深度学习之 DCGAN 及TensorFlow 实现
本文介绍DCGAN(Deep Convolution Generative Adversarial Nets)- 卷积生成对抗网络
相关论文 https://arxiv.org/pdf/1411.1784.pdf
1、生成性对抗网络
GAN(Generative Adversarial Nets)由两个“对抗”模型组成:一个捕获数据分布的生成模型G和一个判别模型D,
它估计样本来自训练数据的概率而不是生成样本的概率. G和D都可以是非线性的映射函数,例如多层感知器。
为了在数据数据x上学习生成器分布p_z(z) ,生成器建立从先前噪声分布p_z(z)到数据空间的映射函数,如G(z;θg)。
鉴别器D(x;θd)输入是真实图像或者生成图像,输出单个标量,该标量表示x来自训练数据而不是p_g的概率。
G和D都同时训练:固定判别模型 D,调整 G 的参数使得 log(1−D(G(z))的期望最小化;固定生成模型 G,调整 D 的参数
使得 logD(X)+log(1−D(G(z)))log 的期望最大化,这个优化过程归结为二元极小极大博弈(minimax two-player game)”问题:
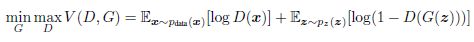
2、卷积生成对抗网络
DCGAN( Deep Convolution Generative Adversarial Nets),卷积生成对抗网络。卷积生成对抗网络指的是在生成对抗
网络中采用卷积结构,提升了生成网络效果,尤其图像生成和无监督学习得到非常良好的效果。
先看下一个DCGAN中用到的反卷积(后卷积,转置卷积)概念,再看原文提出的网络架构
2.1 逆卷积
1、卷积计算

原图尺寸为n1,卷积尺寸为n2,步骤为1,那么输出尺寸为n1 – n2 + 1
几种卷积(按填充方式,假设步骤为1)
full: 图片大小为n1,卷积核大小为n2,卷积后图像大小:n1 + n2-1。
same: 滑动步长为1,图片大小为n1,卷积核大小为n2,卷积后图像大小:n1,保证输出一样,所以填充大小和kerne大小有关
valid: 图片大小为n1,卷积核大小为n2,卷积后图像大小:n1 – n2 +1 如上图。 如果滑动步长为S,(n1 – n2)/s +1
2、逆卷积计算
先如下图,卷积计算
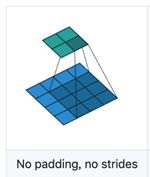
n1 = 4 n2 = 3(kernel size) stride =1 padding=0(valid)
尺寸计算公式,推导略
N(out) = (N(in) − k + 2p )/s+1
= (4 – 2 + 2*0)/1 + 1
= 2
其对应的反卷积,逆卷积

N(out) = (N(in)-1)× s + k -2*p
= (2 – 1)1 + 3 – 20
= 4
推导公式略
再看一个stride为2

n1 = 5 n2 = 3(kernel size) stride =2 padding=1(可以看出same, 为什么呢,same的目的是stride =1时输入输出一样,
图中n1 = 5 n2 = 3 padding=1,加入stride =1,输出和输入一样的)
N(out) = (N(in) − k + 2p )/s+1
= (5 – 3 + 2*1)/2 + 1
= 3
其逆卷积
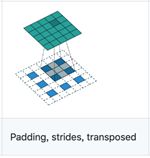
N(out) = (N(in)-1)× s + k -2p
= (3 -1)* 2 + 3 - 2 * 1
= 5
2.2 DCGAN网络结构
下面直接看原文中的网络结构:
生成网络:

判别网络

4、TensorFlow 实现
4.1 代码解读
完整代码 https://github.com/clark82/deeplearning/tree/master/DCGAN
代码结构和前面的CGAN一样,训练过程、损失函数都一样。
简单说明下生成网络部分代码,判别网络也一样,和上面网络结构图基本一致。
def generator(digit, noise_img, out_dim, reuse=False, is_train=True):
with tf.variable_scope("generator", reuse=reuse):
batch_label = tf.reshape(digit, [-1, 1, 1, label_size])
#noise_img = tf.concat([noise_img, digit], 1)
# 第一轮卷积 100 x 1 to 4 x 4 x 1024
# 全连接层
layer1 = tf.layers.dense(noise_img, 4*4*1024)
layer1 = tf.reshape(layer1, [-1, 4, 4, 1024])
# batch normalization
layer1 = tf.layers.batch_normalization(layer1, training=is_train)
# Leaky ReLU
layer1 = tf.maximum(alpha * layer1, layer1)
# dropout
layer1 = tf.nn.dropout(layer1, keep_prob=0.8)
#layer1 = conv_cond_concat(layer1, batch_label)
# 第二轮卷积, 为了适应我们输出的图片28*28, 这里输出尺寸为7×7, 计算公司如下,其他以此类推
# 4 x 4 x 1024 to 7 x 7 x 512
# N(out) = (N(in)-1)× s + k -2*p
# 7 =( 4 -1)× 1 + K - 2*0 => K = 4 因为valid -> p = 0
layer2 = tf.layers.conv2d_transpose(layer1, 512, 4, strides=1, padding='valid')
layer2 = tf.layers.batch_normalization(layer2, training=is_train)
layer2 = tf.maximum(alpha * layer2, layer2)
layer2 = tf.nn.dropout(layer2, keep_prob=0.8)
#layer2 = conv_cond_concat(layer2, batch_label)
#第三轮卷积 7 x 7 512 to 14 x 14 x 128
layer3 = tf.layers.conv2d_transpose(layer2, 256, 3, strides=2, padding='same')
layer3 = tf.layers.batch_normalization(layer3, training=is_train)
layer3 = tf.maximum(alpha * layer3, layer3)
layer3 = tf.nn.dropout(layer3, keep_prob=0.8)
#layer3 = conv_cond_concat(layer3, batch_label)
# 第四轮也是最后一轮比原文简化了一轮,logits & outputs
# 14 x 14 x 128 to 28 x 28 x 1
logits = tf.layers.conv2d_transpose(layer3, out_dim, 3, strides=2, padding='same')
outputs = tf.tanh(logits)
return outputs
4.1 运行
1、训练
python3 train.py -f 0
输出
Epoch 11/20… Discriminator Loss: 0.8269… Generator Loss: 1.0011…
Epoch 11/20… Discriminator Loss: 1.0718… Generator Loss: 1.5898…
Epoch 11/20… Discriminator Loss: 0.8474… Generator Loss: 0.8541…
Epoch 11/20… Discriminator Loss: 0.8976… Generator Loss: 0.8404…
Epoch 11/20… Discriminator Loss: 1.0316… Generator Loss: 1.7905…
Epoch 11/20… Discriminator Loss: 1.0467… Generator Loss: 0.7780…
Epoch 11/20… Discriminator Loss: 1.0639… Generator Loss: 1.2468…
Epoch 11/20… Discriminator Loss: 1.1244… Generator Loss: 1.2350…
Epoch 11/20… Discriminator Loss: 0.9353… Generator Loss: 0.5008…
Epoch 11/20… Discriminator Loss: 1.1602… Generator Loss: 1.8496…
Epoch 11/20… Discriminator Loss: 1.0921… Generator Loss: 0.9809…
Epoch 11/20… Discriminator Loss: 1.1783… Generator Loss: 0.7958…
Epoch 11/20… Discriminator Loss: 1.0097… Generator Loss: 1.0218…
Epoch 11/20… Discriminator Loss: 0.9718… Generator Loss: 1.3612…
Epoch 11/20… Discriminator Loss: 1.4930… Generator Loss: 0.5614…
Epoch 11/20… Discriminator Loss: 1.2413… Generator Loss: 1.3991…
Epoch 11/20… Discriminator Loss: 1.0385… Generator Loss: 1.1939…
Epoch 11/20… Discriminator Loss: 1.2979… Generator Loss: 0.3767…
2、观察生成过程
python3 train.py -f 2

3、生成测试
python3 train.py -f 1
