笔记3:pytorch.nn.Conv2d如何计算输出特征图尺寸?如何实现Tensorflow中的“same”和“valid”功能
1 pytorch.nn.Conv2d实现机制
1.1 Conv2d简介

参数说明:
- stride(步长):控制cross-correlation的步长,可以设为1个int型数或者一个(int, int)型的tuple。
- padding(补0):控制zero-padding的数目。
- dilation(扩张):控制kernel点(卷积核点)的间距; 也被称为 "à trous"算法. 可以在此github地址查看:Dilated convolution animations
- groups(卷积核个数):这个比较好理解,通常来说,卷积个数唯一,但是对某些情况,可以设置范围在1~ in_channels中数目的卷积核:
{At groups=1, all inputs are convolved to all outputs;
At groups=2, the operation becomes equivalent to having two conv layers side by side, each seeing half the input channels, and producing half the output channels, and both subsequently concatenated;
At groups=in_channels, each input channel is convolved with its own set of filters (of size ⌊out_channelsin_channels⌋). -
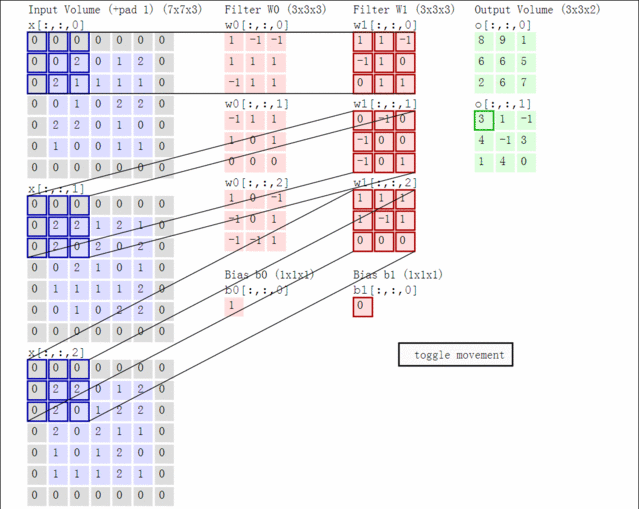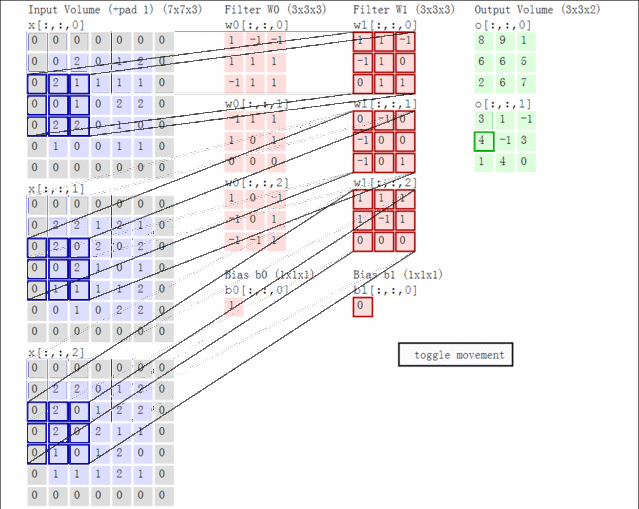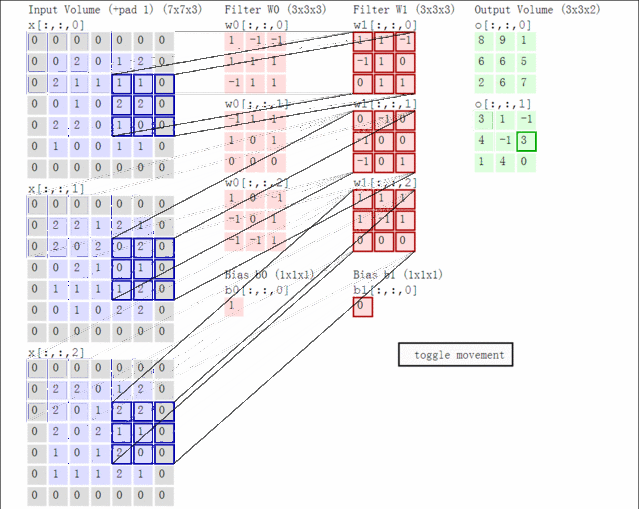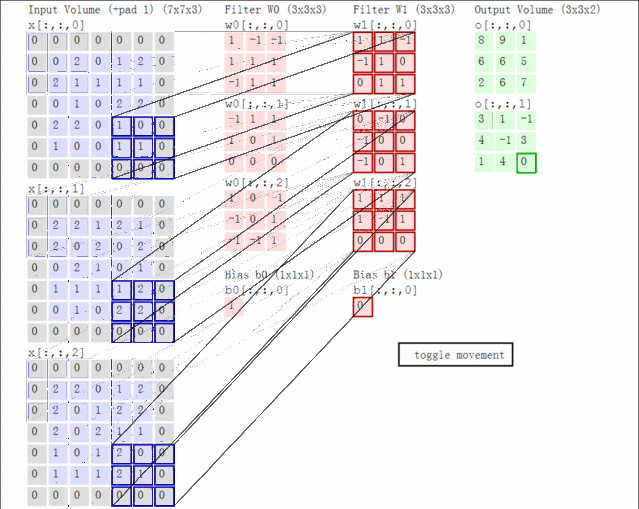
先了解一个常识:假如卷积核为2*2大小,在4个通道卷积得到2个通道的过程中,参数的数目为2×(2×2)×4 [注:outx(kwxkw)xinput], 即(2,2,2,4),有这个概念后,接下来:
默认情况下groups=1,表示常规的卷积,例如:input(7, 7, 6)→【Conv, Cout=12, ks=3, groups=1】→output(5, 5, 12),weight为(12, 3, 3, 6),表示需要用到12*6(即out * int)个卷积核;
若指定groups=3,input(7, 7, 6)→【Conv, Cout=12, ks=3, groups=3】→output(5, 5, 12),output的size不变,但是weight变为(12, 3, 3, 2),表示只需要用到12*2个卷积核显然计算的方式发生了改变。(因为将输入通道6分成了3组=每组2个通道,同理将输出通道12分成3组=每组4个通道,输入输出每个组进行关联,需要用到4*2+4*2+4*2=12*2(即out * int/gropus)个卷积核)
groups=3表示input, output的通道数都被分成了3组,具体来说:
input (7, 7, 6)被分为3组,每组包含6/3=2个通道,size为(7, 7, 2)
即input[:, :, 0:2], input[:, :, 2:4], input[:, :, 4:6]
12个filter被分为3组,每组包含12/3=4个filter,size为(4, 3, 3, 2)(注意最后一维是2,与每一组input的通道数相等)
即weight[0:4], weight[4:8], weight[8:12]
每组的input和filter分别进行卷积运算,得到3组output,每组output的size为(5, 5, 4)
将它们在通道维度上拼接起来,最终output的size为(5, 5, 12)}
注意:kernel_size, stride, padding, dilation 不但可以是一个单个的int——表示在高度和宽度使用这个相同的int作为参数,也可以使用一个(int1, int2)的元组(本质上单个的int就是相同int的(int, int))。在元组中,第1个参数对应高度维度,第2个参数对应宽度维度。
还有一点需要提醒的是:卷积核的size的选择可能导致input中某几行(最后几行)没有使用,这是因为我们默认使用的模式是valid,而不是full(在tensorflow中也称为same)。如果想要充分利用input的话,则依赖于用户对padding以及stride等参数的设置。相比tensorflow,PyTorch需要用户清楚的知道的自己的卷积核选取对结果的影响。


2.2 卷积dilation作用 (空洞卷积感受野计算)
Pytorch中空洞卷积分为两类,一类是正常图像的卷积,另一类是池化时候。
pytorch卷积API为:
Conv2d(in_channels,out_channels,kernel_size,stride,padding,dilation)(1) 正常图像空洞卷积
感受野尺寸:
size=(dilation-1)*(kernel_size-1) + kernel_size # kernel_size为卷积核大小最后计算图像H*W时,kernel_size按照size计算。
pytorch池化API为:
nn.MaxPool2d(kernel_size,.....,dilation)
nn.AvgPool2d(kernel_size, .....,dilation) (2)padding的空洞卷积
若空洞卷积率为 dilation
则感受野尺寸:
size=2 *(dilation-1)*(kernel_size-1)+kernel_size #kernel_size为卷积核大小1.3 nn.Conv2d中的padding操作
nn.Conv2d简单介绍完了,现在来讲讲padding在nn.Conv2d中怎么实现的,也就是怎么补的0,或者说补0的策略。
Q1: padding是卷积之后还是卷积之前还是卷积之后实现的?
padding是在卷积之前补0,如果愿意的话,可以通过使用torch.nn.Functional.pad来补非0的内容。
Q2:padding补0的默认策略是什么?
四周都补!如果pad输入是一个tuple的话,则第一个参数表示高度上面的padding,第2个参数表示宽度上面的
下面将展示一个padding = 1的例子:

显然,padding=1的效果是:原来的输入层基础上,上下左右各补了一行!除此之外我们看到,上下左右都是0.9862,那么,这个东西是啥呢?为什么不是0呢?
为了这个问题,我甚至还去PyTorch论坛上献丑了,估计大家可能也知道是咋回事了…
是的!是Bias!我问的问题是这样的:
Hello, I just can’t figure out the way nn.Conv2d calculate the output .
The result calculated from torch is not the same as some machine learning course had taught.
For example, likes the code below:
>> m = torch.nn.Conv2d(1, 1, 3, padding=0)
>> m(input)
tensor([[[[ 0.5142, 0.3803, 0.2687],
[-0.4321, 1.1637, 1.0675],
[ 0.1742, 0.0869, -0.4451]]]], grad_fn=)
>> input
tensor([[[[ 0.7504, 0.1157, 1.4940, -0.2619, -0.4732],
[ 0.1497, 0.0805, 2.0829, -0.0925, -1.3367],
[ 1.7471, 0.5205, -0.8532, -0.7358, -1.3931],
[ 0.1159, -0.2376, 1.2683, -0.0959, -1.3171],
[-0.1620, -1.8539, 0.0893, -0.0568, -0.0758]]]])
>> m.weight
Parameter containing:
tensor([[[[ 0.2405, 0.3018, 0.0011],
[-0.1691, -0.0701, -0.0334],
[-0.0429, 0.2668, -0.2152]]]], requires_grad=True)
for the left top element 0.5142, it’s not the output equals to
>> import numpy as np
>> w = np.array([[0.2405, 0.3018, 0.0011],
>> [-0.1691, -0.0701, -0.0334],
>> [-0.0429, 0.2668, -0.2152]])
# top-left 3x3 matrix of 5x5
>> x = np.array([[ 0.7504, 0.1157, 1.4940],
>> [ 0.1497, 0.0805, 2.0829],
>> [1.7471, 0.5205, -0.8532]])
>> print(np.sum(w*x))
# 0.364034 != 0.5142
0.36403412999999996
My Question here is: Why Could the output not equal to 0.5142?
Further more, when i add paramter padding into nn.Conv2d,
The outcome seems obscure to me as below, thanks a lot for explain that to me.Thank you!
>> input
tensor([[[[ 0.7504, 0.1157, 1.4940, -0.2619, -0.4732],
[ 0.1497, 0.0805, 2.0829, -0.0925, -1.3367],
[ 1.7471, 0.5205, -0.8532, -0.7358, -1.3931],
[ 0.1159, -0.2376, 1.2683, -0.0959, -1.3171],
[-0.1620, -1.8539, 0.0893, -0.0568, -0.0758]]]])
# set padding from 0 to 1 equals to (1, 1)
>> m1 = torch.nn.Conv2d(1, 1, 1, padding=1)
>> m1(input)
tensor([[[[0.9862, 0.9862, 0.9862, 0.9862, 0.9862, 0.9862, 0.9862],
[0.9862, 1.0771, 1.0002, 1.1672, 0.9544, 0.9288, 0.9862],
[0.9862, 1.0043, 0.9959, 1.2385, 0.9749, 0.8242, 0.9862],
[0.9862, 1.1978, 1.0492, 0.8828, 0.8970, 0.8174, 0.9862],
[0.9862, 1.0002, 0.9574, 1.1398, 0.9745, 0.8266, 0.9862],
[0.9862, 0.9665, 0.7615, 0.9970, 0.9793, 0.9770, 0.9862],
[0.9862, 0.9862, 0.9862, 0.9862, 0.9862, 0.9862, 0.9862]]]],
grad_fn=)
The confused point is that how 0.9862 be calculated?
And what is the default padding strategy in nn.Conv2d?
Thank you for reading and answer!
答案也很简单——我没考虑bias!

根据下图,Q2中神秘的0.9862的来历我们就很清楚了,是bias的值。

2 torch实现Tensorflow中的“same”和“valid”功能
2.0 引言
同样的问题见“How to keep the shape of input and output same when dilation conv?”,已经有相关回答,问题具体概述为:
问题:
假设输入图片尺寸为32*32*3,,在kerasz中使用以下命令:
model.add(Conv2D(256, kernel_size=3, strides=1,padding=‘same’, dilation_rate=(2, 2)))可以使得输入输出尺寸保持一致,都是32*32,都是因为padding='same',但是在 pytorch中,使用:
torch.nn.Conv2d(3,256,3,1,1, dilation=2,bias=False)输出尺寸变成30,所以如何可以控制输出尺寸的呢?
答案:
合理使用padding,上例中:
o = output=32i = input =32p = padding=? #未知量,需求k = kernel_size=3s = stride=1d = dilation=2
根据公式:

代入已知量得到方程式:
32=(32+2xpadding-2x(3-1)-1)/1+1
解方程得到:
padding=2
所以要保持输出尺寸等于输入尺寸,需要执行命令如下:
torch.nn.Conv2d(in_channels=3, out_channels=256,kernel_size=3,stride=1,padding=2, dilation=2,bias=True)其中padding为2而不是原来的1。
striide=1时保持输出卷积输出大小等于输入大小的小诀窍: padding=(kernel_size-1)/2 )
TensorFlow中在使用卷积层函数的时候有一个参数padding可以选择same或者vaild,具体可以看之前的这篇文章:https://oldpan.me/archives/tf-keras-padding-vaild-same.而在pytorch中,现在的版本中还是没有这个功能的,现在我们要在pytorch中实现与TensorFlow相同功能的padding=’same’的操作。
2.1 pytorch中padding-Vaild
首先需要说明一点,在pytorch中,如果你不指定padding的大小,在pytorch中默认的padding方式就是vaild。

我们用一段程序来演示一下pytorch中的vaild操作:
根据上图中的描述,我们首先定义一个长度为13的一维向量,然后用核大小为6,步长为5的一维卷积核对其进行卷积操作,由上图很容易看出输出为长度为2的数据(因为只进行了两次卷积操作,12和13被弃用了)。
>>> input = torch.FloatTensor([[[1,2,3,4,5,6,7,8,9,10,11,12,13]]])
>>> input
(0 ,.,.) =
1 2 3 4 5 6 7 8 9 10 11 12 13
[torch.FloatTensor of size 1x1x13] # 输入长度为13
conv = torch.nn.Conv1d(1,1,6,5) # 定义一维卷积核
>>> input.size()
>>> torch.Size([1, 1, 13])
>>> input = torch.autograd.Variable(input)
>>> input
Variable containing:
(0 ,.,.) =
1 2 3 4 5 6 7 8 9 10 11 12 13
[torch.FloatTensor of size 1x1x13]
>>> output = conv(input)
>>> output.size()
>>> torch.Size([1, 1, 2]) # 输出长度为2
由程序结果可以看到pytorch中的默认padding模式是vaild。
2.2 pytorch中padding-same
这里我们借用TensorFlow中的核心函数来模仿实现padding=same的效果。
def conv2d_same_padding(input, weight, bias=None, stride=1, padding=1, dilation=1, groups=1):
# 函数中padding参数可以无视,实际实现的是padding=same的效果
input_rows = input.size(2)
filter_rows = weight.size(2)
effective_filter_size_rows = (filter_rows - 1) * dilation[0] + 1
out_rows = (input_rows + stride[0] - 1) // stride[0]
padding_rows = max(0, (out_rows - 1) * stride[0] +
(filter_rows - 1) * dilation[0] + 1 - input_rows)
rows_odd = (padding_rows % 2 != 0)
padding_cols = max(0, (out_rows - 1) * stride[0] +
(filter_rows - 1) * dilation[0] + 1 - input_rows)
cols_odd = (padding_rows % 2 != 0)
if rows_odd or cols_odd:
input = pad(input, [0, int(cols_odd), 0, int(rows_odd)])
return F.conv2d(input, weight, bias, stride,
padding=(padding_rows // 2, padding_cols // 2),
dilation=dilation, groups=groups)自定义这个函数后我们移植pytorch中的Conv2d函数,在其forward中将默认的conv2d函数改为我们的padding-same函数:
import torch.utils.data
from torch.nn import functional as F
import math
import torch
from torch.nn.parameter import Parameter
from torch.nn.functional import pad
from torch.nn.modules import Module
from torch.nn.modules.utils import _single, _pair, _triple
class _ConvNd(Module):
def __init__(self, in_channels, out_channels, kernel_size, stride,
padding, dilation, transposed, output_padding, groups, bias):
super(_ConvNd, self).__init__()
if in_channels % groups != 0:
raise ValueError('in_channels must be divisible by groups')
if out_channels % groups != 0:
raise ValueError('out_channels must be divisible by groups')
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
self.dilation = dilation
self.transposed = transposed
self.output_padding = output_padding
self.groups = groups
if transposed:
self.weight = Parameter(torch.Tensor(
in_channels, out_channels // groups, *kernel_size))
else:
self.weight = Parameter(torch.Tensor(
out_channels, in_channels // groups, *kernel_size))
if bias:
self.bias = Parameter(torch.Tensor(out_channels))
else:
self.register_parameter('bias', None)
self.reset_parameters()
def reset_parameters(self):
n = self.in_channels
for k in self.kernel_size:
n *= k
stdv = 1. / math.sqrt(n)
self.weight.data.uniform_(-stdv, stdv)
if self.bias is not None:
self.bias.data.uniform_(-stdv, stdv)
def __repr__(self):
s = ('{name}({in_channels}, {out_channels}, kernel_size={kernel_size}'
', stride={stride}')
if self.padding != (0,) * len(self.padding):
s += ', padding={padding}'
if self.dilation != (1,) * len(self.dilation):
s += ', dilation={dilation}'
if self.output_padding != (0,) * len(self.output_padding):
s += ', output_padding={output_padding}'
if self.groups != 1:
s += ', groups={groups}'
if self.bias is None:
s += ', bias=False'
s += ')'
return s.format(name=self.__class__.__name__, **self.__dict__)
class Conv2d(_ConvNd):
def __init__(self, in_channels, out_channels, kernel_size, stride=1,
padding=0, dilation=1, groups=1, bias=True):
kernel_size = _pair(kernel_size)
stride = _pair(stride)
padding = _pair(padding)
dilation = _pair(dilation)
super(Conv2d, self).__init__(
in_channels, out_channels, kernel_size, stride, padding, dilation,
False, _pair(0), groups, bias)
# 修改这里的实现函数
def forward(self, input):
return conv2d_same_padding(input, self.weight, self.bias, self.stride,
self.padding, self.dilation, self.groups)然后在实际使用中,调用我们移植过来修改完的函数即可。
亲测可以实现,具体可以到我这个项目源码中查看:https://github.com/Oldpan/faceswap-pytorch
参考资料:
https://github.com/pytorch/pytorch/issues/3867
https://github.com/tensorflow/tensorflow/blob/3c3c0481ec087aca4fa875d6d936f19b31191fc1/tensorflow/core/framework/common_shape_fns.cc#L40-L48
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/core/kernels/conv_ops.cc#L568-L605