My Python Summary
Python的反射机制
简单的说通过dir(classname)可以获取类的方法及属性等,而通过globals()可以得到py文件中类Map,可以通过globals()[key]的方式创建对象,下所示
>>> class Element:
... def __init__(self,name):
... self.name=name
... def getname(self):
... return self.name
>>> dir(Element)
['__doc__', '__init__', '__module__', 'getname']
>>> globals()
{'__builtins__': , '__name__': '__main__', 'testmap': {'one': 'Element'}, '__doc__': None, 'Element': }
>>> globals()['Element']
>>> globals()['Element']('two').getname()
'two'
Python修改文件内容
不能直接进行修改,需要先将源文件通过readlines()读到一个数组中,如果文件过大只能使用临时文件,下面的小例子是在源文件中添加几个新行
if len(needModules) !=0:
origFile=open(self.luafilename)
origLines=origFile.readlines()
origFile.close()
modiFile=open(self.luafilename,'w')
appendLine=''
for moduleName in needModules.keys():
appendLine+="\nrequire ('"+moduleName+"')"
linN = 0
for line in origLines:
if linN == 2:
modiFile.writelines(appendLine)
else:
modiFile.writelines(line)
linN = linN + 1
modiFile.close()目录及文件的其他操作:在使用之前要import os 或 shutil -- High-level file operations
- 获得当前路径:以使用os.getcwd()函数获得当前的路径。注意,当前目录并不是指脚本所在的目录,而是所运行脚本的目录。
- 获得目录中文件列表: os.listdir(path)
- 创建目录:os.mkdir(path)
- 删除目录: os.rmdir(path)
- 判断是否是目录: os.path.isdir(path)
- 判断是否为文件: os.path.isfile(path)
- 创建文件: 1) os.mknod("test.txt") 创建空文件
- 2) open("test.txt",w) 直接打开一个文件,如果文件不存在则创建文件
- 复制文件:shutil.copyfile("oldfile","newfile") # oldfile和newfile都只能是文件
- shutil.copy("oldfile","newfile") # oldfile只能是文件夹,newfile可以是文件,也可以是目标目录
- 复制文件夹: shutil.copytree("olddir","newdir") #olddir和newdir都只能是目录,且newdir必须不存在
- 重命名文件(目录):os.rename("oldname","newname") #文件或目录都是使用这条命令
- 移动文件(目录): shutil.move("oldpos","newpos")
- 删除文件: os.remove("file")
- 删除目录: os.rmdir("dir") #只能删除空目录
- shutil.rmtree("dir") # 空目录、有内容的目录都可以删
- 转换目录: os.chdir("path") # 换路径
- 判断目标: os.path.exists("goal") # 判断目标是否存在
- os.path.isdir("goal") # 判断目标是否目录
- os.path.isfile("goal") # 判断目标是否文件
- 读写文件:(1)'r':只读(缺省。如果文件不存在,则抛出错误) (2)'w':只写(如果文件不存在,则自动创建文件)(3)'a':附加到文件末尾 (4) 'r+':读写 (5)如果需要以二进制方式打开文件,需要在mode后面加上字符"b",比如"rb""wb"等, (6)注意如果文件进行r+,须保证文件存在,可以先判断exists,然后如果不存在就mknod
file_handler = open(filename,,mode)
Table mode
| 模式 |
描述 |
| r |
以读方式打开文件,可读取文件信息。 |
| w |
以写方式打开文件,可向文件写入信息。如文件存在,则清空该文件,再写入新内容 |
| a |
以追加模式打开文件(即一打开文件,文件指针自动移到文件末尾),如果文件不存在则创建 |
| r+ |
以读写方式打开文件,可对文件进行读和写操作。 |
| w+ |
消除文件内容,然后以读写方式打开文件。 |
| a+ |
以读写方式打开文件,并把文件指针移到文件尾。 |
| b |
以二进制模式打开文件,而不是以文本模式。该模式只对Windows或Dos有效,类Unix的文件是用二进制模式进行操作的。 |
Table 文件对象方法
| 方法 |
描述 |
| f.close() |
关闭文件,记住用open()打开文件后一定要记得关闭它,否则会占用系统的可打开文件句柄数。 |
| f.fileno() |
获得文件描述符,是一个数字 |
| f.flush() |
刷新输出缓存 |
| f.isatty() |
如果文件是一个交互终端,则返回True,否则返回False。 |
| f.read([count]) |
读出文件,如果有count,则读出count个字节。 |
| f.readline() |
读出一行信息。 |
| f.readlines() |
读出所有行,也就是读出整个文件的信息。 |
| f.seek(offset[,where]) |
把文件指针移动到相对于where的offset位置。where为0表示文件开始处,这是默认值 ;1表示当前位置;2表示文件结尾。 |
| f.tell() |
获得文件指针位置。 |
| f.truncate([size]) |
截取文件,使文件的大小为size。 |
| f.write(string) |
把string字符串写入文件。 |
| f.writelines(list) |
把list中的字符串一行一行地写入文件,是连续写入文件,没有换行。 |
Python的Table操作
长度:len(), 是否存在某个Key: has_key(), 得到key: table['key'], 删除table元素: del table['abc']
如:table = {'abc':1, 'def':2, 'ghi':3}
table.keys(): ['abc', 'ghi', 'def']
table.values():[1, 3, 2]
table.items(): [('abc', 1), ('ghi', 3), ('def', 2)]
Python的字符串操作
- python的字符串属性函数
- python的string模块
- 字符串属性函数
字符串属性方法
- >>> str='string learn'
- >>> dir(str)
- ['__add__', '__class__', '__contains__', '__delattr__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__getslice__', '__gt__', '__hash__', '__init__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '_formatter_field_name_split', '_formatter_parser', 'capitalize', 'center', 'count', 'decode', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'index', 'isalnum', 'isalpha', 'isdigit', 'islower', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
字符串格式输出对齐
- >>> str='stRINg lEArn'
- >>>
- >>> str.center(20) #生成20个字符长度,str排中间
- ' stRINg lEArn '
- >>>
- >>> str.ljust(20) #str左对齐
- 'stRINg lEArn '
- >>>
- >>> str.rjust(20) #str右对齐
- ' stRINg lEArn'
- >>>
- >>> str.zfill(20) #str右对齐,左边填充0
- '00000000stRINg lEArn'
大小写转换
- >>> str='stRINg lEArn'
- >>>
- >>> str.upper() #转大写
- 'STRING LEARN'
- >>>
- >>> str.lower() #转小写
- 'string learn'
- >>>
- >>> str.capitalize() #字符串首为大写,其余小写
- 'String learn'
- >>>
- >>> str.swapcase() #大小写对换
- 'STrinG LeaRN'
- >>>
- >>> str.title() #以分隔符为标记,首字符为大写,其余为小写
- 'String Learn'
字符串条件判断
- >>> str='0123'
- >>> str.isalnum() #是否全是字母和数字,并至少有一个字符
- True
- >>> str.isdigit() #是否全是数字,并至少有一个字符
- True
-
- >>> str='abcd'
- >>> str.isalnum()
- True
- >>> str.isalpha() #是否全是字母,并至少有一个字符
- True
- >>> str.islower() #是否全是小写,当全是小写和数字一起时候,也判断为True
- True
-
- >>> str='abcd0123'
- >>> str.islower() #同上
- True
- >>> str.isalnum()
- True
-
- >>> str=' '
- >>> str.isspace() #是否全是空白字符,并至少有一个字符
- True
- >>> str='ABC'
- >>> str.isupper() #是否全是大写,当全是大写和数字一起时候,也判断为True
- True
- >>> str='Abb Acc'
- >>> str.istitle() #所有单词字首都是大写,标题
- True
-
- >>> str='string learn'
- >>> str.startswith('str') #判断字符串以'str'开头
- True
- >>> str.endswith('arn') #判读字符串以'arn'结尾
- True
字符串搜索定位与替换
- >>> str='string lEARn'
- >>>
- >>> str.find('a') #查找字符串,没有则返回-1,有则返回查到到第一个匹配的索引
- -1
- >>> str.find('n')
- 4
- >>> str.rfind('n') #同上,只是返回的索引是最后一次匹配的
- 11
- >>>
- >>> str.index('a') #如果没有匹配则报错
- Traceback (most recent call last):
- File "
" , line 1, in <module>
- ValueError: substring not found
- >>> str.index('n') #同find类似,返回第一次匹配的索引值
- 4
- >>> str.rindex('n') #返回最后一次匹配的索引值
- 11
- >>>
- >>> str.count('a') #字符串中匹配的次数
- 0
- >>> str.count('n') #同上
- 2
- >>>
- >>> str.replace('EAR','ear') #匹配替换
- 'string learn'
- >>> str.replace('n','N')
- 'striNg lEARN'
- >>> str.replace('n','N',1)
- 'striNg lEARn'
- >>>
- >>>
- >>> str.strip('n') #删除字符串首尾匹配的字符,通常用于默认删除回车符
- 'string lEAR'
- >>> str.lstrip('n') #左匹配
- 'string lEARn'
- >>> str.rstrip('n') #右匹配
- 'string lEAR'
- >>>
- >>> str='tab'
- >>> str.expandtabs() #把制表符转为空格
- ' tab'
- >>> str.expandtabs(2) #指定空格数
- ' tab'
字符串编码与解码
- >>> str='字符串学习'
- >>> str
- '\xe5\xad\x97\xe7\xac\xa6\xe4\xb8\xb2\xe5\xad\xa6\xe4\xb9\xa0'
- >>>
- >>> str.decode('utf-8') #解码过程,将utf-8解码为unicode
- u'\u5b57\u7b26\u4e32\u5b66\u4e60'
-
- >>> str.decode('utf-8').encode('gbk') #编码过程,将unicode编码为gbk
- '\xd7\xd6\xb7\xfb\xb4\xae\xd1\xa7\xcf\xb0'
- >>> str.decode('utf-8').encode('utf-8') #将unicode编码为utf-8
- '\xe5\xad\x97\xe7\xac\xa6\xe4\xb8\xb2\xe5\xad\xa6\xe4\xb9\xa0'
字符串分割变换
- >>> str='Learn string'
- >>> '-'.join(str)
- 'L-e-a-r-n- -s-t-r-i-n-g'
- >>> l1=['Learn','string']
- >>> '-'.join(l1)
- 'Learn-string'
- >>>
- >>> str.split('n')
- ['Lear', ' stri', 'g']
- >>> str.split('n',1)
- ['Lear', ' string']
- >>> str.rsplit('n',1)
- ['Learn stri', 'g']
- >>>
- >>> str.splitlines()
- ['Learn string']
- >>>
- >>> str.partition('n')
- ('Lear', 'n', ' string')
- >>> str.rpartition('n')
- ('Learn stri', 'n', 'g')
python 解析xml
(1)首先要理解 nodeName、nodeValue 以及 nodeType 包含有关于节点的信息:
http://www.w3school.com.cn/xmldom/dom_node.asp (权威解释),以下为摘出:
nodeName 属性含有某个节点的名称。
- 元素节点的 nodeName 是标签名称
- 属性节点的 nodeName 是属性名称
- 文本节点的 nodeName 永远是 #text
- 文档节点的 nodeName 永远是 #document
注释:nodeName 所包含的 XML 元素的标签名称永远是大写的
nodeValue
对于文本节点,nodeValue 属性包含文本。
对于属性节点,nodeValue 属性包含属性值。
nodeValue 属性对于文档节点和元素节点是不可用的。
nodeType
nodeType 属性可返回节点的类型。
最重要的节点类型是:
| 元素类型 | 节点类型 |
|---|---|
| 元素element | 1 ELEMENT_NODE |
| 属性attr | 2 |
| 文本text | 3 TEXT_NODE |
| 注释comments | 8 |
| 文档document | 9 |
(2)python 解析XML的lib, xml.dom.minidom
xml.dom 解析XML的API描述
minidom.parse(filename)
加载读取XML文件
doc.documentElement
获取XML文档对象
node.getAttribute(AttributeName)
获取XML节点属性值
node.getElementsByTagName(TagName)
获取XML节点对象集合
node.childNodes #返回子节点列表。
node.childNodes[index].nodeValue
获取XML节点值
node.firstChild
#访问第一个节点。等价于pagexml.childNodes[0]
doc = minidom.parse(filename)
doc.toxml('UTF-8')
返回Node节点的xml表示的文本
Node.attributes["id"]
a.name #就是上面的 "id"
a.value #属性的值
访问元素属性
(3)python解析mxl的简单小例子:
#引入lib库
from xml.dom import minidom
#导入xml文件
dom = minidom.parse(fileXml)
#遍历子节点
for node in dom.childNodes:
for model in node.childNodes:
#得到子节点,保证节点的类型
if model.nodeType in ( node.ELEMENT_NODE, node.CDATA_SECTION_NODE):
#获取属性
sCat= model.getAttribute('name')
C++中调用python脚本的方法
#include
#include
#include
#include
string TracingRecord::dataDecode() const
{
string expectCmd;
expectCmd = "/usr/bin/python " + DiameterDecodeScript + " 2>&1";
string result = executeCmd(expectCmd);
size_t pos = result.find("Frame");
if( pos != std::string::npos)
{
return result;
}
}
string TracingRecord::executeCmd(string& cmd)
{
FILE* pipe = popen(cmd.c_str(), "r");
if(!pipe)
return "";
char buffer[128];
string result;
while(!feof(pipe)){
if(fgets(buffer,128,pipe)!= NULL)
result += buffer;
}
pclose(pipe);
return result;
} http://www.cnblogs.com/itech/archive/2011/01/06/1924972.html A good article for the python and XML
There are three basic sequence types: lists, tuples, and range objects.
http://www.csdn.net/article/2013-03-25/2814634-data-de-duplication-tactics-with-hdfs cloudy
运行Python脚本使用时
(1) 可以使用python命令调用此脚本如:python dbtrip.py -h
(2) 也可以先赋予脚本的可执行权限:chmod u+x dbtrip.py 然后再运行./dbtrip.py -h即可
支持这两种方式的要点是添加 #!/usr/bin/env python 到python脚本的第一行中即可
minidom 支持xml +dom的简单应用
getopt 支持python脚本的参数获取
Curly braces or the set() function can be used to create sets. Note: to create an empty set you have to useset(), not{}; the latter creates an empty dictionary, a data structure that we discuss in the next section.
Similarly to list comprehensions, set comprehensions are also supported:
>>> a = {x for x in 'abracadabra' if x not in 'abc'}
>>> a
{'r', 'd'}
Looping Techniques¶
When looping through dictionaries, the key and corresponding value can be retrieved at the same time using theitems() method.
>>> knights = {'gallahad': 'the pure', 'robin': 'the brave'}
>>> for k, v in knights.items():
... print(k, v)
...
gallahad the pure
robin the brave
When looping through a sequence, the position index and corresponding value can be retrieved at the same time using theenumerate() function.
>>> for i, v in enumerate(['tic', 'tac', 'toe']):
... print(i, v)
...
0 tic
1 tac
2 toe
To loop over two or more sequences at the same time, the entries can be paired with thezip() function.
>>> questions = ['name', 'quest', 'favorite color']
>>> answers = ['lancelot', 'the holy grail', 'blue']
>>> for q, a in zip(questions, answers):
... print('What is your {0}? It is {1}.'.format(q, a))
...
What is your name? It is lancelot.
What is your quest? It is the holy grail.
What is your favorite color? It is blue.
To loop over a sequence in reverse, first specify the sequence in a forward direction and then call thereversed() function.
>>> for i in reversed(range(1, 10, 2)):
... print(i)
...
9
7
5
3
1
To loop over a sequence in sorted order, use the sorted() function which returns a new sorted list while leaving the source unaltered.
>>> basket = ['apple', 'orange', 'apple', 'pear', 'orange', 'banana']
>>> for f in sorted(set(basket)):
... print(f)
...
apple
banana
orange
pear
To change a sequence you are iterating over while inside the loop (for example to duplicate certain items), it is recommended that you first make a copy. Looping over a sequence does not implicitly make a copy. The slice notation makes this especially convenient:
>>> words = ['cat', 'window', 'defenestrate']
>>> for w in words[:]: # Loop over a slice copy of the entire list.
... if len(w) > 6:
... words.insert(0, w)
...
>>> words
['defenestrate', 'cat', 'window', 'defenestrate']
More on Conditions
The conditions used in while and if statements can contain any operators, not just comparisons.
The comparison operators in and not in check whether a value occurs (does not occur) in a sequence. The operators is and is not compare whether two objects are really the same object; this only matters for mutable objects like lists. All comparison operators have the same priority, which is lower than that of all numerical operators.
Comparisons can be chained. For example, a < b == c tests whether a is less than b and moreover b equals c.
Comparisons may be combined using the Boolean operators and and or, and the outcome of a comparison (or of any other Boolean expression) may be negated with not. These have lower priorities than comparison operators; between them, not has the highest priority and or the lowest, so that A and not B or C is equivalent to (A and (not B)) or C. As always, parentheses can be used to express the desired composition.
The Boolean operators and and or are so-called short-circuit operators: their arguments are evaluated from left to right, and evaluation stops as soon as the outcome is determined. For example, if A and C are true but B is false, A and B and C does not evaluate the expression C. When used as a general value and not as a Boolean, the return value of a short-circuit operator is the last evaluated argument.
It is possible to assign the result of a comparison or other Boolean expression to a variable. For example,
>>> string1, string2, string3 = '', 'Trondheim', 'Hammer Dance'
>>> non_null = string1 or string2 or string3
>>> non_null
'Trondheim'
Note that in Python, unlike C, assignment cannot occur inside expressions. C programmers may grumble about this, but it avoids a common class of problems encountered in C programs: typing = in an expression when == was intended.
Comparing Sequences and Other Types
Sequence objects may be compared to other objects with the same sequence type. The comparison uses lexicographical ordering: first the first two items are compared, and if they differ this determines the outcome of the comparison; if they are equal, the next two items are compared, and so on, until either sequence is exhausted. If two items to be compared are themselves sequences of the same type, the lexicographical comparison is carried out recursively. If all items of two sequences compare equal, the sequences are considered equal. If one sequence is an initial sub-sequence of the other, the shorter sequence is the smaller (lesser) one. Lexicographical ordering for strings uses the Unicode codepoint number to order individual characters. Some examples of comparisons between sequences of the same type:
(1, 2, 3) < (1, 2, 4)
[1, 2, 3] < [1, 2, 4]
'ABC' < 'C' < 'Pascal' < 'Python'
(1, 2, 3, 4) < (1, 2, 4)
(1, 2) < (1, 2, -1)
(1, 2, 3) == (1.0, 2.0, 3.0)
(1, 2, ('aa', 'ab')) < (1, 2, ('abc', 'a'), 4)
Note that comparing objects of different types with < or > is legal provided that the objects have appropriate comparison methods. For example, mixed numeric types are compared according to their numeric value, so 0 equals 0.0, etc. Otherwise, rather than providing an arbitrary ordering, the interpreter will raise a TypeError exception.
凡事不要有push的感觉,如果决定做,就要投入的好好做,不要拖延
(1)os.system
# 仅仅在一个子终端运行系统命令,而不能获取命令执行后的返回信息
# 如果再命令行下执行,结果直接打印出来
例如:
1 |
>>> import os |
2 |
>>> os.system('ls') |
3 |
chk_err_log.py CmdTool.log install_log.txt install_zabbix.sh manage_deploy.sh MegaSAS.log |
(2)os.popen
#该方法不但执行命令还返回执行后的信息对象
#好处在于:将返回的结果赋于一变量,便于程序的处理。
例如:
1 |
>>> import os |
2 |
>>>tmp = os.popen('ls *.sh').readlines() |
3 |
>>>tmp |
4 |
['install_zabbix.sh\n', 'manage_deploy.sh\n', 'mysql_setup.sh\n', 'python_manage_deploy.sh\n', 'setup.sh\n'] |
(3)使用模块subprocess
使用方法:
>>> import subprocess
>>> subprocess.call (["cmd", "arg1", "arg2"],shell=True)
好处在于:运用对线程的控制和监控,将返回的结果赋于一变量,便于程序的处理。
如获取返回和输出:
1 |
import subprocess |
2 |
p = subprocess.Popen('ls *.sh', shell=True, stdout=subprocess.PIPE, stderr=subprocess.STDOUT) |
3 |
print p.stdout.readlines() |
4 |
for line in p.stdout.readlines(): |
5 |
print line, |
6 |
retval = p.wait() |
(4) 使用模块commands模块
常用的主要有两个方法:getoutput和getstatusoutput
1 |
>>> import commands |
2 |
|
3 |
>>> commands.getoutput('ls *.sh') |
4 |
'install_zabbix.sh\nmanage_deploy.sh\nmysql_setup.sh\npython_manage_deploy.sh\nsetup.sh' |
5 |
|
6 |
>>> commands.getstatusoutput('ls *.sh') |
7 |
(0, 'install_zabbix.sh\nmanage_deploy.sh\nmysql_setup.sh\npython_manage_deploy.sh\nsetup.sh') |
注意: 当执行命令的参数或者返回中包含了中文文字,那么建议使用subprocess,如果使用os.popen则会出现错误。
As your program gets longer, you may want to split it into several files for easier maintenance. You may also want to use a handy function that you’ve written in several programs without copying its definition into each program.To support this, Python has a way to put definitions in a file and use them in a script or in an interactive instance of the interpreter. Such a file is called amodule; A module is a file containing Python definitions and statements. The file name is the module name with the suffix .py appended. Within a module, the module’s name (as a string) is available as the value of the global variable __name__.
When a module named spam is imported, the interpreter first searches for a built-in module with that name. If not found, it then searches for a file namedspam.py in a list of directories given by the variable sys.path. sys.path is initialized from these locations:
- the directory containing the input script (or the current directory).
- PYTHONPATH (a list of directory names, with the same syntax as the shell variable PATH).
- the installation-dependent default.
You can modify it using standard list operations:
The built-in function dir() is used to find out which names a module defines. It returns a sorted list of strings:
Note that it lists all types of names: variables, modules, functions, etc. and it does not list the names of built-in functions and variables.Packages are a way of structuring Python’s module namespace by using “dotted module names”.The __init__.py files are required to make Python treat the directories as containing packages.
Python的脚本都是用扩展名为py的文本文件保存的,一个脚本可以单独运行,也可以导入另一个脚本中运行。当脚本被导入运行时,我们将其称为模块(module)。模块是Python组织代码的基本方式。
模块名与脚本的文件名相同,例如我们编写了一个名为MyTest.py的脚本,则可在另外一个脚本中用import MyTest语句来导入它。在导入时,Python解释器会先在脚本当前目录下查找,如果没有则在sys.path包含的路径中查找。
在导入模块时,Python会做以下三件事:
(1) 为模块文件中定义的对象创建一个名字空间,通过这个名字空间可以访问到模块中定义的函数及变量;
(2) 在新创建的名字空间里执行模块文件;
(3) 创建一个名为模块文件的对象,该对象引用模块的名字空间,这样就可以通过这个对象访问模块中的函数及变量,
Python的模块可以按目录组织为包(package)。一般来说,我们将多个关系密切的模块组织成一个包,以便于维护和使用,同时可有效避免名字空间冲突。创建一个包的步骤是:建立一个名字为包名字的文件夹,并在该文件夹下创建一个__init__.py文件,你可以根据需要在该文件夹下存放脚本文件、已编译扩展及子包。
只要目录下存在__init__.py,就表明此目录应被作为一个package处理。在最简单的例子中,__init__.py 是一个空文件,不过一般我们都要在__init__.py中做一些包的初始化动作,或是设定一些变量。
最常用的变量是__all__。当使用包的人在用from pack import * 语句导入的时候,系统会查找目录pack下的__init__.py文件中的__all__这个变量。__all__是一个list,包含了所有应该被导入的模块名称,例如:__all__ = ["m1", "m2", "m3"] 表示当from pack import * 时会import 这三个module。
如果没有定义__all__,from pack import * 不会保证所有的子模块被导入。所以要么通过__init.py__,要么显式地import 以保证子模块被导入,如:import pack.m1, pack.m2, pack.m3。
包的导入方式有from packge import item或import.subitem.subsubitem,其实就和导入模块是一样的了,不过多了package,当使用from package import *的时候,可是使用一个__all__变量来限定可以被其他模块import的子module,属性或变量,如果不设置,那么就是默认全部模块,如下面的小例子中,通过__all__变量来限定bar和baz可以被import.
alltag.py
__all__ = ['bar', 'baz']
waz = 5
bar = 10
def baz(): return 'baz'
Note that when using from package import item, the item can be either a submodule (or subpackage) of the package, or some other name defined in the package, like a function, class or variable. The import statement first tests whether the item is defined in the package; if not, it assumes it is a module and attempts to load it. If it fails to find it, an ImportError exception is raised.
Contrarily, when using syntax like import item.subitem.subsubitem, each item except for the last must be a package; the last item can be a module or a package but can’t be a class or function or variable defined in the previous item. if a package’s__init__.py code defines a list named __all__, it is taken to be the list of module names that should be imported when from package import * is encountered.
The str() function is meant to return representations of values which are fairly human-readable, while repr() is meant to generate representations which can be read by the interpreter (or will force a SyntaxError if there is no equivalent syntax).ten you’ll want more control over the formatting of your output than simply printing space-separated values. The way is to use thestr.format() method. str.rjust() method of string objects, which right-justifies a string in a field of a given width by padding it with spaces on the left. There are similar methods str.ljust() and str.center(). str.zfill(), which pads a numeric string on the left with zeros. It understands about plus and minus signs:
An optional ':' and format specifier can follow the field name. Passing an integer after the ':' will cause that field to be a minimum number of characters wide. The % operator can also be used for string formatting. It interprets the left argument much like a sprintf()-style format string to be applied to the right argument, and returns the string resulting from this formatting operation.
If the end of the file has been reached, f.read() will return an empty string ('').
For reading lines from a file, you can loop over the file object. This is memory efficient, fast, and leads to simple code:
pickle. This is an amazing module that can take almost any Python object (even some forms of Python code!), and convert it to a string representation; this process is called pickling. Reconstructing the object from the string representation is called unpickling. Between pickling and unpickling, the string representing the object may have been stored in a file or data, or sent over a network connection to some distant machine. Pickle the obj x to the file obj f opened for writing, using pickle.dump(x,f) and unpickle the obj x from the file obj f opened for reading, using x=pickle.load(f).pickle is the standard way to make Python objects which can be stored and reused by other programs or by a future invocation of the same program; the technical term for this is a persistent object. Because pickle is so widely used, many authors who write Python extensions take care to ensure that new data types such as matrices can be properly pickled and unpickled.
After the statement is executed, the file f is always closed, even if a problem was encountered while processing the lines. Objects which, like files, provide predefined clean-up actions will indicate this in their documentation.
When an error message is printed for an unhandled exception, the exception’s class name is printed, then a colon and a space, and finally the instance converted to a string using the built-in functionstr().
The use of iterators pervades(遍及,弥漫) and unifies Python. Behind the scenes, the for statement calls iter() on the container object. The function returns an iterator object that defines the method __next__() which accesses elements in the container one at a time. When there are no more elements, __next__() raises a StopIteration exception which tells the for loop to terminate.You can call the __next__() method using the next() built-in function.Having seen the mechanics behind the iterator protocol, it is easy to add iterator behavior to your classes. Define an__iter__() method which returns an object with a__next__() method. If the class defines__next__(), then__iter__() can just returnself:
class Reverse:
"""Iterator for looping over a sequence backwards."""
def __init__(self, data):
self.data = data
self.index = len(data)
def __iter__(self):
return self
def __next__(self):
if self.index == 0:
raise StopIteration
self.index = self.index - 1
return self.data[self.index]
>>> sum(i*i for i in range(10)) # sum of squares
285
>>> xvec = [10, 20, 30]
>>> yvec = [7, 5, 3]
>>> sum(x*y for x,y in zip(xvec, yvec)) # dot product
260
>>> from math import pi, sin
>>> sine_table = {x: sin(x*pi/180) for x in range(0, 91)}
>>> unique_words = set(word for line in page for word in line.split())
>>> valedictorian = max((student.gpa, student.name) for student in graduates)
>>> data = 'golf'
>>> list(data[i] for i in range(len(data)-1, -1, -1))
['f', 'l', 'o', 'g']
- zip ( *iterables ) ¶
-
Make an iterator that aggregates elements from each of the iterables.
Returns an iterator of tuples, where the i-th tuple contains the i-th element from each of the argument sequences or iterables. The iterator stops when the shortest input iterable is exhausted. With a single iterable argument, it returns an iterator of 1-tuples. With no arguments, it returns an empty iterator. Equivalent to:
def zip(*iterables): # zip('ABCD', 'xy') --> Ax By sentinel = object() iterators = [iter(it) for it in iterables] while iterators: result = [] for it in iterators: elem = next(it, sentinel) if elem is sentinel: return result.append(elem) yield tuple(result)
The left-to-right evaluation order of the iterables is guaranteed. This makes possible an idiom for clustering a data series into n-length groups usingzip(*[iter(s)]*n).
zip() should only be used with unequal length inputs when you don’t care about trailing, unmatched values from the longer iterables. If those values are important, useitertools.zip_longest() instead.
zip() in conjunction with the * operator can be used to unzip a list:
>>> x = [1, 2, 3] >>> y = [4, 5, 6] >>> zipped = zip(x, y) >>> list(zipped) [(1, 4), (2, 5), (3, 6)] >>> x2, y2 = zip(*zip(x, y)) >>> x == list(x2) and y == list(y2) True
The os module provides dozens of functions for interacting with the operating system.
Be sure to use the importos style instead offromosimport*. This will keepos.open() from shadowing the built-inopen() function which operates much differently.
Open file and return a corresponding file object. If the file cannot be opened, anOSError is raised.
Open the file file and set various flags according to flags and possibly its mode according tomode. When computingmode, the current umask value is first masked out. Return the file descriptor for the newly opened file. flag constants (likeO_RDONLY andO_WRONLY) are defined in this module too (seeopen() flag constants).
The built-in dir() andhelp() functions are useful as interactive aids for working with large modules likeos:
>>> import os
>>> dir(os)
The re module provides regular expression tools for advanced string processing. For complex matching and manipulation, regular expressions offer succinct, optimized solutions:
>>> import re
>>> re.findall(r'\bf[a-z]*', 'which foot or hand fell fastest')
['foot', 'fell', 'fastest']
>>> re.sub(r'(\b[a-z]+) \1', r'\1', 'cat in the the hat')
'cat in the hat'
When only simple capabilities are needed, string methods are preferred because they are easier to read and debug:
>>> 'tea for too'.replace('too', 'two')
'tea for two'
The math module gives access to the underlying C library functions for floating point math.Therandom module provides tools for making random selections.There are a number of modules for accessing the internet and processing internet protocols. Two of the simplest areurllib.request for retrieving data from URLs andsmtplib for sending mail.
>>> from urllib.request import urlopen
>>> for line in urlopen('http://tycho.usno.navy.mil/cgi-bin/timer.pl'):
... line = line.decode('utf-8') # Decoding the binary data to text.
... if 'EST' in line or 'EDT' in line: # look for Eastern Time
... print(line)
Nov. 25, 09:43:32 PM EST
Some Python users develop a deep interest in knowing the relative performance of different approaches to the same problem. Python provides a measurement tool that answers those questions immediately.
For example, it may be tempting to use the tuple packing and unpacking feature instead of the traditional approach to swapping arguments. Thetimeit module quickly demonstrates a modest performance advantage:
>>> from timeit import Timer
>>> Timer('t=a; a=b; b=t', 'a=1; b=2').timeit()
0.57535828626024577
>>> Timer('a,b = b,a', 'a=1; b=2').timeit()
0.54962537085770791
In contrast to timeit‘s fine level of granularity, theprofile andpstats modules provide tools for identifying time critical sections in larger blocks of code.
One approach for developing high quality software is to write tests for each function as it is developed and to run those tests frequently during the development process.
The doctest module provides a tool for scanning a module and validating tests embedded in a program’s docstrings. Test construction is as simple as cutting-and-pasting a typical call along with its results into the docstring. This improves the documentation by providing the user with an example and it allows the doctest module to make sure the code remains true to the documentation:
def average(values):
"""Computes the arithmetic mean of a list of numbers.
>>> print(average([20, 30, 70]))
40.0
"""
return sum(values) / len(values)
import doctest
doctest.testmod() # automatically validate the embedded tests
the following is the result of the execution of doctest.testmod()
**********************************************************************
File "__main__", line 4, in __main__.average
Failed example:
print(average([20,30,70]))
Expected:
40.0
Got:
40
**********************************************************************
1 items had failures:
1 of 1 in __main__.average
***Test Failed*** 1 failures.
(1, 1)
>>>
The unittest module is not as effortless as thedoctest module, but it allows a more comprehensive set of tests to be maintained in a separate file:
import unittest
class TestStatisticalFunctions(unittest.TestCase):
def test_average(self):
self.assertEqual(average([20, 30, 70]), 40.0)
self.assertEqual(round(average([1, 5, 7]), 1), 4.3)
self.assertRaises(ZeroDivisionError, average, [])
self.assertRaises(TypeError, average, 20, 30, 70)
unittest.main() # Calling from the command line invokes all tests
======================================================================
FAIL: test_average (__main__.TestStaticsFunctions)
----------------------------------------------------------------------
Traceback (most recent call last):
File "
AssertionError: 4.0 != 4.2999999999999998
----------------------------------------------------------------------
Ran 1 test in 0.000s
FAILED (failures=1)
Python has a “batteries included” philosophy. This is best seen through the sophisticated and robust capabilities of its larger packages. For example:
- The xmlrpc.client andxmlrpc.server modules make implementing remote procedure calls into an almost trivial task. Despite the modules names, no direct knowledge or handling of XML is needed.
- The email package is a library for managing email messages, including MIME and other RFC 2822-based message documents. Unlikesmtplib andpoplib which actually send and receive messages, the email package has a complete toolset for building or decoding complex message structures (including attachments) and for implementing internet encoding and header protocols.
- The xml.dom andxml.sax packages provide robust support for parsing this popular data interchange format. Likewise, thecsv module supports direct reads and writes in a common database format. Together, these modules and packages greatly simplify data interchange between Python applications and other tools.
- Internationalization is supported by a number of modules including gettext,locale, and thecodecs package.
The string module includes a versatileTemplate class with a simplified syntax suitable for editing by end-users. This allows users to customize their applications without having to alter the application.
The string module includes a versatileTemplate class with a simplified syntax suitable for editing by end-users.Thesubstitute() method raises aKeyError when a placeholder is not supplied in a dictionary or a keyword argument, thesafe_substitute() method may be more appropriate — it will leave placeholders unchanged if data is missing.
>>> from string import Template
>>> t = Template('${village}folk send $$10 to $cause.')
>>> t.substitute(village='Nottingham', cause='the ditch fund')
'Nottinghamfolk send $10 to the ditch fund
threading module can run tasks in background while the main program continues to run. The principal challenge of multi-threaded applications is coordinating threads that share data or other resources. To that end, the threading module provides a number of synchronization primitives including locks, events, condition variables, and semaphores.
The queue module implements multi-producer, multi-consumer queues. It is especially useful in threaded programming when information must be exchanged safely between multiple threads. The Queue class in this module implements all the required locking semantics. It depends on the availability of thread support in Python; see thethreading module.
The module implements three types of queue, which differ only in the order in which the entries are retrieved. In a FIFO queue, the first tasks added are the first retrieved. In a LIFO queue, the most recently added entry is the first retrieved (operating like a stack). With a priority queue, the entries are kept sorted (using the heapq module) and the lowest valued entry is retrieved first.
Example of how to wait for enqueued tasks to be completed:
def worker():
while True:
item = q.get()
do_work(item)
q.task_done()
q = Queue()
for i in range(num_worker_threads):
t = Thread(target=worker)
t.daemon = True
t.start()
for item in source():
q.put(item)
q.join() # block until all tasks are done
collections.deque is an alternative implementation of unbounded queues with fast atomic append() and popleft() operations that do not require locking.
import threading, zipfile
class AsyncZip(threading.Thread):
def __init__(self, infile, outfile):
threading.Thread.__init__(self)
self.infile = infile
self.outfile = outfile
def run(self):
f = zipfile.ZipFile(self.outfile, 'w', zipfile.ZIP_DEFLATED)
f.write(self.infile)
f.close()
print('Finished background zip of:', self.infile)
background = AsyncZip('mydata.txt', 'myarchive.zip')
background.start()
print('The main program continues to run in foreground.')
background.join() # Wait for the background task to finish
print('Main program waited until background was done.')
The design of this module is loosely based on Java’s threading model. However, where Java makes locks and condition variables basic behavior of every object, they are separate objects in Python. Python’sThread class supports a subset of the behavior of Java’s Thread class; currently, there are no priorities, no thread groups, and threads cannot be destroyed, stopped, suspended, resumed, or interrupted. The static methods of Java’s Thread class, when implemented, are mapped to module-level functions.
The Thread class represents an activity that is run in a separate thread of control. There are two ways to specify the activity: by passing a callable object to the constructor, or by overriding the run() method in a subclass.Python does automatic memory management (reference counting for most objects andgarbage collection to eliminate cycles). The memory is freed shortly after the last reference to it has been eliminated.This approach works fine for most applications but occasionally there is a need to track objects only as long as they are being used by something else. Unfortunately, just tracking them creates a reference that makes them permanent. Theweakref module provides tools for tracking objects without creating a reference. When the object is no longer needed, it is automatically removed from a weakref table and a callback is triggered for weakref objects. Typical applications include caching objects that are expensive to create.
There is the possibility that “dummy thread objects” are created. These are thread objects corresponding to “alien threads”, which are threads of control started outside the threading module, such as directly from C code. Dummy thread objects have limited functionality; they are always considered alive and daemonic, and cannot be join()ed. They are never deleted, since it is impossible to detect the termination of alien threads.
>>> import weakref, gc
>>> class A:
... def __init__(self, value):
... self.value = value
... def __repr__(self):
... return str(self.value)
...
>>> a = A(10) # create a reference
>>> d = weakref.WeakValueDictionary()
>>> d['primary'] = a # does not create a reference
>>> d['primary'] # fetch the object if it is still alive
10
>>> del a # remove the one reference
>>> gc.collect() # run garbage collection right away
0
>>> d['primary'] # entry was automatically removed
Traceback (most recent call last):
File "" , line 1, in
The heapq module provides functions for implementing heaps based on regular lists. The lowest valued entry is always kept at position zero. This is useful for applications which repeatedly access the smallest element but do not want to run a full list sort.
The most versatile is the list, which can be written as a list of comma-separated values (items) between square brackets. List items need not all have the same type.All slice operations return a new list containing the requested elements.Assignment to slices is also possible, and this can even change the size of the list or clear it entire. Add something to the end of the list via the append(value) method, and the instert could insert a value at the set position. sub-sequence of the Fibonacci series as follows:
>>> # Fibonacci series:
... # the sum of two elements defines the next
... a, b = 0, 1
>>> while b < 10:
... print(b)
... a, b = b, a+b
Python’s for statement iterates over the items of any sequence (a list or a string), in the order that they appear in the sequence.
Important warning: The default value is evaluated only once. This makes a difference when the default is a mutable object such as a list, dictionary, or instances of most classes. For example, the following function accumulates the arguments passed to it on subsequent calls:
def f(a, L=[]):
L.append(a)
return L
print(f(1))
print(f(2))
print(f(3))
This will print
[1]
[1, 2]
[1, 2, 3]
If you don’t want the default to be shared between subsequent calls, you can write the function like this instead:
def f(a, L=None):
if L is None:
L = []
L.append(a)
return L
In a function call, keyword arguments must follow positional arguments. When a final formal parameter of the form**name is present, it receives a dictionary (seeMapping Types — dict) containing all keyword arguments except for those corresponding to a formal parameter.
>>> def concat(*args, sep="/"):
... return sep.join(args) # notice the join method of the string
...
>>> concat("earth", "mars", "venus")
'earth/mars/venus'
>>> concat("earth", "mars", "venus", sep=".")
'earth.mars.venus'
the arguments are already in a list or tuple but need to be unpacked for a function call requiring separate positional arguments.the function call with the*-operator to unpack the arguments out of a list or tuple. In the same fashion, dictionaries can deliver keyword arguments with the**-operator. With thelambda keyword, small anonymous functions can be created,Here’s a function that returns the sum of its two arguments:lambdaa,b:a+b. Lambda forms can be used wherever function objects are required. They are syntactically restricted to a single expression. Semantically, they are just syntactic sugar for a normal function definition. Like nested function definitions, lambda forms can reference variables from the containing scope:
>>> def make_incrementor(n):
... return lambda x: x + n
...
>>> f = make_incrementor(42)
>>> f(0)
42
>>> f(1)
43
Annotations are stored in the __annotations__ attribute of the function as a dictionary and have no effect on any other part of the function. Parameter annotations are defined by a colon after the parameter name, followed by an expression evaluating to the value of the annotation. Return annotations are defined by a literal->, followed by an expression, between the parameter list and the colon denoting the end of thedef statement
wxWidgets¶
wxWidgets (http://www.wxwidgets.org) is a free, portable GUI class library written in C++ that provides a native look and feel on a number of platforms, with Windows, MacOS X, GTK, X11, all listed as current stable targets. Language bindings are available for a number of languages including Python, Perl, Ruby, etc.
wxPython (http://www.wxpython.org) is the Python binding for wxwidgets. While it often lags slightly behind the official wxWidgets releases, it also offers a number of features via pure Python extensions that are not available in other language bindings. There is an active wxPython user and developer community.
Both wxWidgets and wxPython are free, open source, software with permissive licences that allow their use in commercial products as well as in freeware or shareware.
http://wiki.woodpecker.org.cn/moin/WxPythonInAction
http://www.wxpython.org/
http://wiki.wxpython.org/Getting%20Started : Getting started with wxPython
http://wiki.wxpython.org/AnotherTutorial?bcsi_scan_84C04EB1A8996739=uB122dQlHBRsdQxxfyJfQQEAAAB9TngC
任何wxPython应用程序都需要一个应用程序对象。这个应用程序对象必须是类wx.App或其定制的子类的一个实例。应用程序对象的主要目的是管理幕后的主事件循环。这个事件循环响应于窗口系统事件并分配它们给适当的事件处理器。这个应用程序对象对wxPython进程的管理如此的重要以至于在你的程序没有实例化一个应用程序对象之前你不能创建任何的wxPython图形对象。
wxPython允许你在创建应用程序时设置两个参数。第一个参数是redirect,如果值为True,则重定向到框架,如果值为False,则输出到控制台。如果参数redirect为True,那么第二个参数filename也能够被设置,这样的话,输出被重定向到filename所指定的文件中而不定向到wxPython框架。因此,如果我们将上例中的app = App(redirect=True)改为app = App(False),则输出将全部到控制台中.
在wxPython整个程序关闭的过程期间,wxPython关心的是删除所有的窗口和释放资源。可以在退出过程中定义一个钩子来执行你自己的清理工作。由于wx.App子类的OnExit()方法在最后一个窗口被关闭后且在wxPython的内在的清理过程之前被调用,可以使用OnExit()方法来清理创建的任何非wxPython资源(例如一个数据库连接)。即使使用了wx.Exit()来关闭wxPython程序,OnExit()方法仍将被触发。如果由于某种原因想在最后的窗口被关闭后wxPython应用程序仍然可以继续,使用wx.App的SetExitOnFrameDelete(false)方法来改变默认的行为。有三种方法可以管理紧急关闭:调用wx.App的ExitMainLoop()方法, 调用全局方法wx.Exit() 和 为wx.EVT_QUERY_END_SESSION事件绑定了一个事件处理器,当wxPython得到关闭通知时这个事件处理器将被调用(此种方法可以处理根据wx.CloseEvent,做一些保存文档或关闭连接的工作)。
当创建wx.Frame的子类时,应调用其父类的构造器wx.Frame.__init__()。wx.Frame的构造器所要求的参数如下:
1 wx.Frame(parent, id=-1, title="", pos=wx.DefaultPosition, 2 size=wx.DefaultSize, style=wx.DEFAULT_FRAME_STYLE, 3 name="frame")
我们在别的窗口部件的构造器中将会看到类似的参数。参数的说明如下:
parent:框架的父窗口。对于顶级窗口,这个值是None。框架随其父窗口的销毁而销毁。取决于平台,框架可被限制只出现在父窗口的顶部。在多文档界面的情况下,子窗口被限制为只能在父窗口中移动和缩放。
id:关于新窗口的wxPython ID号。你可以明确地传递一个。或传递-1,这将导致wxPython自动生成一个新的ID。在每一个框架内,ID号必须是唯一的,但是在框架之间你可以重用ID号。ID号的最重要的用处是在指定的对象发生的事件和响应该事件的回调函数之间建立唯一的关联
title:窗口的标题。
pos:一个wx.Point对象,它指定这个新窗口的左上角在屏幕中的位置。在图形用户界面程序中,通常(0,0)是显示器的左上角。这个默认的(-1,-1)将让系统决定窗口的位置。wx.Point类表示一个点或位置。构造器要求点的x和y值。如果不设置x,y值,则值默认为0。可以使用Set(x,y)和Get()函数来设置和得到x和y值。Get()函数返回一个元组。
size:一个wx.Size对象,它指定这个窗口的初始尺寸。这个默认的(-1,-1)将让系统决定窗口的初始尺寸。wx.Size类几乎和wx.Point完全相同,除了实参的名字是width和height。对wx.Size的操作与wx.Point一样。通过传递一个元组给构造器,wxPython将隐含地创建这个wx.Point或wx.Size实例,如frame = wx.Frame(None, -1,pos=(10,10),size=(100,100))
style:指定窗口的类型的常量。可以使用或运算来组合它们。wx.DEFAULT_FRAME_STYLE样式就被定义为如下几个基本样式的组合(要从一个合成的样式中去掉个别的样式,可以使用^操作符):
wx.MAXIMIZE_BOX | wx.MINIMIZE_BOX | wx.RESIZE_BORDER |wx.SYSTEM_MENU | wx.CAPTION | wx.CLOSE_BOX
name:框架的内在的名字。以后你可以使用它来寻找这个窗口。
记住,这些参数将被传递给父类的构造器方法:wx.Frame.__init__()。
在wxPython中,如果只有一个子窗口的框架被创建,那么那个子窗口(例2.3中是wx.Panel)被自动重新调整尺寸去填满该框架的客户区域。这个自动调整尺寸将覆盖关于这个子窗口的任何位置和尺寸信息,尽管关于子窗口的信息已被指定,这些信息将被忽略。这个自动调整尺寸仅适用于框架内或对话框内的只有唯一元素的情况。这里按钮是panel的元素,而不是框架的,所以要使用指定的尺寸和位置。如果没有为这个按钮指定尺寸和位置,它将使用默认的位置(panel的左上角)和基于按钮标签的长度的尺寸。显式地指定所有子窗口的位置和尺寸是十分乏味的 《= wxPython使用了称为sizers的对象来管理子窗口的复杂布局。
Python 事件处理:小结
wxPython程序的实现基于两个必要的对象:应用程序对象和顶级窗口。任何wxPython应用程序都需要去实例化一个wx.App,并且至少有一个顶级窗口。
应用程序对象包含OnInit()方法,它在启动时被调用。在这个方法中,通常要初始化框架和别的全局对象。wxPython应用程序通常在它的所有的顶级窗口被关闭或主事件循环退出时结束。
应用程序对象也控制wxPython文本输出的位置。默认情况下,wxPython重定向stdout和stderr到一个特定的窗口。这个行为使得诊断启动时产生的错误变得困难了。但是我们可以通过让wxPython把错误消息发送到一个文件或控制台窗口来解决。
一个wxPython应用程序通常至少有一个wx.Frame的子类。一个wx.Frame对象可以使用style参数来创建组合的样式。每个wxWidget对象,包括框架,都有一个ID,这个ID可以被应用程序显式地赋值或由wxPython生成。子窗口是框架的内容,框架是它的双亲。通常,一个框架包含一个单一的wx.Panel,更多的子窗口被放置在这个Panel中。框架的唯一的子窗口的尺寸自动随其父框架的尺寸的改变而改变。框架有明确的关于管理菜单栏、工具栏和状态栏的机制。
- 尽管你将使用框架做任何复杂的事情,但当你想简单而快速地得到来自用户的信息时,你可以给用户显示一个标准的对话窗口。对于很多任务都有标准的对话框,包括警告框、简单的文本输入框和列表选择框等等。
wx.EvtHandler类定义的一些方法有AddPendingEvent(event):将这个event参数放入事件处理系统中,GetEvtHandlerEnabled():如果处理器当前正在处理事件,则属性为True,否则为False, SetEvtHandlerEnabled( boolean):一个窗口可以被设置为允许或不允许事件处理,ProcessEvent(event):把event对象放入事件处理系统中以便立即处理 和Bind()。最经常是Bind(),它创建事件绑定, 而wx.EvtHandler是所有可显示对象的父类。因此绑定代码行可以被放置在任何显示类.该方法的用法如下:
1 Bind(event, handler, source=None, id=wx.ID_ANY, id2=wx.ID_ANY)
Bind()函数将一个事件和一个对象与一个事件处理器函数关联起来。参数event是必选的,是事件类型 。参数handler也是必选的,它是一个可调用的Python对象,通常是一个被绑定的方法或函数。处理器必须是可使用一个参数(事件对象本身)来调用的。参数handler可以是None,这种情况下,事件没有关联的处理器。参数source是产生该事件的源窗口部件,这个参数在触发事件的窗口部件与用作事件处理器的窗口部件不相同时使用。通常情况下这个参数使用默认值None,这是因为你一般使用一个定制的wx.Frame类作为处理器,并且绑定来自于包含在该框架内的窗口部件的事件。父窗口的__init__是一个用于声明事件绑定的方便的位置。但是如果父窗口包含了多个按钮敲击事件源(比如OK按钮和Cancel按钮),那么就要指定source参数以便wxPython区分它们。Bind()方法中的参数id和id2使用ID号指定了事件的源。一般情况下这没必要,因为事件源的ID号可以从参数source中提取。但是某些时候直接使用ID是合理的。例如,如果你在使用一个对话框的ID号,这比使用窗口部件更容易。如果你同时使用了参数id和id2,你就能够以窗口部件的ID号形式将这两个ID号之间范围的窗口部件绑定到事件。这仅适用于窗口部件的ID号是连续的。例如: self.Bind(wx.EVT_BUTTON,self.OnClick,aButton) 本例使用了预定义的事件绑定器对象wx.EVT_BUTTON来将aButton对象上的按钮单击事件与方法self.OnClick相关联起来。
事件绑定器由类wx.PyEventBinder的实例组成, 事件绑定器被用于将一个wxPython窗口部件与一个事件对象和一个处理器函数连接起来。绑定机制的好处是它使得wxPython可以很细化地分派事件,而仍然允许同类的类似事件发生并且共享数据和功能。这使得在wxPython中写事件处理比在其它界面工具包中清细得多。类wx.PyEventBinder有许多预定义的实例,每个都对应于一个特定的事件类型。
所有的wxPython事件是wx.Event类的子类。低级的事件,如鼠标敲击,被用来建立高级的事件,如按钮敲击或菜单项选择。这些由wxPython窗口部件引起的。高级事件是类wx.CommandEvent的子类。大多的事件类通过一个事件类型字段被进一步分类,事件类型字段区分事件。几种重要的事件对象,也是是类wx.Event的子类:
wx.CloseEvent:当一个框架关闭时触发。这个事件的类型分为一个通常的框架关闭和一个系统关闭事件。
wx.CommandEvent:与窗口部件的简单的各种交互都将触发这个事件,如按钮单击、菜单项选择、单选按钮选择。这些交互有它各自的事件类型。许多更复杂的窗口部件,如列表等则定义wx.CommandEvent的子类。事件处理系统对待命令事件与其它事件不同。
wx.KeyEvent:按按键事件。这个事件的类型分按下按键、释放按键、整个按键动作。
wx.MouseEvent:鼠标事件。这个事件的类型分鼠标移动和鼠标敲击。对于哪个鼠标按钮被敲击和是单击还是双击都有各自的事件类型。
wx.PaintEvent:当窗口的内容需要被重画时触发。
wx.SizeEvent:当窗口的大小或其布局改变时触发。
wx.TimerEvent:可以由类wx.Timer类创建,它是定期的事件。
一个事件类可以有多个事件类型,每个都对应于一个不同的用户行为, 事件类型的名字都是以wx.EVT_开头并且对应于使用在C++ wxWidgets代码中宏的名字。以下为wx.MouseEvent的部分事件类型:
wx.EVT_LEFT_DOWN wx.EVT_LEFT_UP wx.EVT_LEFT_DCLICK wx.EVT_MIDDLE_DOWN wx.EVT_MIDDLE_UP wx.EVT_MIDDLE_DCLICK wx.EVT_RIGHT_DOWN wx.EVT_RIGHT_UP wx.EVT_RIGHT_DCLICK
另外,类型wx.EVT_MOTION产生于用户移动鼠标。类型wx.ENTER_WINDOW和wx.LEAVE_WINDOW产生于当鼠标进入或离开一个窗口部件时。类型wx.EVT_MOUSEWHEEL被绑定到鼠标滚轮的活动。最后,你可以使用类型wx.EVT_MOUSE_EVENTS一次绑定所有的鼠标事件到一个函数。
同样,类wx.CommandEvent有28个不同的事件类型与之关联;尽管有几个仅针对老的Windows操作系统。它们中的大多数是专门针对单一窗口部件的,如wx.EVT_BUTTON用于按钮敲击,wx.EVT_MENU用于菜单项选择。用于专门窗口部件的命令事件在part2中讨论。
wx.Event的方法Skip(): 事件通常被发送给产生它们的对象,以搜索一个绑定对象,这个绑定对象绑定事件到一个处理器函数。如果事件是命令事件,这个事件沿容器级向上传递直到一个窗口部件被发现有一个针对该事件类型的处理器。一旦一个事件处理器被发现,对于该事件的处理就停止,除非这个处理器调用了该事件的Skip()方法。可以允许多个处理器去响应一个事件,或去核查该事件的所有默认行为。事件的第一个处理器函数被发现并执行完后,该事件处理将终止,除非在处理器返回之前调用了该事件的Skip()方法。调用Skip()方法允许另外被绑定的处理器被搜索.
要更直接地管理主事件循环,可以使用一些wx.App方法来修改它。例如,按计划,可能想开始处理下一个有效的事件,而非等待wxPython去开始处理。如果正在执行一个长时间的过程,并且不想图形界面被冻结,那么这个特性是必要的,通常不需要使用这节中的这些方法,但是,这些性能有时是很重要的。可以用来修改主循环的wx.App方法:
Dispatch():迫使事件队列中的下一个事件被发送。通过MainLoop()使用或使用在定制的事件循环中。
Pending():如果在wxPython应用程序事件队列中有等待被处理的事件,则返回True。
Yield(onlyIfNeeded=False):允许等候处理的wxWidgets事件在一个长时间的处理期间被分派,否则窗口系统将被锁定而不能显示或更新。如果等候处理的事件被处理了,则返回True,否则返回False。 onlyIfNeeded参数如果为True,那么当前的处理将让位于等候处理的事件。如果该参数为False,那么递归调用Yield是错误的。 这里也有一个全局函数wx.
SafeYield(),它阻止用户在Yield期间输入数据(这通过临时使用来输入的窗口部件无效来达到目的),以免干扰Yield任务。
设计UI
重构的一些重要原则
不要重复:你应该避免有多个相同功能的段。当这个功能需要改变时,这维护起来会很头痛。
一次做一件事情:一个方法应该并且只做一件事情。各自的事件应该在各自的方法中。方法应该保持短小。
嵌套的层数要少:尽量使嵌套代码不多于2或3层。对于一个单独的方法,深的嵌套也是一个好的选择。
避免字面意义上的字符串和数字:字面意义上的字符串和数字应使其出现在代码中的次数最小化。一个好的方法是,把它们从你的代码的主要部分中分离出来,并存储于一个列表或字典中。
这些原则在Python代码中特别重要。因为Python的缩进语法、小而简洁的方法是很容易去读的。然而,长的方法对于理解来说是更困难的,尤其是如果它们在一个屏幕上不能完全显示出来时。类似的,Python中的深的嵌套使得跟踪代码块的开始和结尾很棘手。然而,Python在避免重复方面是十分好的一种语言,特别是因为函数和方法或以作为参数传递。
标准MVC体系的组成
Model:包含业务逻辑,包含所有由系统处理的数据。它包括一个针对外部存储(如一个数据库)的接口。通常模型(model)只暴露一个公共的API给其它的组分。
View:包含显示代码。这个窗口部件实际用于放置用户在视图中的信息。在wxPython中,处于wx.Window层级中的所有的东西都是视图(view)子系统的一部分。
Controller:包含交互逻辑。该代码接受用户事件并确保它们被系统处理。在wxPython中,这个子系统由wx.EvtHandler层级所代表。
在现代的UI工具包中,View和Controller组分是被集成在一起的。这是因为Controller组分自身需要被显示在屏幕上,并且因为经常性的你想让显示数据的窗口部件也响应用户事件。在wxPython中,这种关系实际上已经被放置进去了(所有的wx.Window对象也都是wx.EvtHandler的子类),这意味着它们同时具有View元素和Controller元素的功能。相比之下,大部分web应用架构对于View和Controller有更严格的分离,因为其交互逻辑发生在服务器的后台。
前缀Py表明这是一个封装了C++类的特定的Python类。PyGridTableBase的实现是基于简单封装一个wxWidgets C++类,这样的目的是使得能够继续声明该类(Python形式的类)的子类。PyGridTableBase对于网格是一个模型类。也就是说,网格对象可能使用PyGridTableBase所包含的方法来绘制自身,而不必了解有关绘制数据的内部结构。
- getattr ( object, name [, default ] ) ¶
-
Return the value of the named attribute of object. name must be a string. If the string is the name of one of the object’s attributes, the result is the value of that attribute. For example,getattr(x,'foobar') is equivalent to x.foobar. If the named attribute does not exist,default is returned if provided, otherwiseAttributeError is raised.
1 class AbstractModel(object): 2 3 def __init__(self): 4 self.listeners = [] 5 6 def addListener(self, listenerFunc): 7 self.listeners.append(listenerFunc) 8 9 def removeListener(self, listenerFunc): 10 self.listeners.remove(listenerFunc) 11 12 def update(self): 13 for eachFunc in self.listeners: 14 eachFunc(self)
当写用户测试的时候,使用已有的测试引擎来节省减少重复的写代码的运行你的测试是有帮助的。自2.1版以来,Python已发布了unittest模块。unittest模块使用一名为PyUnit的测试框架(参见http://pyunit.sourceforge.net/)。PyUnit模块由Test,TestCase,TestSuite组成。
Test:被PyUnit引擎调用的一个单独的方法。根据约定,一个测试方法的名字以test开头。测试方法通常执行一些代码,然后执行一个或多个断定语句来测试结果是否是预期的。
TestCase:一个类,它定义了一个或多个单独的测试,这些测试共享一个公共的配置。这个类定义在PyUnit中以管理一组这样的测试。TestCase在测试前后对每个测试都提供了公共配置支持,确保每个测试分别运行。TestCase也定义了一些专门的断定方法,如assertEqual。
TestSuite:为了同时被执行而组合在一起的一个或多个test方法或TestCase对象。当你告诉PyUnit去执行测试时,你传递给它一个TestSuite对象去执行。
单个的PyUnit测试可能有三种结果:success(成功), failure(失败), 或error(错误)。success表明测试完成,所有的断定都为真(通过),并且没有引发错误。也就是说得到了我们所希望的结果。Failure和error表明代码存在问题。failure意味着你的断定之一返回false,表明代码执行成功了,但是没有做你预期的事。error意味着测试执行到某处,触发了一个Python异常,表明你的代码没有运行成功。在单个的测试中,failure或error一出现,整个测试就终止了,即使在代码中还有多个断定要测试,然后测试的执行将移到到下一个单个的测试。
对模型例子进行单元测试的一个范例
1 import unittest 2 import modelExample 3 import wx 4 5 class TestExample(unittest.TestCase): #1 声明一个TestCase 6 7 def setUp(self): #2 为每个测试所做的配置 8 self.app = wx.PySimpleApp() 9 self.frame = modelExample.ModelExample(parent=None, id=-1) 10 11 def tearDown(self): #3 测试之后的清除工作 12 self.frame.Destroy() 13 14 def testModel(self): #4 声明一个测试(Test) 15 self.frame.OnBarney(None) 16 self.assertEqual("Barney", self.frame.model.first, 17 msg="First is wrong") #5 对于可能的失败的断定 18 self.assertEqual("Rubble", self.frame.model.last) 19 20 21 22 def suite(): #6 创建一个TestSuite 23 suite = unittest.makeSuite(TestExample, 'test') 24 return suite 25 26 if __name__ == '__main__': 27 unittest.main(defaultTest='suite') #7 开始测试
切换行号显示 自动生成按钮敲击事件,以及确保正确的处理器被调用
1 def testEvent(self): 2 panel = self.frame.GetChildren()[0] 3 for each in panel.GetChildren(): 4 if each.GetLabel() == "Wilmafy": 5 wilma = each 6 break 7 event = wx.CommandEvent(wx.wxEVT_COMMAND_BUTTON_CLICKED, wilma.GetId()) 8 wilma.GetEventHandler().ProcessEvent(event) 9 self.assertEqual("Wilma", self.frame.model.first) 10 self.assertEqual("Flintstone", self.frame.model.last)
本例开始的几行寻找一个适当的按钮(这里是"Wilmafy"按钮)。由于我们没有显式地把这些按钮存储到变量中,所以我们就需要遍历panel的孩子列表,直到我们找到正确的按钮。接下来的两行创建用以被按钮发送的wx.CommandEvent事件,并发送出去。参数wx.wxEVT_COMMAND_BUTTON_CLICKED是一个常量,它表示一个事件类型,是个整数值,它被绑定到EVT_BUTTON事件绑定器对象。(你能够在wx.py文件中发现这个整数常量)。wilma.GetId()的作用是设置产生该事件的按钮ID。至此,该事件已具有了实际wxPython事件的所有相关特性。然后我们调用ProcessEvent()来将该事件发送到系统中。如果代码按照计划工作的话,那么模型的first和last中的名字将被改变为“Wilma” 和 “Flintstone”。
通过生成事件,你能够从头到尾地测试你的系统的响应性。理论上,你可以生成一个鼠标按下和释放事件以确保响应按钮敲击的按钮敲击事件被创建。但是实际上,这不会工作,因为低级的wx.Events没有被转化为本地系统事件并发送到本地窗口部件。然而,当测试自定义的窗口部件时,可以用到类似于第三章中两个按钮控件的处理。此类单元测试,对于你的应用程序的响应性可以给你带来信心。
小结
1、众所周知,GUI代码看起来很乱且难于维护。这一点可以通过一点努力来解决,当代码以后要变动时,我们所付出的努力是值得的。
2、重构是对现存代码的改进。重构的目的有:避免重复、去掉无法理解的字面值、创建短的方法(只做一件事情)。为了这些目标不断努力将使你的代码更容易去读和理解。另外,好的重构也几乎避免了某类错误的发生(如剪切和粘贴导致的错误)。
3、把你的数据从代码中分离出来,使得数据和代码更易协同工作。管理这种分离的标准机制是MVC机制。用wxPython的术语来说,V(View)是wx.Window对象,它显示你的数据;C(Controller)是wx.EvtHandler对象,它分派事件;M(Model)是你自己的代码,它包含被显示的信息。
4、或许MVC结构的最清晰的例子是wxPython的核心类中的wx.grid.PyGridTableBase,它被用于表示数据以在一个wx.grid.Grid控件中显示。表中的数据可以来自于该类本身,或该类可以引用另一个包含相关数据的对象。
5、你可以使用一个简单的机制来创建你自己的MVC设置,以便在模型被更新时通知视图(view)。在wxPython中也有现成的模块可以帮助你做这样的事情。
6、单元测试是检查你的程序的正确性的一个好的方法。在Python中,unittest模块是执行单元测试的标准方法中的一种。使一些包,对一个GUI进行单元测试有点困难,但是wxPython的可程序化的创建事件使得这相对容易些了。这使得你能够从头到尾地去测试你的应用程序的事件处理行为。
要在屏幕上绘画,我们要用到一个名为device context(设备上下文)的wxPython对象。设备上下文代表抽象的设备,它对于所有的设备有一套公用的绘画方法,所以对于不同的设备,你的代码是相同的,而不用考虑你所在的具体设备。设备上下文使用抽象的wxPython的类wx.DC和其子类来代表。由于wx.DC是抽象的,所以对于你的应用程序,你需要使用它的子类。设备上下文用来在wxPython窗口部件上绘画,它应该是局部的,临时性的,不应该以实例变量、全局变量或其它形式在方法调用之间保留。在某些平台上,设备上下文是有限的资源,长期持有wx.DC可能导致你的程序不稳定。由于wxPython内部使用设备上下文的方式,对于在窗口部件中绘画,就存在几个有着细微差别的wx.DC的子类。
在wxPython中,有两个用于缓存的类:wx.BufferDC(通常用于缓存一个wx.ClientDC)、wx.BufferPaintDC(用于缓存一个wx.PaintDC)。它们工作方式基本上一样。缓存设备上下文的创建要使用两个参数。第一个是适当类型的目标设备上下文(例如,在例6.1中的#9,它是一个新的wx.ClientDC实例)。第二个是一个wx.Bitmap对象。在例6.1中,我们使用函数wx.EmptyBitmap创建一个位图。当绘画命令到缓存的设备上下文时,一个内在的wx.MemoryDC被用于位图绘制。当缓存对象被销毁时,C++销毁器使用Blit()方法去自动复制位图到目标。在wxPython中,销毁通常发生在对象退出作用域时。这意味缓存的设备上下文仅在临时创建时有用,所以它们能够被销毁并能用于块传送(blit)。
wx.StatusBar的方法
GetFieldsCount() SetFieldsCount(count):得到或设置状态栏中域的数量。
GetStatusText(field=0) SetStatusText(text, field=0):得到或设置指定域中的文本。0是默认值,代表最左端的域。
PopStatusText(field=0):弹出堆栈中的文本到指定域中,以改变域中的文本为弹出值。
PushStatusText(text, field=0):改变指定的域中的文本为给定的文本,并将改变前的文本压入堆栈的顶部。
SetStatusWidths(widths):指定各状态域的宽度。widths是一个整数的Python列表。
要创建一个子菜单,首先和创建别的菜单方法一样创建一个菜单,然后再使用wx.Menu.AppendMenu()将它添加给父菜单。
带有复选或单选菜单的菜单可以通过使用wx.Menu的AppendCheckItem()和AppendRadioItem()方法来创建,或通过在wx.MenuItem的创建器中使参数kind的属性值为下列之一来创建:wx.ITEM_NORMAL, wx.ITEM_CHECKBOX, 或wx.ITEM_RADIO。要使用编程的方法来选择一个菜单项,可以使wx.Menu的Check(id,bool)方法,id是所要改变项的wxPython ID,bool指定了该项的选择状态。
菜单栏和工具栏通常是紧密联系在一起的,工具栏的绝大部分功能与菜单项相对应。在wxPython中,这通过工具栏被敲击时发出wx.EVT_MENU事件,这样就可很容易地在处理菜单项的选择和工具栏的敲击时使用相同的方法。一个wxPython工具栏是类wx.ToolBar的一个实例,可以使用框架的方法CreateToolBar()来创建。和状态栏一样,工具栏的大小也随其父框架的改变而自动改变。工具栏与其它的wxPython窗口一样可以拥有任意的子窗口。工具栏也包含创建工具按钮的方法。
wx.ToolBar的常用方法
AddControl(control):添加一个任意的wxPython控件到工具栏。相关方法InsertControl()。
AddSeparator():在工具之间放置空格。
AddSimpleTool(id, bitmap,shortHelpString="",kind=wx.ITEM_NORMAL):添加一个简单的带有给定位图的工具到工具栏。shortHelpString作为提示显示。kind的值可以是wx.ITEM_NORMAL, wx.ITEM_CHECKBOX, 或wx.ITEM_RADIO。
AddTool(id, bitmap,bitmap2=wx.NullBitmap,kind=wx.ITEM_NORMAL,shortHelpString="",longHelpString="", clientData=None):简单工具的其它参数。bitmap2是当该工具被按下时所显示的位图。longHelpString是当指针位于该工具中时显示在状态栏中的帮助字符串。clientData用于将任意的一块数据与工具相联系起来。相关方法InsertTool()。
AddCheckTool(...):添加一个复选框切换工具,所要求参数同AddTool()。
AddRadioTool(...):添加一个单选切换工具,所要求参数同AddTool()。对于连续的未分隔的单选工具被视为一组。
DeleteTool(toolId) DeleteToolByPosition(x, y):删除所给定的id的工具,或删除给定显示位置的工具。
FindControl(toolId) FindToolForPosition(x, y):查找并返回给定id或显示位置的工具。
ToggleTool(toolId, toggle):根据布尔什toggle来设置给定id的工具的状态。
wx.FileDialog构造器的参数
parent:对话框的父窗口。如果没有父窗口则为None。
message:message显示在对话框的标题栏中。
defaultDir:当对话框打开时,默认的目录。如果为空,则为当前工作目录。
defaultFile:当对话框打开时,默认选择的文件。如果为空,则没有文件被选择。
wildcard:通配符。指定要选择的文件类型。格式是 display | wildcard 。可以指定多种类型的文件,例如:“Sketch files (*.sketch)|*.sketch|All files (*.*)|*.*”。
标准的颜色选择器
能够在对话框中选择任意的颜色,那么这将是有用。对于这个目的,我们可以使用wxPython提供的标准wx.ColourDialog。这个对话框的用法类似于文件对话框。它的构造器只需要一个parent(双亲)和一个可选的数据属性参数。数据属性是一个wx.ColourData的实例,它存储与该对话框相关的一些数据,如用户选择的颜色,还有自定义的颜色的列表。使用数据属性使你能够在以后的应用中保持自定义颜色的一致性。
在你的wxPython应用程序中布局你的窗口部件的方法之一是,在每个窗口部件被创建时显式地指定它的位置和大小。虽然这个方法相当地简单,但是它一直存在几个缺点。其中之一就是,因为窗口部件的尺寸和默认字体的尺寸不同,对于在所有系统上要得到一个正确的定位是非常困难的。另外,每当用户调整父窗口的大小时,你必须显式地改变每个窗口部件的定位,要正确地实现它是十分痛苦的。
幸运的是,这儿有一个更好的方法。在wxPython中的布局机制是一个被称为sizer的东西,它类似于Java AWT和其它的界面工具包中的布局管理器。每个不同的sizer基于一套规则管理它的窗口的尺寸和位置。sizer属于一个容器窗口(比如wx.Panel)。在父中创建的子窗口必须被添加给sizer,sizer管理每个窗口部件的尺寸和位置。
创建一个sizer
创建一个sizer的步骤:
1、创建你想用来自动调用尺寸的panel或container(容器)。 2、创建sizer。 3、创建你的子窗口。 4、使用sizer的Add()方法来将每个子窗口添加给sizer。当你添加窗口时,给了sizer附加的信息,这包括窗口周围空间的度量、在由sizer所管理分配的空间中如何对齐窗口、当容器窗口改变大小时如何扩展子窗口等。 5、sizer可以嵌套,这意味你可以像窗口对象一样添加别的sizer到父sizer。你也可以预留一定数量的空间作为分隔。6、调用容器的SetSizer(sizer)方法。
下面列出了在wxPython中有效的最常用的sizer。对于每个专门的sizer的更完整的说明见第11章。
最常用的wxPython的sizer
wx.BoxSizer:在一条线上布局子窗口部件。wx.BoxSizer的布局方向可以是水平或坚直的,并且可以在水平或坚直方向上包含子sizer以创建复杂的布局。在项目被添加时传递给sizer的参数控制子窗口部件如何根据box的主体或垂直轴线作相应的尺寸调整。
wx.FlexGridSizer:一个固定的二维网格,它与wx.GridSizer的区别是,行和列根据所在行或列的最大元素分别被设置。
wx.GridSizer:一个固定的二维网格,其中的每个元素都有相同的尺寸。当创建一个grid sizer时,你要么固定行的数量,要么固定列的数量。项目被从左到右的添加,直到一行被填满,然后从下一行开始。
wx.GridBagSizer:一个固定的二维网格,基于wx.FlexGridSizer。允许项目被放置在网格上的特定点,也允许项目跨越多和网格区域。
wx.StaticBoxSizer:等同于wx.BoxSizer,只是在box周围多了一个附加的边框(有一个可选的标签)。
about框是显示对话框的一个好的例子,它能够显示比纯信息框更复杂的信息。这里,你可以使用wx.html.HtmlWindow作为一个简单的机制来显示样式文本。实际上,wx.html.HtmlWindow远比我们这里演示的强大,它包括了管理用户交互以及绘制的方法显示一个好的启动画面,将给你的用户一种专业化的感觉。在你的应用程序完成一个费时的设置的时候,它也可以转移用户的注意力。在wxPython中,使用类wx.SplashScreen建造一个启动画面是很容易的。启动画面可以保持显示指定的时间,并且无论时间是否被设置,当用户在其上敲击时,它总是会关闭。
创建树形控件并添加项目
树形控件是类wx.TreeCtrl的实例. wx.TreeControl(parent,id=-1,pos=wx.DefaultPosition, size=wx.DefaultSize,style=wx.TR_HAS_BUTTONS, validator=wx.DefaultValidator,name="treeCtrl"),treeCtrl的实例有很多方法可以很方便的操纵:
添加一个根元素:
AddRoot(text, image=-1, selImage=-1, data=None) : 返回一个关于根项目的ID。树形控件使用它自己的类wx.TreeItemId来管理项目
向树中添加元素,用的最多的方法是AppendItem(parent, text, image=-1, selImage=-1, data=None)。参数parent是已有的树项目的wx.TreeItemId,它作为新项目的父亲。
删除树中元素,使用Delete(item)方法,其中item是该项目的wx.TreeItemId。调用这个方法将导致一个EVT_TREE_Delete_ITEM类型的树的事件被触发
使用SetWindowStyle(styles)来改变样式:wx.TR_HAS_BUTTONS,wx.TR_NO_BUTTONS,wx.TR_SINGLE 等等
对树形控件的元素排序的基本机制是方法SortChildren(item)。其中参数item是wx.TreeItemId的一个实例。该方法对此项目的子项目按显示字符串的字母的顺序进行排序。
使用SetItemPyData(item, obj)和GetItemPyData(item)方法
要使用关联的数据来排序树,树必须是一个wx.TreeCtrl的自定义的子类,并且必须覆盖OnCompareItems(item1, item2)方法。其中参数item1, item2是要比较的两个项的wx.TreeItemId实例。如果item1应该排在item2的前面,则方法返回-1,如果item1应该排在item2的后面,则返回1,相等则返回0。该方法是在当树控件为了排序而比较计算每个项时自动被调用的。可以在OnCompareItems()方法中做你想做的事情。尤其是,可以如下调用GetItemPyData()方法:
1 def OnCompareItems(self, item1, item2); 2 data1 = self.GetItemPyData(item1) 3 data2 = self.GetItemPyData(item2) 4 return cmp(data1, data2)
使用编程的方式访问树:
要开始遍历树,我们首先要使用GetRootItem()来得到根元素。该方法返回树的根元素的wx.TreeItemId。之后,你就可以使用诸如GetItemText()或GetItemPyData()之类的方法来获取关于根元素的更多的信息。
一旦你得到了一个项目,你就可以通过迭代器来遍历子项目的列表。你可以使用方法GetFirstChild(item)来得到子树中的第一个孩子,该方法返回一个二元元组(child, cookie)。参数item是第一个孩子的wx.TreeItemId。除了告诉你每一个孩子是什么外,该方法还初始化一个迭代对象,该对象使你能够遍历该树。cookie值只是一个标志,它使得树控件能够同时保持对多个迭代器的跟踪,而它们之间不会彼此干扰。
一旦你由GetFirstChild()得到了cookie,你就可以通过反复调用GetNextChild(item, cookie)来得到其余的孩子。这里的item父项的ID,cookie是由GetFirstChild()或前一个GetNextChild()调用返回的。GetNextChild()方法也返回一个二元元组(child, cookie)。如果此时没有下一个项目了,那么你就到达了孩子列表的末尾,系统将返回一个无效的孩子ID。你可以通过使用wx.TreeItemId.IsOk()或__nonzero__方法测试这种情况。下面的函数返回给定项目的所有孩子的文本的一个列表。
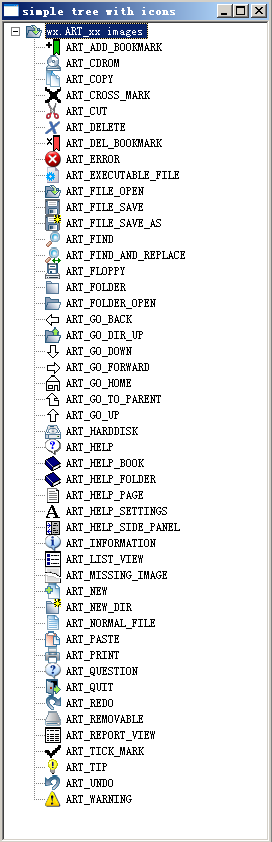
wxPython 预定义了很多图标,wxPython in action 中很多例子也用到这些图标,今天总结了一下这些预定的图标,说不定将来会用得上呢!
下面程序截图,文字就是对应的图标名称,要获得图标,可以使用
cimg = wx.ArtProvider.GetBitmap(wx.ART_ADD_BOOKMARK,wx.ART_OTHER,(16,16)) 语句获得(将暗黄部分换成其他图标的名称)。
The GetItemData and SetItemData now behave just like GetItemPyData and SetItemPyData did in Classic wxPython. In other words, instead of needing to create and use instances of wx.TreeItemData to associate Python data objects with tree items, you just use the Python objects directly. It will also work when passing the data objects directly to the AppendItem, InsertItem, etc. methods. (If anybody was actually using the wx.TreeItemData objects directly before and are unable to adapt then please let Robin know.) The [G|S]etItemPyData members still exist, but are now deprecated aliases for [G|S]etItemData.
小结
1、树控件提供给你了一个如文件树或XML文档样的嵌套紧凑的外观。树控件是类wx.TreeCtrl的实例。有时,人你会想子类化wx.TreeCtrl,尤其是如果你需要实现自定义的排序的时候。
2、要向树中添加项目,首先要用方法AddRoot(text, image=-1, selImage=-1, data=None)。该函数的返回值是一个代表树的root项目的wx.TreeItemId。树控件使用wx.TreeItemId作为它自己的标识符类型,而非和其它控件一样使用整数的ID。一旦你得到了root项,你就可以使用方法AppendItem(parent, text, image=-1, selImage=-1, data=None)来添加子项目,参数parent是父项目的ID。该方法返回新项目的wx.TreeItemId。另外还有一些用来将新的项目添加在不同位置的方法。方法Delete(item)从树中移除一个项目,方法DeleteChildren(item)移除指定项的所有子项目。
SetItemPyData *only* associates your list with a tree item. It doesn't
add an item to the tree. Use AppendItem for that. Don't forget to create
a root item first.
3、树控件有一些用来改变树的显示外观的样式。一套是用来控制展开或折叠项目的按钮类型的。另一套是用来控制项目间的连接线的。第三套是用于控制树是单选还是多选的。你也可以使用样式通过隐藏树的实际的root,来模拟一个有着多个root项的树。
4、默认情况下,树的项目通常是按照显示文本的字母顺序排序的。但是要使这能够实现,你必须给每项分配数据。实现这个的最容易的方法是使用SetItemPyData(item, obj),它给项目分配一个任意的Python对象。如果你想使用该数据去写一个自定义的排序函数,你必须继承wx.TreeCtrl类并覆盖方法OnCompareItems(item1, item2),其中的参数item1和item2是要比较的项的ID。
5、树控件使用一个图像列表来管理图像,类似于列表控件管理图像的方法。你可以使用SetImageList(imageList)或AssignImageList(imageList)来分配一个图像列表给树控件。然后,当新的项目被添加到列表时,你可以将它们与图像列表中的特定的索引联系起来。
6、没有特定的函数可以让你得到一个父项的子项目列表。替而代之的是,你需要去遍历子项目列表,这通过使用方法GetFirstChild(item)作为开始。
7、你可以使用方法SelectItem(item, select=True)来管理树的项目的选择。在一个多选树中,你可以使用ToggleItemSelection(item)来改变给定项的状态。你可以使用IsSelected(item)来查询一个项目的状态。你也可以使用Expand(item)或Collapse(item)展开或折叠一个项,或使用Toggle(item)来切换它的状态。
8、样式wx.TR_EDIT_LABELS使得树控件可为用户所编辑。一个可编辑的列表中,用户可以选择一个项,并键入一个新的标签。按下esc来取消编辑而不对项目作任何改变。你也可以通过 wx.EVT_TREE_END_LABEL_EDIT 事件来否决编辑。类wx.TreeEvent提供了允许访问当前被处理的项目的显示文本的属性。
http://xoomer.virgilio.it/infinity77/wxPython/Widgets/wx.ScrolledWindow.html a very detailed API specification
http://wxpython-users.1045709.n5.nabble.com/template/NamlServlet.jtp?macro=user_nodes&user=81430 a very good place to Q&A of the wxpython
o process a scroll event, use these event handler macros to direct input to member functions that take a wx.ScrollEvent argument. You can use EVT_COMMAND_SCROLL... macros with window IDs for when intercepting scroll events from controls, or EVT_SCROLL... macros without window IDs for intercepting scroll events from the receiving window – except for this, the macros behave exactly the same.
In oder to capture the scroll event of the treeCtrl, two binding methods, the second one would not work.
self.leftTree.Bind(wx.EVT_SCROLLWIN, self.test_pos_top_win)
self.Bind(wx.EVT_SCROLLWIN,self.test_pos_top_win,self.leftTree)
http://wiki.wxpython.org/self.Bind%20vs.%20self.button.Bind
self.Bind vs. self.button.Bind
A common question/confusion that wxPython developers have is what's the difference between
self.Bind(wx.EVT_BUTTON, self.OnButton, self.button)
and
self.button.Bind(wx.EVT_BUTTON, self.OnButton)
where self is some window further up the containment hierarchy than the button. On first glance the answer is "Nothing. They both result in self.OnButton being called when the button is clicked by the user." But there are some deeper currents in this stream and to truly understand how things flow on the surface you need to understand how they flow underneath as well.
wx.Event vs. wx.CommandEvent
First things first. When searching for a binding for a particular event, wxPython will search up the containment hierarchy (parent windows) for events that are instances of wx.CommandEvent, but will not for those that are not. There are several reasons for this, which we won't go into here. Just treat it as a fact of life; be happy and move on.
Okay, I know that isn't going to satisfy some of you, so here is a metaphor. A human parent doesn't need to know every time his child's heart beats, and most of the time the child doesn't care much about it either. But when the child does want to know she can simply put her fingers on her carotid artery and feel the pulse. Of course there is always a way around the limitations if the parent wants to be informed of each heartbeat. He can ask his child to feel her pulse and tap her foot for every heartbeat. Now suppose that the powers that be decided that every child should always feel her pulse and tap her foot for every heartbeat 24x7 just in case a parent or grandparent might be interested in knowing about it. The world would be full of cranky kids and nothing would get done because of all the work needed to tap feet and to report those foot taps to Daddy while he is asleep at work (because he was up all night listening to foot taps), and also to Grandma Betty who lives across town. That's why some events propagate and some don't.
Skipping stones
When an event binding is found for a particular event the application's associated handler function is called. If that handler calls event.Skip() anywhere in the handler wxPython continues searching for more event handlers after that event handler finishes. It doesn't matter at what point in the app's event handler code the event.Skip() statement is executed; it's a "deferred call."
Think of it as skipping stones across a pond. When a binding is found the stone touches the water (the application's event handler is called) and there is a splash and a ring of waves generated (the handler can do something that may affect the state of the application.) At this point the stone may be caught by the water and will sink ( the handler does not call Skip() ) or it may bounce and touch the water again at some other place (the handler does call Skip() and so other bindings are searched for.) If the stone is a wx.CommandEvent then the next place it touches down could be in a parent window, or the parent's parent or so on. Or, it may just land on the opposite bank and not touch the water at all (no other higher level event handlers were found to call).
The Bind method
The Bind() method is how we specify an event binding for wxPython. Not only does it tell the system which kind of event we are looking for, but it also tells the system where to examine that criteria. This "where" part is something that usually takes people a while to understand. For example, in this code where self is a wx.Frame or another container control:
self.Bind(wx.EVT_BUTTON, self.OnButton, self.button)
the binding tells the system to eventually call self.OnButton when it sees a wx.EVT_BUTTON event delivered first to the frame, that originates from self.button. Since self.button is presumably a few layers down the container hierarchy then the frame is potentially not the first splash (EVT_BUTTON handler call) that this stone (event) will make. In other words, the event may also be caught in the panel or in the button first. But in any case, the thing to learn here is that event bindings not only have a matching criteria, but also a hierarchy in which the event handlers are searched for.
Now let's look at the other binding:
self.button.Bind(wx.EVT_BUTTON, self.OnButton)
This tells the system to immediately call self.OnButton for a wx.EVT_BUTTON event (it matches because self.button is being bound) that is caused by self.button. Now for all practical purposes the only button events that self.button is going to get are the ones generated by clicking on the button itself, so it is almost the same as saying that it is only catching events that are coming from this button, just like above. What is different in this case however is where in the containment hierarchy that the event handler search matching is done first. This time it is happening at the position of the button, and unless the handler calls event.Skip() nothing else in the hierarchy will get a chance to see the event. In other words, this is the first and only splash that this stone will make. Most of the time this is perfectly okay. But sometimes it is real handy to be able to allow events to be seen and perhaps intercepted by other handlers before it gets to the one that implements the normal functionality.
wx.Events
So given what you now know from reading the above, it should be clear why bindings for non-command events must be done on the specific window and not on a window further up the containment hierarchy. Since non-command events don't propagate they simply won't be seen if the binding is not done on the window to which the event is first delivered.
Fruit catching robots
Here's one more metaphor to help you picture how things work. This was a response to a series of questions asked on the wxPythonInAction forum, so you may want to read some of the preceding messages to get the whole story.
Suppose you have a large apple tree, and you are interested in collecting the apples from a specific branch when they are ripe, (and assume that they drop from the branch the moment they are ripe.) One way to do this is to install a robot on the ground beneath the branch and each time an apple hits the ground (after having left the branch and passed through the branches in between) the robot will ask the apple if it came from the branch you are interested in and if so will toss the apple into the basket you are collecting them in. The other way to do it is to install a robot directly on the branch in question. When the apple ripens the robot catches it before it can go anywhere else, and tosses it directly to your basket, bypassing the branches in between. Apples that don't have a robot looking for them just pass straight through the branches, hit the ground and then fade away. If a branch isn't directly beneath the source branch then robots attached to those branches don't have a chance to catch the apple.
In this analogy the apples are the events, the robots are the event bindings and the basket is the event handler function. The branch is the button, the ground is the frame, and the branches in between represent the containment hierarchy. So in the case of the self.button.Bind it really isn't the frame reaching down and grabbing messages directed at one of its child widgets. You're just attaching an event binding directly to the child, and in this case the basket it sends the apples to happens to still be located in the frame, but it could just have easily been located on the same branch, a different branch, or even in a different tree.
In the case of non-command events our apples have to take on another magical property, in that they evaporate if they are not caught within the scope of their own branch, but once they are caught by the robot the basket they are sent to can still exist anywhere.
Which is better?
So to get back to "self.Bind vs. self.button.Bind" some of you may be asking which is better. Some people have been suggesting in the mail list to always bind to the widget that generates the event (in other words, the self.button.Bind style) in order to not have to worry about the differences between command events and non-command events. I think that is perfectly okay as long as you understand what you are giving up. It's not often that you need to intercept an event at multiple points of the containment hierarchy, but it is a real handy feature when you do need it. So to answer the question, there is no real definitive answer. Just use what makes the most sense for you, and keep in mind that there are deeper currents in this stream.
‘把窗口部件放入框架中’小结:
1、wxPython中的大部分用户交互都发生在wx.Frame或wx.Dialog中。wx.Frame代表用户调用的窗口。wx.Frame实例的创建就像其它的wxPython窗口部件一样。wx.Frame的典型用法包括创建子类,子类通过定义子窗口部件,布局和行为来扩展基类。通常,一个框架包含只包含一个wx.Panel的顶级子窗口部件或别的容器窗口。基本上应该使用一个wx.Panel作为框架的顶级子窗口部件
2、这儿还有各种特定于wx.Frame的样式标记。其中的一些影响框架的尺寸和形状,另一些影响在系统中相对于其它的框架,它将如何被绘制,还有一些定义了在框架边框上有那些界面装饰。在某种情况下,定义一个样式标记需要“两步”的创建过程。
3、通过调用Close()方法可以产生关闭框架的请求。这给了框架一个关闭它所占用的资源的机会。框架也能否决一个关闭请求。调用Destroy()方法将迫使框架立即消失而没有任何延缓。
4、框架中的一个特定的子窗口部件可以使用它的wxPython ID、名字或它的文本标签来发现。在wxPython中,有三种查找子窗口部件的方法,它们的行为都很相似。这些方法对任何作为容器的窗口部件都是适用的,不单单是框架,还有对话框和面板(panel)。可以通过内部的wxPython ID查寻一个窗口部件,或通过传递给构造函数的名字(在name参数中),或通过文本标签来查寻。文本标签被定义为相应窗口部件的标题,如按钮和框架。这三种方法是:
-
1.wx.FindWindowById(id, parent=None)
1.wx.FindWindowByName(name, parent=None)
1.wx.FindWindowByLabel(label, parent=None)
5、通过包括wx.ScrolledWindow类的容器部件可以实现滚动。这儿有几个方法来设置滚动参数,最简单的是在滚动窗口中使用sizer,在这种情况下,wxPython自动确定滚动面板的虚拟尺寸(virtual size)。如果想的话,虚拟尺寸可以被手动设置。还有一个wxPython的特殊的滚动窗口子类:wx.lib.scrolledpanel.ScrolledPanel,它使得能够在面板上自动地设置滚动,该面板使用一个sizer来管理子窗口部件的布局。wx.lib.scrolledpanel.ScrolledPanel增加的好处是,它让用户能够使用tab键来在子窗口部件间切换。面板自动滚动,使新获得焦点的窗口部件进入视野
6、这儿有一对不同的框架子类,它们允许不同的外观。类wx.MDIParentFrame可以被用来创建MDI,而wx.MiniFrame可以创建一个带有较小标题栏的工具框样式的窗口。使用SetShape()方法,框架可以呈现出非矩形的形状。形状的区域可以被任何位图定义,并使用简单的颜色掩码来决定区域的边缘。非矩形窗口通常没有标准的标题栏,标题栏使得框架可以被拖动, 但这可以通过显式地处理鼠标事件来管理。
7、位于两个子窗口间的可拖动的分割条能够使用wx.SplitterWindow来实现,分割条可以被用户以交互的方式处理,或以编程的方式处理(如果需要的话)。要显示两个子窗口,使用SplitHorizontally (window1,window2,sashPosition=0)或SplitVertically(window1, window2, sashPosition=0)。两个方法的工作都是相似的,参数window1和window2包含两个子窗口,参数sashPosition包含分割条的初始位置。要确定窗口当前是否被分割了,调用方法IsSplit()。如果想不分割窗口,那么使用Unsplit(toRemove=None)。参数toRemove是实际要移除的wx.Window对象,并且必须是这两个子窗口中的一个。一旦分割窗被创建,可以使用窗口的方法来处理分割条的位置。特别是,可以使用方法SetSashPosition(position,redraw=True)来移动分割条。
使用消息框是十分的简单,或者使用类wx.MessageDialog 或者使用wx.MessageBox,后者比前者更简单x.MessageBox()创建对话框,调用ShowModal(),并且返回下列值之一:wx.YES, wx.NO, wx.CANCEL, 或 wx.OK。要想在消息框中显示大量的文本(例如,终端用户许可证的显示),可以使用wxPython特定的类wx.lib.dialogs.ScrolledMessageDialog。wx.TextEntryDialog,它被用于从用户那里得到短的文本输入。它通常用在在程序的开始时要求用户名或密码的时候,或作为一个数据输入表单的基本替代物,文本对话框使用的三个便利方法wx.GetTextFromUser() 2、wx.GetPasswordFromUser() 3、wx.GetNumberFromUser()分别表示用来提示用户输入一个文本,密码和数字。如果给用户一个空的文本输入域显得太自由了,那你可以使用wx.SingleChoiceDialog来让他们在一组选项中作单一的选择。
在许多程序中,程序需要自己做些事情而不受用户输入的干扰。这时就需要给用户一些可见的显示,以表明程序正在做一些事情及完成的进度。在wxPython中,这通常使用一个进度条来管理-wx.ProgressDialog.
在wxPython中,wx.FileDialog为主流的平台使用本地操作系统对话框,对其它操作系统使用非本地相似的外观,和目录选择器,wx.DirDialog.还有字体选择对话框wx.FontDialog,还有颜色选择器wx.ColourDialog.如果你在你的程序中做图形处理,那么在他们浏览文件树时使用缩略图是有帮助的。用于该目的的wxPython对话框被称为wx.lib.imagebrowser.ImageDialog。
对话框小结
1、对话框被用于在有一套特殊的信息需要被获取的情况下,处理与用户的交互,这种交互通常很快被完成。在wxPython中,你可以使用通用的wx.Dialog类来创建你自己的对话框,或者你也可以使用预定义的对话框。大多数情况下,通常被使用的对话框都有相应的便利函数,使得这种对话框的使用更容易。
2、对话框可以显示为模式对话框,这意味在对话框可见时,该应用程序中的用户所有的其它输入将被阻塞。模式对话框通过使用ShowModal()方法来被调用,它的返回值依据用户所按的按钮而定(OK或Cancel)。关闭模式对话框并不会销毁它,该对话框的实例可以被再用。
3、在wxPython中有三个通用的简单对话框。wx.MessageDialog显示一个消息对话框。wx.TextEntryDialog使用户能够键入文本,wx.SingleChoiceDialog给用户一个基于列表项的选择。
4、当正在执行一个长时间的后台的任务时,你可以使用wx.ProgressDialog来给用户显示进度信息。用户可以通过wx.FileDialog使用标准文件对话框来选择一个文件。可以使用wx.DirDialog来创建一个标准目录树,它使得用户可以选择一个目录。
5、你可以使用wx.FontDialog和wx.ColorDialog来访问标准的字体选择器和颜色选择器。在这两种情况中,对话框的行为和用户的响应是由一个单独的数据类来控制的。
6、要浏览缩略图,可以使用wxPython特定的类wx.lib.imagebrowser.ImageDialog。这个类使用户能够通过文件系统并选择一个图像。
7、你可以通过使用wx.wizard.Wizard创建一个向导来将一组相关的对话框表单链接起来。对话框表单是wx.wizard.WizardSimplePage或wx.wizard.WizardPage的实例。两者的区别是,wx.wizard.WizardSimplePage的页到页的路线需要在向导被显示之前就安排好,而wx.wizard.WizardPage使你能够在运行时管理页到页的路线的逻辑。
8、使用wx.CreateFileTipProvider和wx.ShowTip函数可以很容易地显示启动提示。
9、验证器是很有用的对象,如果输入的数据不正确的话,它可以自动阻止对话框的关闭。他们也可以在一个显示的对话框和一个外部的对象之间传输数据,并且能够实时地验证数据的输入。验证器对象是wx.Validator的子类。父类是抽象的,不能直接使用。在wxPython中,你需要定义你自己的验证器类,一个自定义的验证器子类必须覆盖方法Clone(),该方法应该返回验证器的相同的副本。一个验证器被关联到你的系统中的一个特定的窗口部件。这可以用两种方法之一来实现。第一种方法,如果窗口部件许可的话,验证器可以被作为一个参数传递给该窗口部件的构造函数。如果该窗口部件的构造函数没有一个验证器参数,你仍然可以通过创建一个验证器实例并调用该窗口部件的SetValidator(validator)方法来关联一个验证器。
SIZER
用来处理复杂布局的方法是使用sizer。sizer是用于自动布局一组窗口部件的算法。sizer被附加到一个容器,通常是一个框架或面板。在父容器中创建的子窗口部件必须被分别地添加到sizer。当sizer被附加到容器时,它随后就管理它所包含的孩子的布局。最灵活sizer——grid bag和box,能够做你要它们做的几乎任何事。
Grid:一个十分基础的网格布局。当你要放置的窗口部件都是同样的尺寸且整齐地放入一个规则的网格中是使用它。
Flex grid:对grid sizer稍微做了些改变,当窗口部件有不同的尺寸时,可以有更好的结果。
Grid bag:grid sizer系列中最灵活的成员。使得网格中的窗口部件可以更随意的放置。
Box:在一条水平或垂直线上的窗口部件的布局。当尺寸改变时,在控制窗口部件的的行为上很灵活。通常用于嵌套的样式。可用于几乎任何类型的布局。
Static box:一个标准的box sizer。带有标题和环线。
Python Classes
Compared with other programming languages, Python’s class mechanism adds classes with a minimum of new syntax and semantics. It is a mixture of the class mechanisms found in C++ and Modula-3(In computer science, Modula-3 is a programming language conceived as a successor to an upgraded version of Modula-2known as Modula-2+. While it has been influential in research circles (influencing the designs of languages such as Java,C#, and Python) it has not been adopted widely in industry.). Python classes provide all the standard features of Object Oriented Programming: the class inheritance mechanism allows multiple base classes, a derived class can override any methods of its base class or classes, and a method can call the method of a base class with the same name. Objects can contain arbitrary amounts and kinds of data. As is true for modules, classes partake[分享,参与] of the dynamic nature of Python: they are created at runtime, and can be modified further after creation.
aliasing : Objects have individuality, and multiple names (in multiple scopes) can be bound to the same object.A namespaceis a mapping from names to objects. Most namespaces are currently implemented as Python dictionaries, but that’s normally not noticeable(显而易见的,显著的) in any way (except for performance), and it may change in the future. Examples of namespaces are: the set of built-in names (containing functions such asabs(), and built-in exception names); the global names in a module; and the local names in a function invocation. In a sense the set of attributes of an object also form a namespace.
BTW, the word attribute for any name following a dot. Module attributes are writable: you can writemodname.the_answer=42. Writable attributes may also be deleted with thedel statement. For example,delmodname.the_answer will remove the attributethe_answer from the object named bymodname.
Namespaces are created at different moments and have different lifetimes. The namespace containing the built-in names is created when the Python interpreter starts up, and is never deleted. Theglobal namespace for a module is created when the module definition is read in; normally, module namespaces also last until the interpreter quits.The statements executed by the top-level invocation of the interpreter, either read from a script file or interactively, are considered part of a module called__main__, so they have their own global namespace. (The built-in names actually also live in a module; this is calledbuiltins.) Thelocal namespace for a function is created when the function is called, and deleted when the function returns or raises an exception that is not handled within the function.
Ascope is a textual region of a Python program where a namespace is directly accessible. “Directly accessible” here means that an unqualified(未经限定的,不合格的) reference to a name attempts to find the name in the namespace. Theglobal statement can be used to indicate that particular variables live in the global scope and should be rebound there; thenonlocal statement indicates that particular variables live in an enclosing scope and should be rebound there.
global关键字用来在函数或其他局部作用域中使用全局变量。但是如果不修改全局变量也可以不使用global关键字。
nonlocal关键字用来在函数或其他作用域中使用外层(非全局)变量。
python引用变量的顺序: 当前作用域局部变量->外层作用域变量->当前模块中的全局变量->python内置变量
At any time during execution, there are at least three nested scopes whose namespaces are directly accessible:
- the innermost scope, which is searched first, contains the local names
- the scopes of any enclosing functions, which are searched starting with the nearest enclosing scope, contains non-local, but also non-global names
- the next-to-last scope contains the current module’s global names
- the outermost scope (searched last) is the namespace containing built-in names
If a name is declared global, then all references and assignments go directly to the middle scope containing the module’s global names. To rebind variables found outside of the innermost scope, thenonlocal statement can be used; if not declared nonlocal, those variable are read-only (an attempt to write to such a variable will simply create anew local variable in the innermost scope, leaving the identically named outer variable unchanged).
Usually, the local scope references the local names of the (textually) current function. Outside functions, the local scope references the same namespace as the global scope: the module’s namespace. Class definitions place yet another namespace in the local scope.
It is important to realize that scopes are determined textually: the global scope of a function defined in a module is that module’s namespace, no matter from where or by what alias the function is called. On the other hand, the actual search for names is done dynamically, at run time — however, the language definition is evolving towards static name resolution, at “compile” time, so don’t rely on dynamic name resolution! (In fact, local variables are already determined statically.)
A special quirk of Python is that – if no global statement is in effect – assignments to names always go into the innermost scope. Assignments do not copy data — they just bind names to objects. The same is true for deletions: the statement delx removes the binding ofx from the namespace referenced by the local scope. In fact, all operations that introduce new names use the local scope: in particular,import statements and function definitions bind the module or function name in the local scope.
The global statement can be used to indicate that particular variables live in the global scope and should be rebound there; thenonlocal statement indicates that particular variables live in an enclosing scope and should be rebound there.
Scopes and Namespaces Example
This is an example demonstrating how to reference the different scopes and namespaces, and howglobal andnonlocal affect variable binding:
def scope_test():
def do_local():
spam = "local spam"
def do_nonlocal():
nonlocal spam
spam = "nonlocal spam"
def do_global():
global spam
spam = "global spam"
spam = "test spam"
do_local()
print("After local assignment:", spam)
do_nonlocal()
print("After nonlocal assignment:", spam)
do_global()
print("After global assignment:", spam)
scope_test()
print("In global scope:", spam)
The output of the example code is:
After local assignment: test spam
After nonlocal assignment: nonlocal spam
After global assignment: nonlocal spam
In global scope: global spam
Note how the local assignment (which is default) didn’t change scope_test‘s binding ofspam. Thenonlocal assignment changedscope_test‘s binding ofspam, and the global assignment changed the module-level binding.
You can also see that there was no previous binding for spam before theglobal assignment.
Class definitions, like function definitions (def statements) must be executed before they have any effect. (You could conceivably(可能的,可想象的) place a class definition in a branch of anif statement, or inside a function.)
When a class defines an __init__() method, class instantiation automatically invokes __init__() for the newly-created class instance.data attributes correspond to “instance variables” in Smalltalk, and to “data members” in C++. Data attributes need not be declared; like local variables, they spring into existence when they are first assigned to.
the special thing about methods is that the object is passed as the first argument of the function. In one example, the callx.f() is exactly equivalent toMyClass.f(x). x is the object of class MyClass. In general, calling a method with a list ofn arguments is equivalent to calling the corresponding function with an argument list that is created by inserting the method’s object before the first argument.
Possible conventions include capitalizing method names, prefixing data attribute names with a small unique string (perhaps just an underscore), or using verbs for methods and nouns for data attributes to avoid accidental name conflicts.
In other words, classes are not usable to implement pure abstract data types. In fact, nothing in Python makes it possible to enforce data hiding — it is all based upon convention.
Note that clients may add data attributes of their own to an instance object without affecting the validity of the methods, as long as name conflicts are avoided.
Any function object that is a class attribute defines a method for instances of that class. It is not necessary that the function definition is textually enclosed in the class definition: assigning a function object to a local variable in the class is also ok. For example:
# Function defined outside the class
def f1(self, x, y):
return min(x, x+y)
class C:
f = f1
def g(self):
return 'hello world'
h = g
Now f, g and h are all attributes of classC that refer to function objects, and consequently they are all methods of instances ofC —h being exactly equivalent tog. Note that this practice usually only serves to confuse the reader of a program.
Methods may call other methods by using method attributes of the self argument:
Each value is an object, and therefore has a class (also called its type). It is stored as object.__class__.
The syntax for a derived class definition looks like this:
class DerivedClassName(BaseClassName):
<statement-1>
.
.
.
<statement-N>
The name BaseClassName must be defined in a scope containing the derived class definition. In place of a base class name, other arbitrary expressions are also allowed. This can be useful, for example, when the base class is defined in another module:
class DerivedClassName(modname.BaseClassName):
Execution of a derived class definition proceeds the same as for a base class. When the class object is constructed, the base class is remembered. This is used for resolving attribute references: if a requested attribute is not found in the class, the search proceeds to look in the base class. This rule is applied recursively if the base class itself is derived from some other class.
An overriding method in a derived class may in fact want to extend rather than simply replace the base class method of the same name. There is a simple way to call the base class method directly: just callBaseClassName.methodname(self,arguments). This is occasionally useful to clients as well. (Note that this only works if the base class is accessible asBaseClassName in the global scope.)
Python has two built-in functions that work with inheritance:
- Use isinstance() to check an instance’s type:isinstance(obj,int) will beTrue only ifobj.__class__ isint or some class derived fromint.
- Use issubclass() to check class inheritance:issubclass(bool,int) isTrue sincebool is a subclass ofint. However,issubclass(float,int) isFalse sincefloat is not a subclass ofint.
Python supports a form of multiple inheritance as well. A class definition with multiple base classes looks like this:
class DerivedClassName(Base1, Base2, Base3):
<statement-1>
.
<statement-N>
the method resolution order changes dynamically to support cooperative calls tosuper(). This approach is known in some other multiple-inheritance languages as call-next-method and is more powerful than the super call found in single-inheritance languages. Dynamic ordering is necessary because all cases of multiple inheritance exhibit one or more diamond relationships (where at least one of the parent classes can be accessed through multiple paths from the bottommost class).
“Private” instance variables that cannot be accessed except from inside an object don’t exist in Python. However, there is a convention that is followed by most Python code: a name prefixed with an underscore (e.g._spam) should be treated as a non-public part of the API (whether it is a function, a method or a data member). It should be considered an implementation detail and subject to change without notice.
Since there is a valid use-case for class-private members (namely to avoid name clashes(冲突,不协调,抵触) of names with names defined by subclasses), there is limited support for such a mechanism, calledname mangling. Any identifier of the form__spam (at least two leading underscores, at most one trailing underscore) is textually replaced with_classname__spam, whereclassname is the current class name with leading underscore(s) stripped. This mangling is done without regard to the syntactic position of the identifier, as long as it occurs within the definition of a class.
Name mangling is helpful for letting subclasses override methods without breaking intraclass method calls. For example:
class Mapping:
def __init__(self, iterable):
self.items_list = []
self.__update(iterable)
def update(self, iterable):
for item in iterable:
self.items_list.append(item)
__update = update # private copy of original update() method
class MappingSubclass(Mapping):
def update(self, keys, values):
# provides new signature for update()
# but does not break __init__()
for item in zip(keys, values):
self.items_list.append(item)
Note that the mangling rules are designed mostly to avoid accidents; it still is possible to access or modify a variable that is considered private.
Sometimes it is useful to have a data type similar to the Pascal “record” or C “struct”, bundling together a few named data items. An empty class definition will do nicely:
class Employee:
pass
john = Employee() # Create an empty employee record
# Fill the fields of the record
john.name = 'John Doe'
john.dept = 'computer lab'
john.salary = 1000
A piece of Python code that expects a particular abstract data type can often be passed a class that emulates(仿真,模仿) the methods of that data type instead. For instance, if you have a function that formats some data from a file object, you can define a class with methods read() andreadline() that get the data from a string buffer instead, and pass it as an argument.
Instance method objects have attributes, too: m.__self__ is the instance object with the methodm(), andm.__func__ is the function object corresponding to the method.
User-defined exceptions are identified by classes as well. Using this mechanism it is possible to create extensible hierarchies of exceptions.
A class in an except clause is compatible with an exception if it is the same class or a base class thereof (but not the other way around — an except clause listing a derived class is not compatible with a base class). For example, the following code will print B, C, D in that order:
class B(Exception):
pass
class C(B):
pass
class D(C):
pass
for cls in [B, C, D]:
try:
raise cls()
except D:
print("D")
except C:
print("C")
except B:
print("B")
Note that if the except clauses were reversed (with except B first), it would have printed B, B, B — the first matching except clause is triggered.
By now you have probably noticed that most container objects can be looped over using afor statement:
for element in [1, 2, 3]:
print(element)
for element in (1, 2, 3):
print(element)
for key in {'one':1, 'two':2}:
print(key)
for char in "123":
print(char)
for line in open("myfile.txt"):
print(line)
This style of access is clear, concise, and convenient.
Behind the scenes, the for statement callsiter() on the container object. The function returns an iterator object that defines the method__next__() which accesses elements in the container one at a time. When there are no more elements,__next__() raises aStopIteration exception which tells thefor loop to terminate. You can call the__next__() method using thenext() built-in function; this example shows how it all works:
>>> s = 'abc'
>>> it = iter(s)
>>> it
" , line 1, in ?
next(it)
StopIteration
Having seen the mechanics behind the iterator protocol, it is easy to add iterator behavior to your classes. Define an__iter__() method which returns an object with a__next__() method. If the class defines__next__(), then__iter__() can just returnself:
class Reverse:
"""Iterator for looping over a sequence backwards."""
def __init__(self, data):
self.data = data
self.index = len(data)
def __iter__(self):
return self
def __next__(self):
if self.index == 0:
raise StopIteration
self.index = self.index - 1
return self.data[self.index]
>>> rev = Reverse('spam')
>>> iter(rev)
<__main__.Reverse object at 0x00A1DB50>
>>> for char in rev:
... print(char)
...
m
a
p
s
Generators are a simple and powerful tool for creating iterators. They are written like regular functions but use theyield statement whenever they want to return data. Each timenext() is called on it, the generator resumes where it left-off (it remembers all the data values and which statement was last executed). An example shows that generators can be trivially(琐碎的,不重要的) easy to create:
def reverse(data):
for index in range(len(data)-1, -1, -1):
yield data[index]
>>> for char in reverse('golf'):
... print(char)
...
f
l
o
g
Anything that can be done with generators can also be done with class based iterators as described in the previous section. What makes generators so compact is that the__iter__() and__next__() methods are created automatically.
Another key feature is that the local variables and execution state are automatically saved between calls. This made the function easier to write and much more clear than an approach using instance variables likeself.index and self.data.
In addition to automatic method creation and saving program state, when generators terminate, they automatically raiseStopIteration. In combination, these features make it easy to create iterators with no more effort than writing a regular function.
python glob model
说明:
1、glob是python自己带的一个文件操作相关模块,用它可以查找符合自己目的的文件,就类似于Windows下的文件搜索,支持通配符操作,*,?,[]这三个通配符,*代表0个或多个字符,?代表一个字符,[]匹配指定范围内的字符,如[0-9]匹配数字。
它的主要方法就是glob,该方法返回所有匹配的文件路径列表,该方法需要一个参数用来指定匹配的路径字符串(本字符串可以为绝对路径也可以为相对路径),其返回的文件名只包括当前目录里的文件名,不包括子文件夹里的文件。
比如:
glob.glob(r'c:\*.txt')
我这里就是获得C盘下的所有txt文件
glob.glob(r'E:\pic\*\*.jpg')
获得指定目录下的所有jpg文件
使用相对路径:
glob.glob(r'../*.py')
2、iglob方法:
获取一个可编历对象,使用它可以逐个获取匹配的文件路径名。与glob.glob()的区别是:glob.glob同时获取所有的匹配路径,而 glob.iglob一次只获取一个匹配路径。这有点类似于.NET中操作数据库用到的DataSet与DataReader。下面是一个简单的例子:
#父目录中的.py文件
f = glob.iglob(r'../*.py')
print f #
for py in f:
print py
- 官方说明:
- glob. glob ( pathname )
- Return a possibly-empty list of path names that match pathname, which must be a string containing a path specification. pathname can be either absolute (like /usr/src/Python-1.5/Makefile) or relative (like http://www.cnblogs.com/Tools/*/*.gif), and can contain shell-style wildcards. Broken symlinks are included in the results (as in the shell).
- glob. iglob ( pathname )
-
Return an iterator which yields the same values as glob() without actually storing them all simultaneously.
New in version 2.5.
For example, consider a directory containing only the following files: 1.gif, 2.txt, andcard.gif. glob() will produce the following results. Notice how any leading components of the path are preserved.
Gnuplot是一个命令行的交互式绘图工具(command-driven interactive function plotting program)。用户通过输入命令,可以逐步设置或修改绘图环境,并以图形描述数据或函数,使我们可以借由图形做更进一步的分析。
grep "^[1-9]" $1 |awk '{print $1}' >1.log
echo "set terminal jpeg large;set key top left; plot '1.log' w l" | gnuplot > a.jpg
Python实现stack
#!/usr/bin/env python
class stack:
def __init__(self,size=20):
self.stack = []
self.size = size
self.top = -1
def setsize(self,size):
self.size = size
def push(self,data):
if self.isFull():
raise "stack already full"
else:
self.stack.append(data)
self.top = self.top+1
def pop(self):
if self.isEmpty():
raise "stack is empty"
else:
data = self.stack[-1];
self.top = self.top-1
del self.stack[-1]
return data
def Top(self):
return self.top
def isEmpty(self):
if self.top == -1:
return True
else:
return False
def empty(self):
self.stack = []
self.top = -1
def isFull(self):
if self.top == self.size-1:
return True
else:
return False
if __name__ == '__main__':
st = stack()
for i in xrange(16):
st.push(i)
print st.Top()
print
for i in xrange(16):
print st.pop()
st.empty()
st.setsize(101)
for i in xrange(100):
st.push(i)
for i in xrange(100):
print st.pop(),
引用 http://blog.csdn.net/lokibalder/article/details/3459722
file_handler = open(filename,,mode)
Table mode
| 模式 |
描述 |
| r |
以读方式打开文件,可读取文件信息。 |
| w |
以写方式打开文件,可向文件写入信息。如文件存在,则清空该文件,再写入新内容 |
| a |
以追加模式打开文件(即一打开文件,文件指针自动移到文件末尾),如果文件不存在则创建 |
| r+ |
以读写方式打开文件,可对文件进行读和写操作。 |
| w+ |
消除文件内容,然后以读写方式打开文件。 |
| a+ |
以读写方式打开文件,并把文件指针移到文件尾。 |
| b |
以二进制模式打开文件,而不是以文本模式。该模式只对Windows或Dos有效,类Unix的文件是用二进制模式进行操作的。 |
Table 文件对象方法
| 方法 |
描述 |
| f.close() |
关闭文件,记住用open()打开文件后一定要记得关闭它,否则会占用系统的可打开文件句柄数。 |
| f.fileno() |
获得文件描述符,是一个数字 |
| f.flush() |
刷新输出缓存 |
| f.isatty() |
如果文件是一个交互终端,则返回True,否则返回False。 |
| f.read([count]) |
读出文件,如果有count,则读出count个字节。 |
| f.readline() |
读出一行信息。 |
| f.readlines() |
读出所有行,也就是读出整个文件的信息。 |
| f.seek(offset[,where]) |
把文件指针移动到相对于where的offset位置。where为0表示文件开始处,这是默认值 ;1表示当前位置;2表示文件结尾。 |
| f.tell() |
获得文件指针位置。 |
| f.truncate([size]) |
截取文件,使文件的大小为size。 |
| f.write(string) |
把string字符串写入文件。 |
| f.writelines(list) |
把list中的字符串一行一行地写入文件,是连续写入文件,没有换行。 |
例子如下: