JetPack之WorkManager源码详细分析
目录
简单用例:
源码分析:
worker分析
WorkRequest源码分析
WorkManager.getInstance(),初始化WorkManagerImpl过程
enqueue的执行过程
简介:WorkManager是可以执行异步任务的库,使用它执行异步任务,当应用已经退出或者设备重启时都可以继续执行。
我们使用 WorkManager的原因有:
它可以循环执行任务或者执行一次性任务
它可以与livedata进行联用
可以指定任务运行的约束,在指定情况下执行任务
内部监听了系统广播,可根据设备的不同状态,进行执行,而这个过程不需要包含它的应用运行
角色:
work:执行异步任务,需要子类去继承Worker抽象类并实现它的doWork方法,在doWork中完成真正的异步任务的执行。
WorkRequest:对任务添加约束,它是一个抽象类,实现它的子类有2个,一个是OneTimeWorkRequest,用来执行一次性任务。另外一个是PeriodicWorkRequest,用来执行重复任务。
WorkManager:任务队列,对异步任务进行调度。
简单用例:
使用之前首先需要在我们的gradle文件中进行引入。此处使用的是1.0.1版本,所以解析的源码与使用方式会与之前有所不同
implementation "android.arch.work:work-runtime:1.0.1"
然后创建一个测试类,需要继承自Worker抽象类,并在其内部重写dowork方法
public class TestWork extends Worker {
public TestWork(@NonNull Context context, @NonNull WorkerParameters workerParams) {
super(context, workerParams);
}
@NonNull
@Override
public Result doWork() {
//将需要执行的异步任务放入此处
return Result.success();
}
}
在activity中使用 WorkRequest添加约束后最后放入到WorkMananger中的任务队列完成异步任务的执行
public class MainActivity extends AppCompatActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
//将我们的TestWork使用WorkRequest的子类添加约束
// OneTimeWorkRequest.from(TestWork.class); 默认配置的WorkRequest
WorkRequest testRequest= new OneTimeWorkRequest.Builder(TestWork.class) //手动设置配置
.setInitialDelay()
.setInputMerger()
.addTag()
.keepResultsForAtLeast()
.setBackoffCriteria()
.setConstraints()
.setInitialRunAttemptCount()
.setInitialState()
.setInputData()
.setPeriodStartTime()
.setScheduleRequestedAt()
.build();
//使用WorkManager将WorkRequest放入队列中去
WorkManager.getInstance().enqueue(testRequest);
};
}
源码分析:
worker分析
Worker是异步任务执行者,使用时我们需要继承自Worker,并重新它的doWork方法。
public class TestWork extends Worker {
public TestWork(@NonNull Context context, @NonNull WorkerParameters workerParams) {
super(context, workerParams);
}
@NonNull
@Override
public Result doWork() {
//将需要执行的异步任务放入此处
return Result.success();
}
}
进入Worker抽象类可以发现它继承自ListenableWorker,而它本身的方法和属性只有这几种

它的构造方法需要传入2个参数,一个是我们的上下文对象,建议使用application的context,另外一个是workerParams, workerParams的主要作用是设置Worker的一些参数,如果我们与WorkRequest一起使用则暂时不必关心此参数
@Keep
@SuppressLint("BanKeepAnnotation")
public Worker(@NonNull Context context, @NonNull WorkerParameters workerParams) {
super(context, workerParams);
}
startWork则是可以直接执行work异步任务,而不必与WorkRequest,以及WorkManager搭配使用,使用这种方式进行异步调用时,需要手动构建WorkerParameters 实例
WorkerParameters parameters=new WorkerParameters();//使用伪代码,在真实场景中如果需要这样实
// 例化WorkerParameters对象,则需要指定构造方法中的各项参数
Worker worker =new TestWork(this, parameters);
worker.startWork();其内部会先创建一个future对象,该对象用来传递结果,然后调用线程池去异步执行doWork方法,并最终将结果赋值给Future并返回。
@Override public final @NonNull ListenableFuturestartWork() { mFuture = SettableFuture.create(); //此处调用线程池去异步执行doWork方法 getBackgroundExecutor().execute(new Runnable() { @Override public void run() { try { //执行doWork方法并将结果赋值给mFuture Result result = doWork(); mFuture.set(result); } catch (Throwable throwable) { mFuture.setException(throwable); } } }); return mFuture; }
这里的线程池对象是调用的Worker的父类ListenableWorker中的方法
@RestrictTo(RestrictTo.Scope.LIBRARY_GROUP)
public @NonNull Executor getBackgroundExecutor() {
return mWorkerParams.getBackgroundExecutor();
}而这里返回的其实就是构造WorkerParameters时传入的线程池对象
@RestrictTo(RestrictTo.Scope.LIBRARY_GROUP)
public WorkerParameters(
@NonNull UUID id,
@NonNull Data inputData,
@NonNull Collection tags,
@NonNull RuntimeExtras runtimeExtras,
int runAttemptCount,
@NonNull Executor backgroundExecutor,
@NonNull TaskExecutor workTaskExecutor,
@NonNull WorkerFactory workerFactory) {
mId = id;
mInputData = inputData;
mTags = new HashSet<>(tags);
mRuntimeExtras = runtimeExtras;
mRunAttemptCount = runAttemptCount;
mBackgroundExecutor = backgroundExecutor;
mWorkTaskExecutor = workTaskExecutor;
mWorkerFactory = workerFactory;
} ListenableWorker的主要作用是将我们在构造Worker时的参数进行保存,并向外界提供,它还提供了一个onStopped方法,可以用来在异步任务停止是做一些相关操作。

Worker到此分析完毕,接下来查看WorkRequest做了哪些操作,由于WorkRequest是一个抽象类,我们先看其其中的一个实现类OneTimeWorkRequest,它用来为一次性的异步任务设置配置。
WorkRequest源码分析
OneTimeWorkRequest.from(TestWork.class)查看该方法接受2种参数
第一种是直接传递一个继承于ListenableWorker的Worker的实现类
public static @NonNull OneTimeWorkRequest from(
@NonNull Class workerClass) {
return new OneTimeWorkRequest.Builder(workerClass).build();
}
第二种是传递一个Worker的list集合
public static @NonNull List from(
@NonNull List> workerClasses) {
List workList = new ArrayList<>(workerClasses.size());
for (Class workerClass : workerClasses) {
workList.add(new OneTimeWorkRequest.Builder(workerClass).build());
}
return workList;
} 2种方法做的最重要的操作是
new OneTimeWorkRequest.Builder(workerClass).build(),这里使用了简单建造者模式完成构建
在Builder方法内,会将传递进来的Worker传递到父类中去然后调用
public Builder(@NonNull Class workerClass) {
super(workerClass);
//对inputMergerClassName 进行赋值
mWorkSpec.inputMergerClassName = OverwritingInputMerger.class.getName();
}查看父类的该方法,在这里会生成一个随机的id,然后使用该id,与worker的类名构造一个WorkSpec实例,最后将该worker的类名
添加到Tag集合中去保存起来,该WorkSpec其实就是起到了对配置进行保管的作用
Builder(@NonNull Class workerClass) {
mId = UUID.randomUUID(); //随机生成id并保存
mWorkSpec = new WorkSpec(mId.toString(), workerClass.getName()); //构造WorkSpec并保存
addTag(workerClass.getName()); //将传递进来的worker的类名作为Tag并保存到set集合中去
}
查看该WorkSpec,,它有2个构造方法,此时我们调用的就是它的第一个构造方法需要传入id和worker的类名,如果我们不指定其他配置参数,则WorkSpec会默认为我们进行配置,
public WorkSpec(@NonNull String id, @NonNull String workerClassName) {
this.id = id;
this.workerClassName = workerClassName;
}
public WorkSpec(@NonNull WorkSpec other) {
id = other.id;
workerClassName = other.workerClassName;
state = other.state;
inputMergerClassName = other.inputMergerClassName;
input = new Data(other.input);
output = new Data(other.output);
initialDelay = other.initialDelay;
intervalDuration = other.intervalDuration;
flexDuration = other.flexDuration;
constraints = new Constraints(other.constraints);
runAttemptCount = other.runAttemptCount;
backoffPolicy = other.backoffPolicy;
backoffDelayDuration = other.backoffDelayDuration;
periodStartTime = other.periodStartTime;
minimumRetentionDuration = other.minimumRetentionDuration;
scheduleRequestedAt = other.scheduleRequestedAt;
}
继续跟踪OneTimeWorkRequest的from方法,当我们的Builder方法执行完毕之后,最后会调用build
![]()
该方法子类中没有去实现,我们查看其父类WorkRequest的实现方法,主要做了这几件事,生成新的id重新赋值并保存,将上一步中实现的workspec重新传入到WorkSpec中构造一个新的WorkSpec实例并保存,之所以这么做,是当我们构建好builder对象后,可能会对WorkSpec手动添加配置,所以在此处重新构建并保存的主要原因就是为了新添加的配置能够生效,最后会返回WorkRequest实例,到此处构造默认的WorkRequest完成。
public final @NonNull W build() {
W returnValue = buildInternal(); //该方法是个抽象方法由子类去完成,它会返回一个WorkRequest实例
// Create a new id and WorkSpec so this WorkRequest.Builder can be used multiple times.
mId = UUID.randomUUID(); //生成随机的id
mWorkSpec = new WorkSpec(mWorkSpec); //将经过一系列配置的WorkSpec重新保存
mWorkSpec.id = mId.toString(); //重新对id进行赋值并保存
return returnValue; //返回WorkRequest实例
} 该方法首先会调用buildInternal,而buildInternal由子类去实现它会返回一个OneTimeWorkRequest
实例,该实例的参数为buidler,在上一步的操作中我们对buidler进行了实现
@Override
@NonNull OneTimeWorkRequest buildInternal() {
if (mBackoffCriteriaSet
&& Build.VERSION.SDK_INT >= 23
&& mWorkSpec.constraints.requiresDeviceIdle()) {
throw new IllegalArgumentException(
"Cannot set backoff criteria on an idle mode job");
}
return new OneTimeWorkRequest(this);
}
OneTimeWorkRequest(Builder builder) {
super(builder.mId, builder.mWorkSpec, builder.mTags);
}
最终会将我们保存在builder 中的参数传递到WorkRequest进行保管。
@RestrictTo(RestrictTo.Scope.LIBRARY_GROUP)
protected WorkRequest(@NonNull UUID id, @NonNull WorkSpec workSpec, @NonNull Set tags) {
mId = id;
mWorkSpec = workSpec;
mTags = tags;
}
接下来分析手动配置
WorkRequest testRequest= new OneTimeWorkRequest.Builder(TestWork.class) //手动设置配置
.setInitialDelay() //设置任务被调用时初始延迟
.setInputMerger() //设置合并输入规则
.addTag() //添加worker对应的TAG
.keepResultsForAtLeast() //设置任务的保存时长
.setBackoffCriteria() //设置任务的重试策略
.setConstraints() //添加拦截器
.setInitialRunAttemptCount() //设置任务尝试执行的最大次数
.setInputData() //设置入参
.build();手动配置我们不去调用from方法,而是自己实例化Builder,和默认方式实现WorkRequest不同,默认方式实现这一步由OneTimeWorkRequest去完成。调用Builder方法实例化Builder之后,就可以调用它的一系列方法完成对work的配置,查看源码可以看出,当我们调用这一系列方法时,内部是通过mWorkSpec将手动配置好的参数先进行了保存,
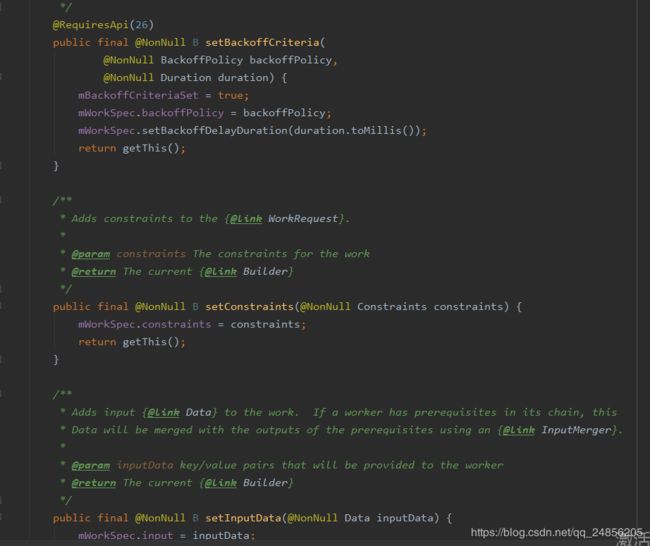
手动配置的区别主要就是在此处,其他方式原理与默认配置相同.
查看最后一步操作
WorkManager.getInstance(),初始化WorkManagerImpl过程
WorkManager.getInstance().enqueue(testRequest);使用单例的方式返回了一个WorkManagerImpl实例,该WorkManagerImpl继承自WorkManager,是它的实现类
public static @NonNull WorkManager getInstance() {
WorkManager workManager = WorkManagerImpl.getInstance();
if (workManager == null) {
throw new IllegalStateException("WorkManager is not initialized properly. The most "
+ "likely cause is that you disabled WorkManagerInitializer in your manifest "
+ "but forgot to call WorkManager#initialize in your Application#onCreate or a "
+ "ContentProvider.");
} else {
return workManager;
}
}查看WorkManagerImpl的getInstance方法,会根据sDelegatedInstance 是否为空而选择返回sDelegatedInstance还是sDefaultInstance。
@RestrictTo(RestrictTo.Scope.LIBRARY_GROUP)
public static @Nullable WorkManagerImpl getInstance() {
synchronized (sLock) {
if (sDelegatedInstance != null) {
return sDelegatedInstance;
}
return sDefaultInstance;
}
}而这2个参数都为WorkManagerImpl类型,并在WorkManagerImpl内部的initialize中对其进行赋值操作
@RestrictTo(RestrictTo.Scope.LIBRARY_GROUP)
public static void initialize(@NonNull Context context, @NonNull Configuration configuration) {
synchronized (sLock) {
if (sDelegatedInstance != null && sDefaultInstance != null) {
throw new IllegalStateException("WorkManager is already initialized. Did you "
+ "try to initialize it manually without disabling "
+ "WorkManagerInitializer? See "
+ "WorkManager#initialize(Context, Configuration) or the class level"
+ "Javadoc for more information.");
}
if (sDelegatedInstance == null) {
context = context.getApplicationContext();
if (sDefaultInstance == null) {
sDefaultInstance = new WorkManagerImpl(
context,
configuration,
new WorkManagerTaskExecutor());
}
sDelegatedInstance = sDefaultInstance;
}
}
}
该方法会在它的父类WorkManager的initialize方法中进行调用
public static void initialize(@NonNull Context context, @NonNull Configuration configuration) {
WorkManagerImpl.initialize(context, configuration);
}而其父类的WorkManager的initialize方法则会在WorkManagerInitializer 的oncreate方法中调用,WorkManagerInitializer是一个系统提供的ContentProvider ,它由系统自动构建,当应用运行时,WorkManagerInitializer就会完成自身的构建,并调用它的oncreate方法完成WorkManagerImpl的初始化操作,所以到此也就清楚了,WorkManager.getInstance()返回的WorkManagerImpl的单例实例(这点比较重要,在后面调用startworker时会用到),而该实例会在应用开启后进行实例化。
@RestrictTo(RestrictTo.Scope.LIBRARY_GROUP)
public class WorkManagerInitializer extends ContentProvider {
@Override
public boolean onCreate() {
// Initialize WorkManager with the default configuration.
WorkManager.initialize(getContext(), new Configuration.Builder().build());
return true;
}
在我们调用initialize方法时,第一个参数传入的是上下文对象,而第二个参数是一个Configuration类型的参数,通过new Configuration.Builder().build()会创建一个该对象并传入到WorkManagerImpl中去,
查看该Configuration.Builder().build()做了什么
public static final class Builder {
Executor mExecutor; //配置执行worker的线程池
WorkerFactory mWorkerFactory; //设置用于创建ListenableWorker的工厂对象
int mLoggingLevel = Log.INFO; //指定log等级
int mMinJobSchedulerId = IdGenerator.INITIAL_ID; //设置最小调度器的ID
int mMaxJobSchedulerId = Integer.MAX_VALUE; //设置最大调度器的ID ,这2个参数的范围必须大于1000,否则会报错,设置这2个参数的目的是为了防止与其他应用程序的代码发生冲突
int mMaxSchedulerLimit = MIN_SCHEDULER_LIMIT; //指定WorkManager使obScheduler时发出的最大系统请求数
/**
* Specifies a custom {@link WorkerFactory} for WorkManager.
*
* @param workerFactory A {@link WorkerFactory} for creating {@link ListenableWorker}s
* @return This {@link Builder} instance
*/
public @NonNull Builder setWorkerFactory(@NonNull WorkerFactory workerFactory) {
mWorkerFactory = workerFactory;
return this;
}
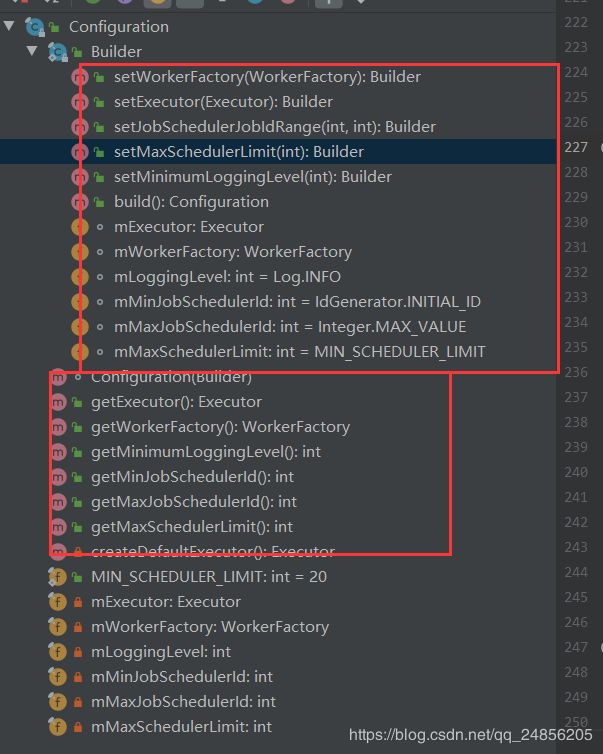
可以发现,他其实为我们的WorkManager做了一些默认的配置,切这些配置也可以由我们自己去指定,它提供了get和set方法,可以手动去进行配置,以及在后期的调度worker时获取这些配置来完成一系列操作。
继续查看WorkManagerImpl的initialize初始化方法,它会将我们传递进来的context与Configuration 实例进行保存,并且在实例化WorkManagerImpl时会构造一个线程池传入。继续追踪new WorkManagerImpl()时发生了什么。
@RestrictTo(RestrictTo.Scope.LIBRARY_GROUP)
public static void initialize(@NonNull Context context, @NonNull Configuration configuration) {
synchronized (sLock) {
if (sDelegatedInstance != null && sDefaultInstance != null) {
throw new IllegalStateException("WorkManager is already initialized. Did you "
+ "try to initialize it manually without disabling "
+ "WorkManagerInitializer? See "
+ "WorkManager#initialize(Context, Configuration) or the class level"
+ "Javadoc for more information.");
}
if (sDelegatedInstance == null) {
context = context.getApplicationContext();
if (sDefaultInstance == null) {
sDefaultInstance = new WorkManagerImpl(
context,
configuration,
new WorkManagerTaskExecutor());
}
sDelegatedInstance = sDefaultInstance;
}
}
}最终走到了这里,这一步会获取ApplicationContext,以及根据useTestDatabase判断是在内存中创建数据库还是直接创建,给logger设置log等级,在这里可以看到这里设置的值就是从configuration中获取的,然后会调用createSchedulers方法,它会返回一个Scheduler的list集合
@RestrictTo(RestrictTo.Scope.LIBRARY_GROUP)
public WorkManagerImpl(
@NonNull Context context,
@NonNull Configuration configuration,
@NonNull TaskExecutor workTaskExecutor,
boolean useTestDatabase) {
Context applicationContext = context.getApplicationContext(); //获取ApplicationContext
WorkDatabase database = WorkDatabase.create(applicationContext, useTestDatabase); //创建Work数据库
Logger.setLogger(new Logger.LogcatLogger(configuration.getMinimumLoggingLevel())); //设置Logger
List schedulers = createSchedulers(applicationContext);
//调用createSchedulers返回一个List
Processor processor = new Processor(
context,
configuration,
workTaskExecutor,
database,
schedulers);
internalInit(context, configuration, workTaskExecutor, database, schedulers, processor);
} 查看createSchedulers,它会将2个Scheduler构造成list集合,第一个会根据版本判断是 SystemJobScheduler还是SystemAlarmScheduler,而第二个是GreedyScheduler,这2个的区别是GreedyScheduler会在没有约束条件或者当前约束条件全部满足时进行调用,SystemAlarmScheduler则会在有延迟任务或者一次性任务执行中断时进行调用。
@RestrictTo(RestrictTo.Scope.LIBRARY_GROUP)
public @NonNull List createSchedulers(Context context) {
return Arrays.asList(
Schedulers.createBestAvailableBackgroundScheduler(context, this),
new GreedyScheduler(context, this));
} 当createSchedulers执行完并返回Scheduler集合后,接下来创建了一个Processor对象,在初始化Processor时,会将我们传递进来的context, configuration,workTaskExecutor,database, schedulers进行保存并分别创建了map、set、list集合和一个对象锁。
public Processor(
Context appContext,
Configuration configuration,
TaskExecutor workTaskExecutor,
WorkDatabase workDatabase,
List schedulers) {
mAppContext = appContext;
mConfiguration = configuration;
mWorkTaskExecutor = workTaskExecutor;
mWorkDatabase = workDatabase;
mEnqueuedWorkMap = new HashMap<>();
mSchedulers = schedulers;
mCancelledIds = new HashSet<>();
mOuterListeners = new ArrayList<>();
mLock = new Object();
}
最后调用internalInit完成最终的初始化,这一步除了将我们传递的参数进行保存之外,在最后开启了工作线程池,并执行ForceStopRunnable,ForceStopRunnable是一个runable,查看它的run方法,它首先会判断是否需要重新执行工作,然后判断当前是否有需要去执行的任务,如果有,则调用调度器去执行该任务。到此WorkManagerImpl初始化动作完成
private void internalInit(@NonNull Context context,
@NonNull Configuration configuration,
@NonNull TaskExecutor workTaskExecutor,
@NonNull WorkDatabase workDatabase,
@NonNull List schedulers,
@NonNull Processor processor) {
context = context.getApplicationContext();
mContext = context;
mConfiguration = configuration;
mWorkTaskExecutor = workTaskExecutor;
mWorkDatabase = workDatabase;
mSchedulers = schedulers;
mProcessor = processor;
mPreferences = new Preferences(mContext);
mForceStopRunnableCompleted = false;
// Checks for app force stops.
mWorkTaskExecutor.executeOnBackgroundThread(new ForceStopRunnable(context, this));
}
@Override
public void run() {
if (shouldRescheduleWorkers()) //判断是否应该重新安排worker,此处为true的唯一条件是当我们的room数据库更新后会 变为true
{
Logger.get().debug(TAG, "Rescheduling Workers.");
mWorkManager.rescheduleEligibleWork();
// Mark the jobs as migrated.
mWorkManager.getPreferences().setNeedsReschedule(false); //执行完后,对保存的状态进行重置
} else if (isForceStopped()) { //如果被强行停止,也调用rescheduleEligibleWork进行处理
Logger.get().debug(TAG, "Application was force-stopped, rescheduling.");
mWorkManager.rescheduleEligibleWork();
} else {
WorkDatabase workDatabase = mWorkManager.getWorkDatabase(); //获取数据库对象
WorkSpecDao workSpecDao = workDatabase.workSpecDao();
try {
workDatabase.beginTransaction(); //开启数据库事务
List workSpecs = workSpecDao.getEnqueuedWork(); //将入队的worker放入到list集合
if (workSpecs != null && !workSpecs.isEmpty()) { //如果该workSpecs 不为空,表示有任务需要去执行
Logger.get().debug(TAG, "Found unfinished work, scheduling it.");
// Mark every instance of unfinished work with
// SCHEDULE_NOT_REQUESTED_AT = -1 irrespective of its current state.
// This is because the application might have crashed previously and we should
// reschedule jobs that may have been running previously.
// Also there is a chance that an application crash, happened during
// onStartJob() and now no corresponding job now exists in JobScheduler.
// To solve this, we simply force-reschedule all unfinished work.
for (WorkSpec workSpec : workSpecs) {
workSpecDao.markWorkSpecScheduled(workSpec.id, SCHEDULE_NOT_REQUESTED_YET);
}
Schedulers.schedule(
mWorkManager.getConfiguration(),
workDatabase,
mWorkManager.getSchedulers()); //最终调用该方法通过调度器去执行
}
workDatabase.setTransactionSuccessful();
} finally {
workDatabase.endTransaction();
}
Logger.get().debug(TAG, "Unfinished Workers exist, rescheduling.");
}
mWorkManager.onForceStopRunnableCompleted();
} 查看rescheduleEligibleWork,在其内部会首先根据当前版本的sdk判断是否需要调用 SystemJobScheduler.jobSchedulerCancelAll,该方法会取消该JobScheduler拥有的全部任务。然后对room数据库中保存的尚未执行完毕的WorkSpec更新状态
public void rescheduleEligibleWork() {
// TODO (rahulrav@) Make every scheduler do its own cancelAll().
if (Build.VERSION.SDK_INT >= WorkManagerImpl.MIN_JOB_SCHEDULER_API_LEVEL) {
SystemJobScheduler.jobSchedulerCancelAll(getApplicationContext());
}
// Reset scheduled state.
getWorkDatabase().workSpecDao().resetScheduledState(); //更新workspec的状态
// Delegate to the WorkManager's schedulers.
// Using getters here so we can use from a mocked instance
// of WorkManagerImpl.
Schedulers.schedule(getConfiguration(), getWorkDatabase(), getSchedulers());
}最后会调用Schedulers.schedule方法,该方法会传入3个参数,分别是数据库对象,configuration,以及任务调度器schedulers,这3个参数在我们初始化WorkManagerImpl的时候已经分析过了,在这个方法内部,首先会从workDatabase获取到数据的访问对象,并 根据configuration中的MaxSchedulerLimit作为限制条件获取符合条件的WorkSpecs并放入到list集合。并在最后使用我们传递进来的调度器对WorkSpecs调度执行。
public static void schedule(
@NonNull Configuration configuration,
@NonNull WorkDatabase workDatabase,
List schedulers) {
if (schedulers == null || schedulers.size() == 0) {
return;
}
WorkSpecDao workSpecDao = workDatabase.workSpecDao(); //获取数据访问对象
List eligibleWorkSpecs;
workDatabase.beginTransaction(); //开启事务
try {
eligibleWorkSpecs = workSpecDao.getEligibleWorkForScheduling(
configuration.getMaxSchedulerLimit()); //根据限制条件获取WorkSpecs并赋值给eligibleWorkSpecs
if (eligibleWorkSpecs != null && eligibleWorkSpecs.size() > 0) {
long now = System.currentTimeMillis();
// Mark all the WorkSpecs as scheduled.
// Calls to Scheduler#schedule() could potentially result in more schedules
// on a separate thread. Therefore, this needs to be done first.
for (WorkSpec workSpec : eligibleWorkSpecs) {
workSpecDao.markWorkSpecScheduled(workSpec.id, now); //根据workSpec的id,更新数据库中保存的workSpec的开始执行时间为当前时间
}
}
workDatabase.setTransactionSuccessful(); //事务提交成
} finally {
workDatabase.endTransaction(); //结束事务
}
if (eligibleWorkSpecs != null && eligibleWorkSpecs.size() > 0) {
WorkSpec[] eligibleWorkSpecsArray = eligibleWorkSpecs.toArray(new WorkSpec[0]);
// Delegate to the underlying scheduler.
for (Scheduler scheduler : schedulers) {
scheduler.schedule(eligibleWorkSpecsArray); //使用线程调度器去执行WorkSpec
}
}
} 上面分析过,该schedulers保存了2种调度器GreedyScheduler与SystemJobScheduler或者SystemAlarmScheduler,这3大调度器的工作工程在另外一篇博文有仔细说明3大调度器流程详细说明,最终通过它们,完成了worker的调度。
enqueue的执行过程
当我们调用WorkManager.getInstance().enqueue方法时,其实最终调用的是WorkManagerImpl的enqueue方法,在这个方法内又调用了 WorkContinuationImpl(this, workRequests).enqueue(),在实例化WorkContinuationImpl时,会将 我们传递进来的workRequest进行保存。并在addToDatabase(在EnqueueRunnable执行run方法时此方法被调用)时会根据workRequest内的配置添加workspec到数据库中并做入队操作
public Operation enqueue(
@NonNull List workRequests) {
// This error is not being propagated as part of the Operation, as we want the
// app to crash during development. Having no workRequests is always a developer error.
if (workRequests.isEmpty()) {
throw new IllegalArgumentException(
"enqueue needs at least one WorkRequest.");
}
return new WorkContinuationImpl(this, workRequests).enqueue();
} WorkContinuationImpl(@NonNull WorkManagerImpl workManagerImpl,
String name,
ExistingWorkPolicy existingWorkPolicy,
@NonNull List work,
@Nullable List parents) {
mWorkManagerImpl = workManagerImpl;
mName = name;
mExistingWorkPolicy = existingWorkPolicy;
mWork = work; //会将我们传递进来的work进行保存
mParents = parents;
mIds = new ArrayList<>(mWork.size());
mAllIds = new ArrayList<>();
if (parents != null) {
for (WorkContinuationImpl parent : parents) {
mAllIds.addAll(parent.mAllIds);
}
}
for (int i = 0; i < work.size(); i++) {
String id = work.get(i).getStringId(); /
mIds.add(id);
mAllIds.add(id);
}
}
进入该方法,返现在这里实例化了一个runable对象,并将其放入到WorkManagerImpl初始化时构造的线程池中去执行
public @NonNull Operation enqueue() {
// Only enqueue if not already enqueued.
if (!mEnqueued) {
// The runnable walks the hierarchy of the continuations
// and marks them enqueued using the markEnqueued() method, parent first.
EnqueueRunnable runnable = new EnqueueRunnable(this); //构造runable对象
mWorkManagerImpl.getWorkTaskExecutor().executeOnBackgroundThread(runnable); //去在后台线程执行
mOperation = runnable.getOperation(); //将执行结果返回
} else {
Logger.get().warning(TAG,
String.format("Already enqueued work ids (%s)", TextUtils.join(", ", mIds)));
}
return mOperation;
}看EnqueueRunnable的run方法,这里最重要的操作就是启用了RescheduleReceiver广播,以及调用scheduleWorkInBackground方法
@Override
public void run() {
try {
if (mWorkContinuation.hasCycles()) { //是不是周期性任务
throw new IllegalStateException(
String.format("WorkContinuation has cycles (%s)", mWorkContinuation));
}
boolean needsScheduling = addToDatabase(); //将WorkRequest解析,并将workspec放入数据库,完成入队操作
if (needsScheduling) { //如果需要执行
// Enable RescheduleReceiver, only when there are Worker's that need scheduling.
final Context context =
mWorkContinuation.getWorkManagerImpl().getApplicationContext();
PackageManagerHelper.setComponentEnabled(context, RescheduleReceiver.class, true); //启用该广播
scheduleWorkInBackground();
}
mOperation.setState(Operation.SUCCESS); //执行成功后将状态置为成功
} catch (Throwable exception) {
mOperation.setState(new Operation.State.FAILURE(exception)); //发生异常,状态之为失败
}
}先查看RescheduleReceiver做了什么
反编译apk进行查看,它接受3种广播,开机广播、时区变化与时间变化,当接收到系统发出的这3种广播时,其onReceive就会被调用
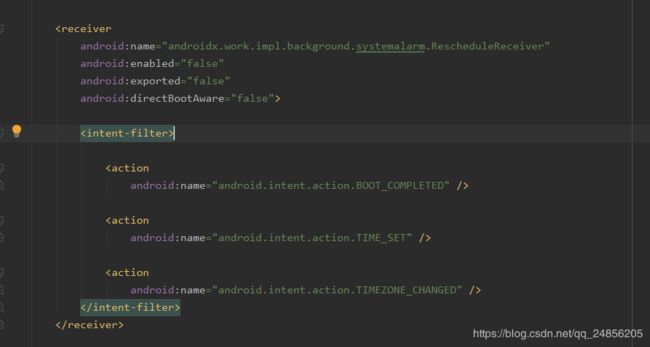
在这里会根据当前版本判断选择何种执行方式,一种是调用SystemAlarmService(详细执行流程看3大调度器流程详细说明),另外一种是 使用了一种很巧妙的方法,那就是执行一次 WorkManagerImpl的初始化过程,因为在该过程中,会将符合执行条件的worker通过调度器去执行。到此RescheduleReceiver 分析完毕。
public class RescheduleReceiver extends BroadcastReceiver {
private static final String TAG = Logger.tagWithPrefix("RescheduleReceiver");
@Override
public void onReceive(Context context, Intent intent) {
Logger.get().debug(TAG, String.format("Received intent %s", intent));
if (Build.VERSION.SDK_INT >= WorkManagerImpl.MIN_JOB_SCHEDULER_API_LEVEL) { //根据版本号判断如何执行
WorkManagerImpl workManager = WorkManagerImpl.getInstance(); //调用WorkManagerImpl.getinstance。进行初始化动作,初始化时,会检查是否有worker需要执行,如果有则调用调度器去执行,此处通过下面的goAsync,将该动作切换成异步去完成
if (workManager == null) {
// WorkManager has not already been initialized.
Logger.get().error(TAG,
"Cannot reschedule jobs. WorkManager needs to be initialized via a "
+ "ContentProvider#onCreate() or an Application#onCreate().");
} else {
final PendingResult pendingResult = goAsync(); //切换成异步执行
workManager.setReschedulePendingResult(pendingResult); //调用pendingResult .finish方法,结束异步
}
} else {
Intent reschedule = CommandHandler.createRescheduleIntent(context);
context.startService(reschedule); //在这里调用了SystemAlarmService服务,详情可看另一篇博文
}
}
}
最后查看scheduleWorkInBackground,发现它只是通过调度器去直接执行worker。3大调度器流程详细说明
public void scheduleWorkInBackground() {
WorkManagerImpl workManager = mWorkContinuation.getWorkManagerImpl();
Schedulers.schedule(
workManager.getConfiguration(),
workManager.getWorkDatabase(),
workManager.getSchedulers());
}到此为止, WorkManager的整个工作流程终于分析完毕,过程10分复杂,花费了快一周的时间才整理完毕
在此简单总结一下,整个调用的过程:
我们首先需要去构造一个类继承worker,它是任务真正执行的角色,然后通过WorkRequest对其进行装饰,添加运行的条件和各项配置,其真正的配置信息由workspec保管,最后实例化WorkManagerImpl ,在实例化时,会创建一个数据库用来保管worker的各项配置,和各种状态,服务ID等信息,实例化3种根据不同的情况去执行worker的调度器,(虽说是执行worker,其实是通过workspec判断情况,最后通过workspec中保存的信息反射构建出worker实例并最终调用dowork方法),创建执行任务的线程池等一系列初始化操作,最后调用enqueue,去执行worker。这个过程中涉及到了很多细节以及各种知识点,建议仔细研究。