深入理解VGG16模型
一、简述
VGG卷积神经网络是牛津大学计算机视觉实验室参加2014年ILSVRC(ImageNet Large Scale Visual Recognition Challenge)比赛的网络结构,为了解决ImageNet中的1000类图像分类和定位问题。实验结果是VGGNet斩获了2014年ILSVRC分类第二,定位第一,分类第一是GoogleNet模型。
想要更好的理解和掌握VGG系列的模型,建议阅读原论文:VGG论文链接
二、模型结构
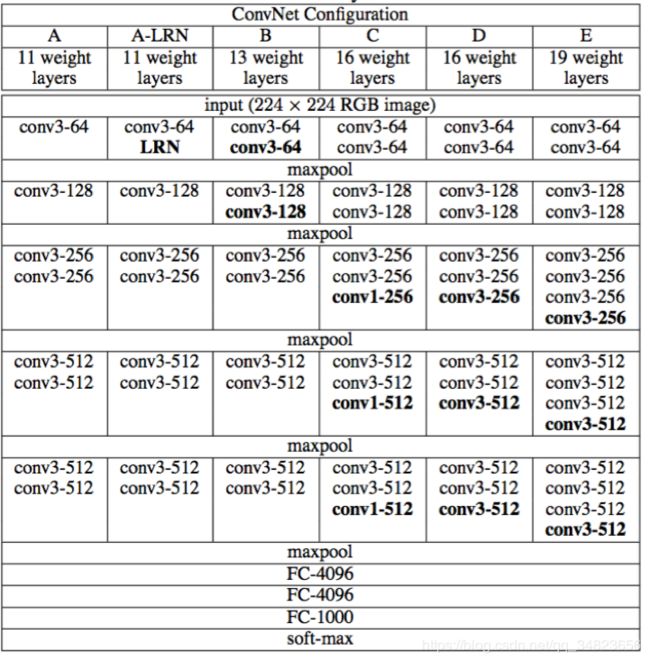
上图是VGGNet系列的结构说明,其中最著名的是VGG16模型,也就是上图中的D结构。
VGG16输入尺寸变化具体如下图所示:
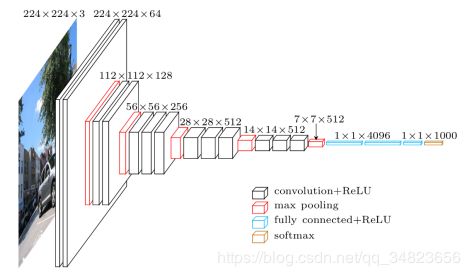
从上述两个图可以得到,VGG16共有16个层,这也是VGG16名称的由来,是一个相当深的卷积神经网络。VGG各种级别的结构都采用了5段卷积,每一段有一个或多个卷积层。同时每一段的尾部都接着一个最大池化层来缩小图片尺寸。每一段内的卷积核数量一致,越靠后的卷积核数量越多 64-128-256-512-512。经常出现多个完全一样的卷积层堆叠在一起的情况。
下面是VGG16模型的示意:
input(224,224,3)->
conv(3,3,64)*2 -> mp(2) -> conv(3,3,128)*2 -> mp(2) -> conv(3,3,256)*3 ->
mp(2) -> conv(3,3,512)*3 ->mp(2) -> conv(3,3,512)*3 -> mp(2) ->
fc(4096) -> fc(4096) -> fc(1000) -> softmax ->
output
有些小伙伴可能不理解为什么是16层,我这里大概说一下:
2个包含64个卷积核的卷积层+
2个包含128个卷积核的卷积层+
3个包含256个卷积核的卷积层+
6个包含512个卷积核的卷积层+
2个包含4096个神经元的全连接层+
1个包含1000个神经元的全连接层
2+2+3+6+2+1是不是等于16呢?
三、深入理解VGG16模型
作者在学习VGG16模型的时候,上网查找了很多关于VGG16模型的文章,但是感觉大家都只是在介绍VGG16模型本身的结构而已,至于为什么要这样设计似乎很少有人提及,所以作者一直都是一知半解的,对于想要更好的理解和掌握VGG16,甚至去改进它,就需要深入理解隐藏在模型结构背后的直觉和原理,后来在不经意间,看到一篇不错的文章,感觉很有帮助~,在这里分享给大家:卷积神经网络VGG 论文细读
要理解VGG16模型的设计原理,首先要理解卷积神经网络两大特点:
1:局部连接
2:权值共享
在这里作者就不再详细的介绍这两大特点了,如果对这两个特点还不了解的或者了解地不透彻可以移步到:CNN初步认识(局部感知、权值共享)
深度:对于局部连接来说,每个神经元的输出就只和该神经元上一层周围的局部神经元有关,这样就可以使得网络的参数大大降低,可以设计更深的网络模型,这样做肯定有坏处,可能会丢失一些全局信息,但如果我们设计的网络结构很深,那么可以在高层对网络低层的局部特征进行组合,最终得到全局特征。所以这似乎是一个很巧妙的特点,一方面局部连接可能会丢失全局特征,但另一方面它又可以设计出更深的网络模型,从而得到全局特征。深度对网络的性能极其重要,一般来说越深的深度网络性能也就越好,深度网络自然集成了低、中、高层特征,可以表达出更丰富的特征和含义。在VGG系列模型中,网络深度达到16-19层,是当时在论文发表前最深的深度网络,所以它表现出了极佳的性能。
宽度:对于权值共享来说,这里的权值指的是卷积核的权值,所谓共享指的是从一个局部区域学习到的信息,应用到图像的其它地方去,即用一个相同的卷积核去卷积整幅图像。通过权值共享,使得网络中训练的参数大大减少,可以帮助我们训练更深的模型。其次,也由于权值共享,一个卷积核也就只能学到相应的某个特征,所以我们需要设计多个不同的卷积核来提取图像中不同的特征,卷积核的数量也成为卷积神经网络的宽度,在VGG16模型中,最开始是64个卷积核,随着网络的加深,卷积核数量一直增加到512,是一个很宽的网络,所以它最后的性能如此之强大也不足为奇了。
卷积核:同时我们可以发现,VGG模型中所有的卷积核大小均为3×3,使用3×3的小卷积核堆叠代替大卷积核,主要有以下几个原因:
(1)3x3是最小的能够捕获像素八邻域信息的尺寸。
(2)两个3x3的堆叠卷基层的有限感受野是5x5;三个3x3的堆叠卷基层的感受野是7x7,故可以通过小尺寸卷积层的堆叠替代大尺寸卷积层,并且感受野大小不变。所以可以把三个3x3的filter看成是一个7x7filter的分解中间层有非线性的分解, 并且起到隐式正则化的作用。
(3)多个3x3的卷基层比一个大尺寸filter卷基层有更多的非线性(更多层的非线性函数,使用了3个非线性激活函数),使得判决函数更加具有判决性。
(4)多个3x3的卷积层比一个大尺寸的filter有更少的参数,假设卷积层的输入和输出的特征图大小相同为C,那么三个3x3的卷积层参数个数3x((3x3xC)xC)=27C²;一个(7x7xC)xC的卷积层参数为49C²。前者可以表达出输入数据中更多个强力特征,使用的参数也更少。
唯一的不足是,在进行反向传播时,中间的卷积层可能会导致占用更多的内存。
池化核:相比AlexNet的3x3的池化核,VGG全部采用2x2的池化核,可以保留更多的图像信息。
全连接转卷积(测试阶段):这也是VGG的一个特点,在网络测试阶段将训练阶段的三个全连接层替换为三个卷积层,使得测试得到的全卷积网络因为没有全连接的限制,因而可以接收任意宽或高为的输入,这在测试阶段很重要。
卷积层和全连接层的唯一区别在于卷积层的神经元对输入是局部连接的,并且同一个通道(channel)内不同神经元共享权值(weights). 卷积层和全连接层都是进行了一个点乘操作, 它们的函数形式相同. 因此卷积层可以转化为对应的全连接层, 全连接层也可以转化为对应的卷积层。
比如VGGNet[1]中, 第一个全连接层的输入是77512, 输出是4096. 这可以用一个卷积核大小77, 步长(stride)为1, 没有填补(padding), 输出通道数4096的卷积层等效表示, 其输出为11*4096, 和全连接层等价. 后续的全连接层可以用1x1卷积等效替代。 简而言之, 全连接层转化为卷积层的规则是: 将卷积核大小设置为输入的空间大小.这样做的好处在于卷 积层对输入大小没有限制, 因此可以高效地对测试图像做滑动窗式的预测.
总结:
1、通过增加深度和宽度能有效地提升性能;
2、最佳模型:VGG16,从头到尾只有3x3卷积与2x2池化,简洁优美;
3、卷积可代替全连接,测试阶段可适应各种尺寸的图片。
参考文献:
https://www.jianshu.com/p/68ac04943f9e
https://blog.csdn.net/dulingtingzi/article/details/79832056
https://blog.csdn.net/qq_30159015/article/details/79710364