OpenCV3学习(5.1)——图像变换之缩放、金字塔、仿射、透射
resize函数
OpenCV提供了resize函数来改变图像的大小,函数原型如下:
CV_EXPORTS_W void resize( InputArray src, OutputArray dst,
Size dsize, double fx=0, double fy=0,
int interpolation=INTER_LINEAR );src:输入原图像;
dst:改变大小之后的图像,这个图像和原图像具有相同的内容,只是大小和原图像不一样而已;
dsize:输出图像的大小。如果这个参数不为0,那么就代表将原图像缩放到这个Size(width,height)指定的大小;如果这个参数为0,那么原图像缩放之后的大小就要通过下面的公式来计算:
dsize = Size(round(fx*src.cols), round(fy*src.rows))
其中,fx和fy就是下面要说的两个参数,是图像width方向和height方向的缩放比例。
fx:width方向的缩放比例,如果它是0,那么它就会按照(double)dsize.width/src.cols来计算;
fy:height方向的缩放比例,如果它是0,那么它就会按照(double)dsize.height/src.rows来计算;
interpolation:这个是指定插值的方式,图像缩放之后,肯定像素要进行重新计算的,就靠这个参数来指定重新计算像素的方式,有以下几种:
INTER_NEAREST - 最邻近插值
INTER_LINEAR - 双线性插值,如果最后一个参数你不指定,默认使用这种方法
INTER_AREA - 使用像素区域关系重新采样。 它可能是图像抽取的首选方法,因为它可以提供无莫尔条纹的结果。 但是当图像被缩放时,它类似于INTER_NEAREST方法。
INTER_CUBIC - 4x4像素邻域内的双立方插值
INTER_LANCZOS4 - 8x8像素邻域内的Lanczos插值
INTER_MAX=7,
WARP_INVERSE_MAP
要缩小图像,一般推荐使用CV_INETR_AREA来插值;若要放大图像,推荐使用CV_INTER_LINEAR。
注意事项:
1. dsize和fx/fy不能同时为0,要么你就指定好dsize的值,让fx和fy空置直接使用默认值,就像 resize(img, imgDst, Size(30,30));
要么让dsize为0,指定好fx和fy的值,比如fx=fy=0.5,那么就相当于把原图两个方向缩小一倍!
2. 至于最后的插值方法,正常情况下使用默认的双线性插值就够用了。
几种常用方法的效率是:最邻近插值>双线性插值>双立方插值>Lanczos插值;但是效率和效果成反比,所以根据自己的情况酌情使用。
接下来说说图像金字塔
图像金字塔就是用来进行图像缩放的,干的事情跟resize函数没两样,金字塔的底部是待处理图像的高分辨率表示,而顶部是低分辨率的近似我们将一层一层的图像比喻成金字塔,层级越高,则图像越小,分辨率越低。
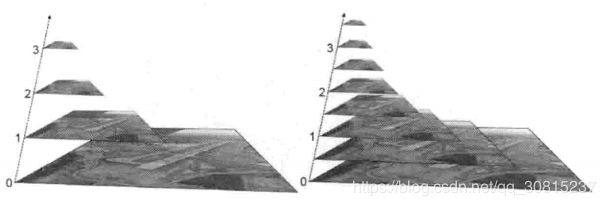
其实非常好理解,如上图所示,我们将一层层的图像比喻为金字塔,层级越高,则图像尺寸越小,分辨率越低。
两种类型的金字塔:
- 高斯金字塔:用于下采样,主要的图像金字塔;
- 拉普拉斯金字塔:用于重建图像,用来从金字塔低层图像重建上层未采样图像,在数字图像处理中也即是预测残差,可以对图像进行最大程度的还原,配合高斯金字塔一起使用。(因为小图像放大,必须插入一些像素值,那这些像素值是什么才合适呢,那就得进行根据周围像素进行预测),对图像进行最大程度的还原。
两者的简要区别:高斯金字塔用来向下降采样图像,而拉普拉斯金字塔则用来从金字塔底层图像中向上采样重建一个图像。
图像金字塔有两个高频出现的名词:上采样和下采样。现在说说他们俩。
上采样:就是图片放大(所谓上嘛,就是变大),使用PyrUp函数
下采样:就是图片缩小(所谓下嘛,就是变小),使用PryDown函数
函数原型:
void pyrDown( InputArray src, OutputArray dst,
const Size& dstsize=Size(), int borderType=BORDER_DEFAULT );
void pyrUp( InputArray src, OutputArray dst,
const Size& dstsize=Size(), int borderType=BORDER_DEFAULT );- 第一个参数,InputArray类型的src,输入图像,即源图像,填Mat类的对象即可。
- 第二个参数,OutputArray类型的dst,输出图像,和源图片有一样的尺寸和类型。
- (pyrUp)第三个参数,const Size&类型的dstsize,输出图像的大小;有默认值Size(),即默认情况下,由Size(src.cols*2,src.rows*2)来进行计算,且一直需要满足下列条件:

- (pyrDown)第三个参数,const Size&类型的dstsize,输出图像的大小;有默认值Size(),即默认情况下,由Size Size((src.cols+1)/2, (src.rows+1)/2)来进行计算,且一直需要满足下列条件:
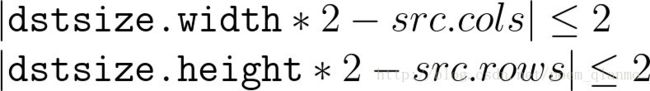
- 第四个参数,int类型的borderType,边界模式,一般不用去管它
pyrUp函数执行高斯金字塔的采样操作,其实它也可以用于拉普拉斯金字塔的。首先,它通过插入可为零的行与列,对源图像进行向上取样操作,然后将结果与pyrDown()乘以4的内核做卷积。
pyrDown函数执行了高斯金字塔建造的向下采样的步骤。首先,它将源图像与如下内核做卷积运算:

接着,它便通过对图像的偶数行和列做插值来进行向下采样操作。
pyrUp、pyrDown其实和专门用作放大缩小图像尺寸的resize在功能上差不多,披着图像金字塔的皮,说白了还是在对图像进行放大和缩小操作
下采样就是图像压缩,会丢失图像信息。下采样步骤:
- 对图像进行高斯内核卷积
- 将所有偶数行和列去除
上采样步骤:
- 将图像在每个方向放大为原来的两倍,新增的行和列用0填充;
- 使用先前同样的内核(乘以4)与放大后的图像卷积,获得新增像素的近似值。
这里的向下与向上采样,是对图像的尺寸而言(和金字塔的方向相反),向上就是图像尺寸加倍,向下就是图像尺寸减半。而如果我们按上图中演示的金字塔方向来理解,金字塔向上图像其实在缩小,这样刚刚是反过来了。 需要注意的是,PryUp和PryDown不是互逆的,即PryUp不是降采样的逆操作。这种情况下,图像首先在每个维度上扩大为原来的两倍,新增的行(偶数行)以0填充。然后给指定的滤波器进行卷积(实际上是一个在每个维度都扩大为原来两倍的过滤器)去估计“丢失”像素的近似值。
PryDown( )是一个会丢失信息的函数。为了恢复原来更高的分辨率的图像,我们要获得由降采样操作丢失的信息,这些数据就和拉普拉斯金字塔有关系了。
通过上述上采样得到的图像即为放大后的图像,但是与原来的图像相比会发觉比较模糊,因为在缩放的过程中已经丢失了一些信息,如果想在缩小和放大整个过程中减少信息的丢失,这些数据形成了拉普拉斯金字塔。
拉普拉斯金字塔第i层的数学定义:
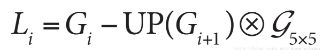
式中的 表示第i层的图像。而UP操作是将源图像中位置为(x,y)的像素映射到目标图像的(2x+1,2y+1)位置,即在进行向上取样。符号
表示第i层的图像。而UP操作是将源图像中位置为(x,y)的像素映射到目标图像的(2x+1,2y+1)位置,即在进行向上取样。符号 表示卷积,
表示卷积, 为5x5的高斯内核。 下文的pryUp,就是在进行上面这个式子的运算。
为5x5的高斯内核。 下文的pryUp,就是在进行上面这个式子的运算。
因此,我们可以直接用OpenCV进行拉普拉斯运算:
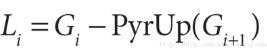
也就是说,拉普拉斯金字塔是通过源图像减去先缩小后再放大的图像的一系列图像构成的。整个拉普拉斯金字塔运算过程可以通过下图来概括:
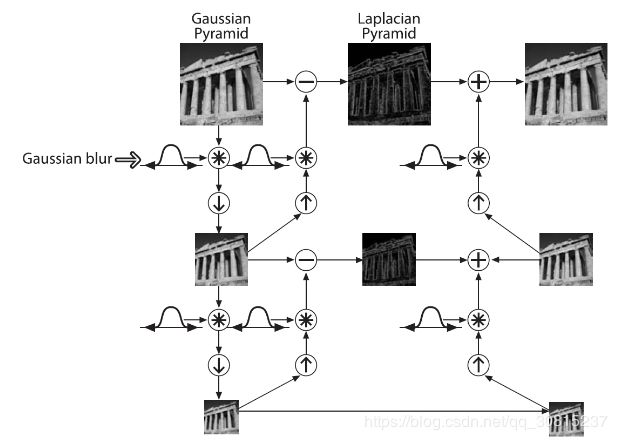
所以,我们可以将拉普拉斯金字塔理解为高斯金字塔的逆形式。
另外再提一点,关于图像金字塔非常重要的一个应用就是实现图像分割。图像分割的话,先要建立一个图像金字塔,然后在G_i和G_i+1的像素直接依照对应的关系,建立起”父与子“关系。而快速初始分割可以先在金字塔高层的低分辨率图像上完成,然后逐层对分割加以优化。
from:https://www.cnblogs.com/wyuzl/p/6294275.html
在平面图像处理中,因为镜头角度等原因,容易导致图像出现倾斜、变形等情况,为了方便后续处理我们常常需要进行图像矫正,其中主要技术原理是两种变换类型--仿射变换(Affine Transformation)和透视变换(Perspective Transformation)。
仿射变换
仿射变换是二维坐标间的线性变换, 故而变换后的图像仍然具有原图的一些性质,包括“平直性”以及“平行性”,常用于图像翻转(Flip)、旋转(Rotations)、平移(Translations)、缩放(Scale operations)等,函数原型:
CV_EXPORTS_W void warpAffine( InputArray src, OutputArray dst,
InputArray M, Size dsize,
int flags=INTER_LINEAR,
int borderMode=BORDER_CONSTANT,
const Scalar& borderValue=Scalar());src是输入图像;dst是输出图像,M是3x3变换矩阵,dsize是输出图像的大小,flags指定像素插补方法以及矩阵倒置标志cv::WARP_INVERSE_MAP;
borderMode指定边沿像素的推算模式,其中BORDER_CONSTANT指示边沿像素用borderValue替换,因为默认是0,所以我们变换后的图像边界可能会出现黑边。
上述参数中M是变换矩阵,它可以通过自定义构造,或者通过getAffineTransform函数得到,其函数原型:
Mat getAffineTransform( const Point2f src[], const Point2f dst[] );src[]:输入图像的三角形顶点坐标的数组。数组元素是三个像素点坐标,Point2f类型
dst[]:输出图像的相对应的三角形顶点坐标的数组。具体可参考下文的实例。
这里要注意:坐标Point(x,y)对应的是第y行第x列的像素点的位置。
透射变换
仿射变换不能矫正一些变形,如矩形区域的部分发生变化最终变成梯形,这时候矫正就需要用到透视变换。透视变换(Perspective Transformation),又称投影映射(Projective Mapping)、投射变换等,是三维空间上的非线性变换,可看作是仿射变换的更一般形式,简单讲即通过一个3x3的变换矩阵将原图投影到一个新的视平面(Viewing Plane),在视觉上的直观表现就是产生或消除了远近感。落实到OpenCV,图像的透视变换由函数perspectiveTransform进行向量坐标的变换):
CV_EXPORTS_W void warpPerspective( InputArray src, OutputArray dst,
InputArray M, Size dsize,
int flags=INTER_LINEAR,
int borderMode=BORDER_CONSTANT,
const Scalar& borderValue=Scalar());src是输入图像;dst是输出图像,M是3x3变换矩阵,dsize是输出图像的大小,flags指定像素插补方法以及矩阵倒置标志cv::WARP_INVERSE_MAP;
borderMode指定边沿像素的推算模式,其中BORDER_CONSTANT指示边沿像素用borderValue替换,因为默认是0,所以我们变换后的图像边界可能会出现黑边。
同上,上述参数中M是变换矩阵,它可以通过自定义构造,或者通过getAffineTransform函数得到,其函数原型:
Mat getPerspectiveTransform( const Point2f src[], const Point2f dst[] );src[]:输入图像的三角形顶点坐标的数组。数组元素是三个像素点坐标,Point2f类型
dst[]:输出图像的相对应的三角形顶点坐标的数组。具体可参考下文的实例。
实例:
#include
#include
#include
#include
#include
using namespace std;
using namespace cv;
int main() {
Mat src = imread("111.jpg", 1);
if (src.empty()) {
cout << "open failed"< 结果:

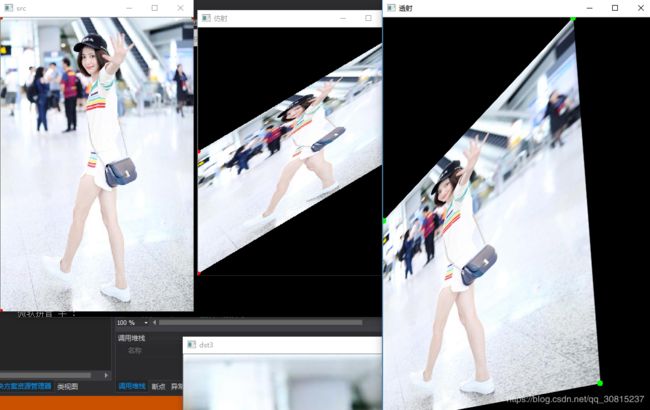


从上图看出:图像与原图相比,变模糊了,信息损失了。
补充一个函数circle,用于画圆,函数原型:
CV_EXPORTS_W void circle(CV_IN_OUT Mat& img, Point center, int radius,
const Scalar& color, int thickness=1,
int lineType=8, int shift=0);img为源图像指针;center为画圆的圆心坐标;radius为圆的半径;color为设定圆的颜色,用Scale类型,顺序是BGR。
thickness 如果是正数,表示组成圆的线条的粗细程度。否则,表示圆被填充;
line_type 线条的类型。默认是8;shift 圆心坐标点和半径值的小数点位数。