实在智能参与中文自然语言理解评价标准体系(CLUE)阶段性进展回顾
「实在智能」简介
「实在智能」(杭州实在智能科技有限公司)是一家人工智能科技公司,聚焦大规模复杂问题的智能决策领域,通过AI+RPA技术打造广泛应用于各行业的 智能软件机器人,即“数字员工”。助力客户提质、降本、增效,从“劳动密集型”向“AI密集型”转型,推动生产模式与业务流程实现颠覆式创新升级。
2018 年,来自纽约大学、华盛顿大学、DeepMind 等机构的研究者创建了一个多任务自然语言理解基准和分析平台——GLUE(General Language Understanding Evaluation)。GLUE 包含九个英文数据集,目前已经成为衡量模型在语言理解方面最为重要的评价体系之一。对中文 NLP 而言,之前缺少与之相对应的成熟评价体系和交流平台。
在此背景下,「实在智能」算法团队联合中文 NLP 行业专家及热心人士共同发起了“Chinese GLUE”,即中文自然语言理解评价标准体系—— CLUE benchmark(Chinese Language Understanding Evaluation Benchmark)简称为 CLUE项目。
一方面,该项目精心梳理整合中文NLP领域相关资源,助力研究人员提升工作效率和产出。另一方面,该项目希望通过建立leaderboard 榜单机制,为从业人员及爱好者提供一个高质量的衡量模型效果平台,促进行业中文语言理解能力的快速提升。
整体贡献
1.提出为中文NLP模型定制的中文语言理解测评基准,包括8大数据集、多个排行榜,促进中文数据集的标准化,便利中文模型测评和研究。
2. 开源多个数据集,包括细粒度命名实体识别(CLUENER2020)、指代消解数据集(CLUEWSC2020),论文关键词识别(CSL),丰富中文数据集。
3.提供超过100G的中文预训练语料库,发放给100+国内外科研单位,为中文NLP中的关键技术(预训练模型)发展提供充足动能。
4. 提供一系列中文预训练模型,促进预训练模型的研究。包括为国内外最受欢迎的通用NLP预训练模型transformers项目提供了11个中文模型。
5. 与中国计算机学会的中文信息技术专委合办NLPCC高性能小模型测评,推动模型小型化的研究和落地。

目录
- 现状问题描述
- 内容体系
- 排行榜
- 发布的Arxiv论文和项目介绍
- NLPCC高性能小模型测评
- 团队介绍
- 数据集介绍及有奖征集
一、现状问题描述
相对英文,中文NLP 的资源比较匮乏并缺少有价值的整合。相信很多从业人员及爱好者在推进相关工作的时候,都曾或多或少遇到过下面问题:1) 找不到官方数据集下载链接,而论文中的资源链接已过期;2)数据集有很多版本,从业者反馈结果五花八门,采信存疑;3)原始数据集需要繁琐的预处理工作;4)实验结果复线困难,预处理和模型的细节可能对最终的结果带来非常显著的影响。类似以上问题会花掉很多宝贵科研时间,严重影响工作效率,对初学者而言更是如此,提高研究门槛。
为解决上述问题,「实在智能」算法团队组织中文NLP行业专家及热心人士共同发起了 CLUE benchmark (简称为 CLUE)项目。
CLUE旨在综合形式不同、难度各异的中文自然语言理解数据集,制作一个统一的测试平台,以准确评价模型的自然语言理解能力。目前已收集了至少9大数据集,并制作了排行榜。包括华为、阿里、腾讯等知名公司,以及中科院相关院所等高校参与了测评。我们的GitHub repository已获得超过1000颗星。下面是我们的网站:
官网地址:www.CLUEbenchmark.com
Github 地址:https://github.com/CLUEbenchmark/CLUE
论文地址:https://arxiv.org/abs/2004.05986
二、内容体系
下面是CLUE 为大家整理的包含数据集、标准模型、语料库以及Python工具包:
1)收集处理了一系列性质各异的中文数据集(不同领域、不同规模、不同难度);
2)构建了在线提交评测平台即排行榜。这个平台能帮助我们横向比较不同的中文NLP 模型,为大家选择模型提供依据;
3)一些列基准模型,帮助大家轻易地复现经典模型在一系列数据集上的结果;
4)超过100G的中文预训练语料库,可用于中文预训练模型、语言模型、文本生成、语音识别等任务的训练;
5)Python工具包(PyCLUE),可以快速测评代表性数据集、基准(预训练)模型,并针对自己的数据选择合适的基准(预训练)模型进行快速应用。
三、排行榜介绍
基于一系列的中文数据集,目前已经构建了包含5个不同方向的排行榜,覆盖了分类、小模型、阅读理解、命名实体识别等不同子领域。吸引了包括华为诺亚方舟实验室& 华为云、阿里巴巴PAI、腾讯Oteam等行业内领先的团队参与测评。
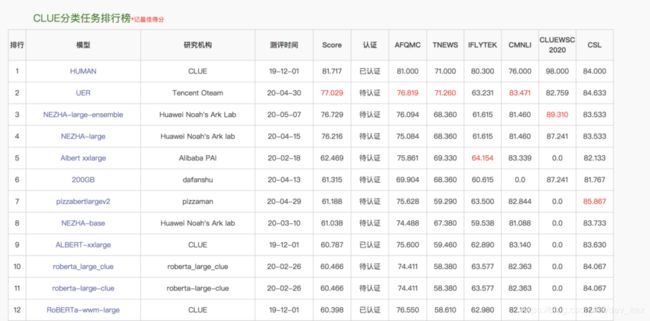
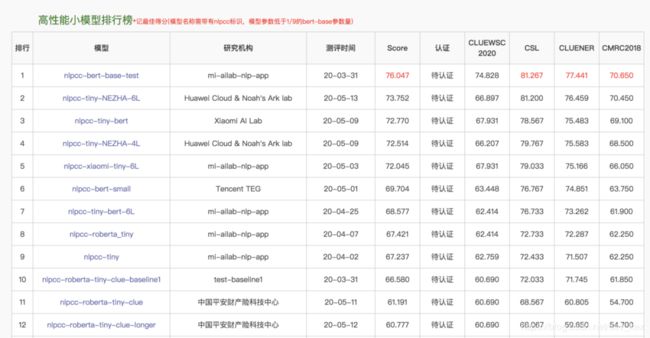
NLPCC高性能小模型测评:
NLPCC是中国计算机学会(CCF)的中文信息技术专委的年度学术会议,是专注于自然语言处理(NLP)和中文计算(CC)领域的国际前沿会议。
针对目前面向中文的轻量级模型资源缺乏问题,CLUE在NLPCC2020会议上举办了面向中文的小模型大赛(shared task 1)。本次竞赛吸引了包括华为、小米、腾讯等公司的关注,目前排行榜的前两名分别是华为诺亚方舟和小米LAB,获奖者将获得NLPCC和CCF中国信息技术技术委员会认证的证书。
同时,通过相关经验的直播分享,将促进模型小型化的应用和落地。华为、微软、小米的研究员或算法工程师针对预训练模型、模型小型化和高性能小模型测评的比赛分享了自己的心得和体会。
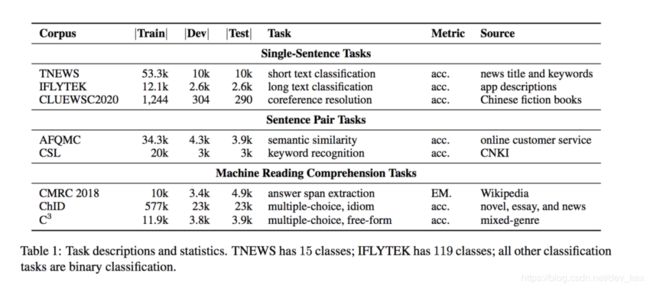
四、Arxiv论文介绍
《CLUE:A Chinese Language Understanding Evaluation Benchmark》
这是CLUE的主论文,系统地介绍了CLUE benchmark中文语言理解基准测评,包括对8大任务的构造和介绍、一系列的基线模型上的测评、人类测评和模型测评的分析,以及语言学专家构造的用于评估模型在中文现象上的诊断集上的效果。

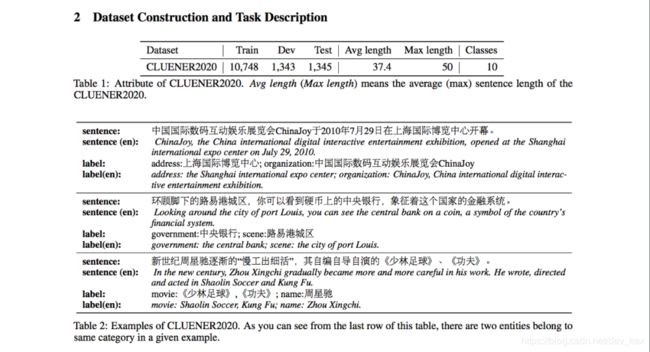
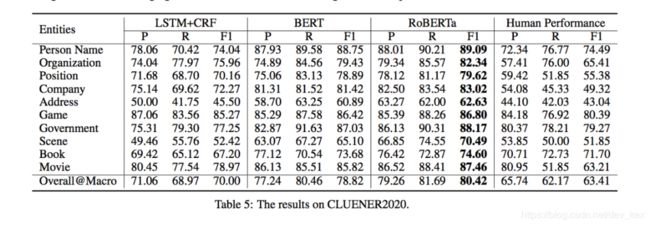
《CLUENER2020: Finegrained Named Entity Recognition Dataset and Benchmark for Chinese》
CLUENER2020发布了一个细粒度的命名实体识别的数据集,包含10个标签类别,并提供了三个基准模型和人类测评上的效果。
《CLUECorpus2020: A Large-scale Chinese Corpus for Pre-training Language Model》
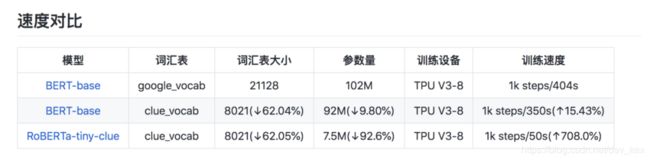
发布了CLUECorpus2020,一个目前为止专门针对预训练模型用途的高达100G中文语料库,一个专门优化后的中文词汇表。还包括在这基础上的高质量中文预训练模型集合,包括最先进大模型、最快小模型、相似度专门模型。累积发放给超过100家机构和个人使用,包括中科院国家重点实验室、北大教授博导、创新工场研究院、小米人工智能实验室等专业的科研机构和个人。

五、团队介绍
顾问
张俊林,顾问。中国中文信息学会理事,中科院软件所博士,新浪微博机器学习团队AI Lab负责人。《这就是搜索引擎:核心技术详解》(该书荣获全国第十二届优秀图书奖),《大数据日知录:架构与算法》的作者。
徐国强,顾问。MIT博士,平安集团上海Gammalab负责人。
陈哲乾,顾问。浙江大学计算机学院博士,一知智能联合创始人,2017年代表一知智能参加斯坦福大学的举办SQuAD机器阅读理解比赛,获得单模型组世界第二、多模型组世界第三的优异成绩。主导设计一知智能大脑项目。
创始会员
徐亮,会长。CLUE项目发起人及总负责人。「实在智能」NLP算法负责人。昵称brightmart,深耕NLP近10年,在深度学习、意图识别、问答系统有深入研究创新,Github Top 10最受欢迎的文本分类项目作者。多个预训练模型中文版、文本分类和数据集开源项目作者。
Danny Lan,副会长。首席学术指导。SOTA语言理解模型ALBERT第一作者,美国卡耐基梅隆大学博士, 前Google AI科学家、美国智能监控公司首席科学家。研究领域主要集中在自然语言处理,计算机视觉和深度学习的结合与应用。近年来在多个国际会议和期刊发表论文20余篇,在ACM Multimedia, CVPR, ECCV, ICCV 等国际顶会的程序委员会委员以及TPAMI, TIP, TMM, TCSVT, CVIU 等期刊担任审稿人。
张轩玮,CLUE Github项目负责人、北京负责人。硕士毕业于北京大学,目前在爱奇艺从事NLP相关工作,之前从事热点聚合,文本分类,标签生成,机器翻译方面的工作。
李露,CLUE分类任务与测评负责人。华中师范大学在读研究生,曾参与筹备中文自然语言推理的数据集。暑期在平安科技实习,主要负责利用自然语言处理模型进行序列标注和情感分类任务。
董倩倩,文本生成与NER负责人。中科院自动化所博士在读,2017年度AI Challenger 英中机器同声传译赛道冠军团队成员。主要研究语音翻译,曾参与多个中文NLP项目。
曹辰捷,阅读理解小组负责人。平安金融壹账通算法工程师,负责阅读理解和预训练相关业务,CMRC 2019阅读理解冠军团队成员。
喻聪,CLUE 测评系统负责人。杭州实在智能算法工程师。主要研究多轮对话、意图识别、实体抽取、知识问答相关任务。
刘伟棠,CLUE主项目完善& Pytorch负责人。浙江大华从事算法相关工作,主要负责警务、司法等文本建模、知识图谱构建工作。
胡海,CLUE 新数据集负责人。美国印第安纳大学语言学系、计算语言学方向博士生。主要研究方向是自然语言推理、自然语言理解数据集收集和标注,以及句法树库标注。
六、相关报道
1.机器之心,ChineseGLUE:为中文NLP模型定制的自然语言理解基准;
2.新智元,超100亿中文数据,要造出中国自己的BERT!首个专为中文NLP打造的语言理解基准CLUE升级 ;
3.Paper weekly,ChineseGLUE(CLUE):针对中文自然语言理解任务的基准平台;
4.AINLP,CLUECorpus2020:可能是史上最大的开源中文语料库以及高质量中文预训练模型集合;
5.机器之心,10大类\142条数据源,中文NLP数据集线上搜索开放。
附件·数据集介绍
1.AFQMC 蚂蚁金融语义相似度 Ant Financial Question Matching Corpus
数据量:训练集(34334)验证集(4316)测试集(3861)。例子:{“sentence1”: “双十一花呗提额在哪”, “sentence2”: “里可以提花呗额度”, “label”: “0”}每一条数据有三个属性,从前往后分别是 句子1,句子2,句子相似度标签。其中label标签,1 表示sentence1和sentence2的含义类似,0表示两个句子的含义不同。
2.TNEWS’ 今日头条中文新闻(短文本)分类Short Text Classificaiton for News
该数据集来自今日头条的新闻版块,共提取了15个类别的新闻,包括旅游,教育,金融,军事等。
数据量:训练集(53,360),验证集(10,000),测试集(10,000)。例子:{“label”: “102”, “label_des”: “news_entertainment”, “sentence”: “江疏影甜甜圈自拍,迷之角度竟这么好看,美吸引一切事物”}每一条数据有三个属性,从前往后分别是 分类ID,分类名称,新闻字符串(仅含标题)。
3.IFLYTEK’ 长文本分类Long Text classification
该数据集共有1.7万多条关于app应用描述的长文本标注数据,包含和日常生活相关的各类应用主题,共119个类别:”打车”:0,”地图导航”:1,”免费WIFI”:2,”租车”:3,….,”女性”:115,”经营”:116,”收款”:117,”其他”:118(分别用0-118表示)。
数据量:训练集(12,133),验证集(2,599),测试集(2,600)例子:{“label”: “110”, “label_des”: “社区超市”, “sentence”: “朴朴快送超市创立于2016年,专注于打造移动端30分钟即时配送一站式购物平台,商品品类包含水果、蔬菜、肉禽蛋奶、海鲜水产、粮油调味、酒水饮料、休闲食品、日用品、外卖等。朴朴公司希望能以全新的商业模式,更高效快捷的仓储配送模式,致力于成为更快、更好、更多、更省的在线零售平台,带给消费者更好的消费体验,同时推动中国食品安全进程,成为一家让社会尊敬的互联网公司。朴朴一下,又好又快,1.配送时间提示更加清晰友好2.保障用户隐私的一些优化3.其他提高使用体验的调整4.修复了一些已知bug”}
每一条数据有三个属性,从前往后分别是类别ID,类别名称,文本内容。
4.CLUEWSC2020: WSC Winograd模式挑战中文版,新版2020-03-25发布
Winograd Scheme Challenge(WSC)是一类代词消歧的任务。新版与原CLUE项目WSC内容不同,即判断句子中的代词指代的是哪个名词。题目以真假判别的方式出现,如:
句子:这时候放在床上枕头旁边的手机响了,我感到奇怪,因为欠费已被停机两个月,现在它突然响了。需要判断“它”指代的是“床”、“枕头”,还是“手机”?
数据来源:数据由CLUE benchmark提供,从中国现当代作家文学作品中抽取,再经语言专家人工挑选、标注。
数据形式:{“target”: {“span2_index”: 37, “span1_index”: 5, “span1_text”: “床”, “span2_text”: “它”},”idx”: 261,”label”: “false”,”text”: “这时候放在床上枕头旁边的手机响了,我感到奇怪,因为欠费已被停机两个月,现在它突然响了。”}”true”表示代词确实是指代span1_text中的名词的,”false”代表不是。数据集大小:训练集:1244;开发集:304
5.CSL 论文关键词识别Keyword Recognition
中文科技文献数据集(CSL)取自中文论文摘要及其关键词,论文选自部分中文社会科学和自然科学核心期刊。使用tf-idf生成伪造关键词与论文真实关键词混合,构造摘要-关键词对,任务目标是根据摘要判断关键词是否全部为真实关键词。
数据量:训练集(20,000),验证集(3,000),测试集(3,000)例子:{“id”: 1, “abst”: “为解决传统均匀FFT波束形成算法引起的3维声呐成像分辨率降低的问题,该文提出分区域FFT波束形成算法.远场条件下,以保证成像分辨率为约束条件,以划分数量最少为目标,采用遗传算法作为优化手段将成像区域划分为多个区域.在每个区域内选取一个波束方向,获得每一个接收阵元收到该方向回波时的解调输出,以此为原始数据在该区域内进行传统均匀FFT波束形成.对FFT计算过程进行优化,降低新算法的计算量,使其满足3维成像声呐实时性的要求.仿真与实验结果表明,采用分区域FFT波束形成算法的成像分辨率较传统均匀FFT波束形成算法有显著提高,且满足实时性要求.”, “keyword”: [“水声学”, “FFT”, “波束形成”, “3维成像声呐”], “label”: “1”}
每一条数据有四个属性,从前往后分别是 数据ID,论文摘要,关键词,真假标签。
6.CLUENER2020 细粒度命名实体识别
数据分为10个标签类别,分别为: 地址(address),书名(book),公司(company),游戏(game),政府(government),电影(movie),姓名(name),组织机构(organization),职位(position),景点(scene)
以train.json为例,数据分为两列:text & label,其中text列代表文本,label列代表文本中出现的所有包含在10个类别中的实体。例如:
text: “北京勘察设计协会副会长兼秘书长周荫如”label: {“organization”: {“北京勘察设计协会”: [[0, 7]]}, “name”: {“周荫如”: [[15, 17]]}, “position”: {“副会长”: [[8, 10]], “秘书长”: [[12, 14]]}}
其中,organization,name,position代表实体类别,”organization”: {“北京勘察设计协会”: [[0, 7]]}:表示原text中,”北京勘察设计协会” 是类别为”组织机构(organization)” 的实体, 并且start_index为0,end_index为7 (注:下标从0开始计数)
7.CMRC2018 简体中文阅读理解任务Reading Comprehension for Simplified Chinese
https://hfl-rc.github.io/cmrc2018/
数据量:训练集(短文数2,403,问题数10,142),试验集(短文数256,问题数1,002),开发集(短文数848,问题数3,219)
8.ChID 成语阅读理解填空Chinese IDiom Dataset for Cloze Test
https://arxiv.org/abs/1906.01265/成语完形填空,文中多处成语被mask,候选项中包含了近义的成语。
数据量:训练集(84,709),验证集(3,218),测试集(3,231)
9.C3 中文多选阅读理解Multiple-Choice Chinese
CMachine Reading Comprehensionhttps://arxiv.org/abs/1904.09679中文多选阅读理解数据集,包含对话和长文等混合类型数据集。训练和验证集中的d,m分别代表对话、多种文本类型混合。
数据量:训练集(11,869),验证集(3,816),测试集(3,892)。以上三个阅读理解数据集,请到GitHub项目查看详细例子。
七、写在最后:中文数据集有奖公开征集
现在,我们诚挚邀请中文自然语言理解方面的专家学者、老师同学、参与者为我们提供更多的中文自然语言理解数据集。这些数据集可以是您自己制作推出的,也可以是您认为很有意义但是是他人制作的数据集。
我们计划在6月14日前完成第二轮筛选,推出正式的CLUE Benchmark。请您将推荐数据集的名称、作者、形式以及License情况发送至:邮箱[email protected]
【奖励】
如果您推荐的数据集被选中,将能提高扩展数据集的知名度,并为学界、业界对自然语言理解的研究做出贡献。CLUE组织会引用和推广该数据集;我们也会结合数据集质量、意义、量级和标注难度、任务类型设置不同等级的奖励,给予1000—5000元现金奖励。
【要求】您推荐的数据集需要满足以下条件:
【任务与自然语言理解相关】我们要求数据集能够测试模型是否理解了中文,模型或者以研究为导向,或者以实际应用为导向,重点是需要包含语言理解成分。同时,确保任务质量。
【任务形式】任务输入是一段文本(可长可短),具体可以是分类、序列标注、指代消歧、多项选择、回归任务等。任务最好能够使用基本的神经网络模型做出基线,方便测评。
【能够测评】提交的任务需要有简单、客观的评测标准。如果是包含文本生成的项目,那么需要证明该项目有易行的可靠评测标准。
【公开的训练数据】任务的训练数据和开发数据需要公开,并且授权CLUE使用。【未公开的测试集】任务最好有尚未公开的测试集。
【任务难度】提交的任务不能过于简单。具体来讲,目前已有模型如BERT,相较训练过的普通标注者,结果还是会逊色很多。