不用写代码的爬虫Web Scraper
Web Scraper 是谷歌 Chrome 浏览器插件,可自动化提取网页数据,实现不敲代码,指哪爬哪的目标,属于居家出行杀人越货之必备神器。
本节课我们先举个抓取示例,让大家熟悉下大致操作流程。各步骤详细操作流程(附动画及解说)将在后续课程推出。
官网插件下载:https://chrome.google.com/webstore/detail/web-scraper/jnhgnonknehpejjnehehllkliplmbmhn?hl=en
百度网盘下载: https://pan.baidu.com/s/133qCd3Bb9gaapqxcRk7aGw 提取码: kg61
一、抓取案例
以抓取知乎大V陈素封文章前 3 页标题、正文全文、点赞数为例。(https://www.zhihu.com/people/Feat/posts)
大家不妨打开此网页试着手动提取这些数据整理成电子表格,看看这项任务大概要花多长时间,如何无聊,这还只是 3 页,如果是 30 页,300 页呢?你大概要花 10 倍,100 倍精力,我这儿不过改个数字的事。

二、抓取流程
1)第一步:了解网址规则,建立 Sitemap。

2)第二步:熟悉网页结构,按下图顺序创建选择器。

1、元素选择器 ① post-element,用于选择文章元素块。
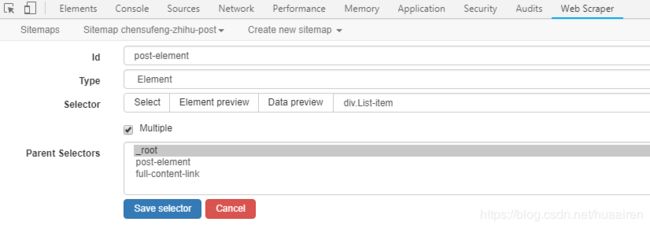
2、为元素选择器 ① post-element 建立 3 个子选择器,分别为文本选择器 ② post-title、链接选择器 ③ full-content-link、文本选择器 ④ link-count。

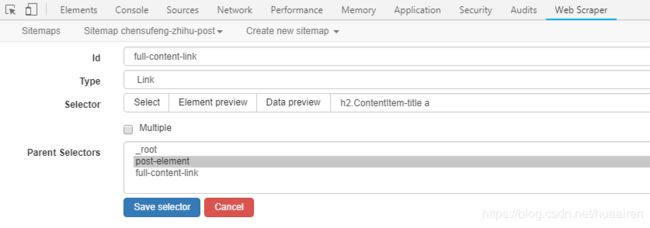

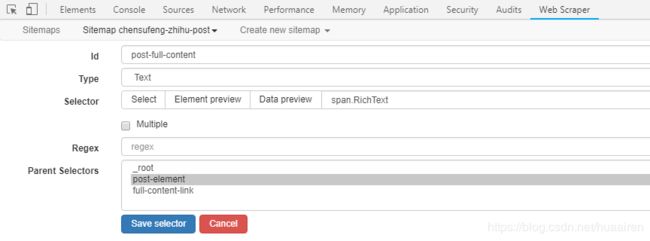
二、其他操作技巧
1.导出siteMap
{"_id":"chensufeng-zhihu-post","startUrl":["https://www.zhihu.com/people/Feat/posts?page=[1-3]"],"selectors":[{"id":"post-element","type":"SelectorElement","parentSelectors":["_root"],"selector":"div.List-item","multiple":true,"delay":0},{"id":"post-title","type":"SelectorText","parentSelectors":["post-element"],"selector":"h2.ContentItem-title a","multiple":false,"regex":"","delay":0},{"id":"full-content-link","type":"SelectorLink","parentSelectors":["post-element"],"selector":"h2.ContentItem-title a","multiple":false,"delay":0},{"id":"link-count","type":"SelectorText","parentSelectors":["post-element"],"selector":"span.Voters button.Button","multiple":false,"regex":"","delay":0},{"id":"post-full-content","type":"SelectorText","parentSelectors":["post-element"],"selector":"span.RichText ","multiple":false,"regex":"","delay":0},{"id":"test1","type":"SelectorText","parentSelectors":["post-element"],"selector":".Voters button","multiple":false,"regex":"","delay":0}]}使用插件的小窍门:
2.写好选择器可以直接预览数据。
小伙伴们,和我一起做一个愿意分享的技术达人!
推荐
公众号markdown排版so easy!
https://blog.csdn.net/huaairen/article/details/90249468
不用写代码的爬虫Web Scraper
https://blog.csdn.net/huaairen/article/details/90228668
把东西还给我
https://blog.csdn.net/huaairen/article/details/90084843
openbilibili源码 https://blog.csdn.net/huaairen/article/details/89481342
长江后浪推前浪,不学SpringBoot就会被拍到沙滩上