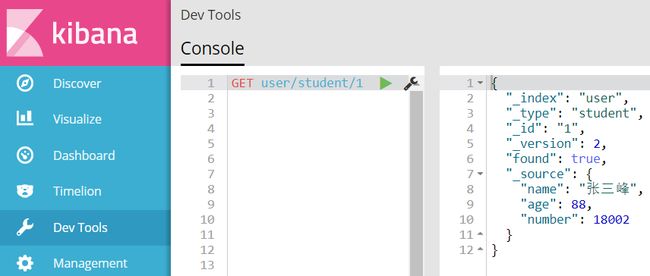
根据id查询数据
GET index_name/type_name/document_id
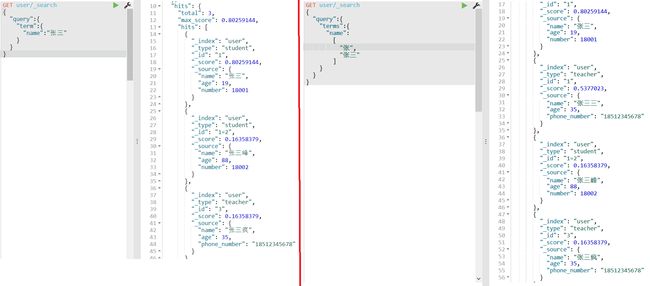
根据关键词查询
可以使用term、terms、prefix 、match和multi_match对关键词进行限制
# term是精确查询,查询过程中不会对搜索词进行分词,所以搜索词必须是文档分词集合中的一个
GET _search # 查询所有索引中的数据
或者 GET index_name/_search # 查询一个索引下的所有数据
或者 GET index_name/type_name/_search # 查询一个索引下的一个Type下的所有数据
{
"query":{
"term":{
字段名:搜索词
}
}
}
# terms 允许多个Term,也不会分词
{
"query":{
"terms":{
字段名:
[
字段值1,
字段值2
]
}
}
}
# prefix:前缀匹配,所有以特定搜索词开头的内容
GET _search
{
"query": {
"prefix": {
字段名 : 搜索词
}
}
}
# match会对搜索词进行分词,然后对分词后的结果进行搜索
GET _search
{
"query": {
"match": {
字段名: 搜索词
}
}
}
# multi_match查询允许你做match查询的基础上同时搜索多个字段
GET _search
{
"query": {
"multi_match": {
"query": 搜索词,
"fields": [
字段1,
字段2
……
]
}
}
}
- 范围搜索range
#过滤-range 范围过滤
#gt表示> gte表示=>
#lt表示< lte表示<=
GET _search
{
"query":{
"range": {
字段名: {
"gte": 30,
"lte": 57
}
}
}
}
- 查询哪些数据包含某个字段exists
GET _search
{
"query": {
"exists":{
"field":要查询的字段名
}
}
}
- 合并多个过滤条件查询结果的布尔逻辑bool
# must : 多个查询条件的完全匹配,相当于 and。
# must_not : 多个查询条件的相反匹配,相当于 not。
# should : 至少有一个查询条件匹配, 相当于 or。
GET _search
{
"query": {
"bool": {
must/must_not/should: [
{
"term"……
},
{
"range"……
}
……
]
}
}
}
- 对搜索结果排序sort
# 搜索排序
GET /user/_search
{
"query":{
…………
},
"sort":{
字段名:{
"order":"desc" # asc升序 desc 降序
}
}
}
- 对搜索结果分页
# 分页实现
# 从下标为N的数据开始查询
# size:每页显示条数
GET /user/_search
{
"query":{
…………
},
"from": 0,
"size": 2
}
总结
这篇文章并没有提什么很深奥的东西,就是对Elasticsearch的使用做了一个总结,包括怎么搭建ES的环境,介绍了倒排索引等几个概念,对索引和数据的操作。我一直认为学一项技术,一开始不用去理解其中的原理,只有先用起来才能更好地理解这项技术。所以我后期的文章再对ES会做一个更详细的介绍。
如果我的文章对你有些帮助,不要忘了点赞,收藏,转发,关注。要是有什么好的意见欢迎在下方留言。让我们下期再见!
