Optical Flow Guided Feature: A Fast and Robust Motion Representation for Video Action Recognition 翻译
光流引导特征:视频动作识别的快速鲁棒运动表示

项目地址:https://github.com/kevin-ssy/Optical-Flow-Guided-Feature
摘要
运动表示在视频中的人类动作识别中起着至关重要的作用。
在本研究中,我们介绍了一种用于视频动作识别的新颖紧凑运动表示,称为光流引导特征(OFF),它使网络能够通过快速而稳健的方法提取时间信息。
OFF来自光流的定义并且与光流正交。
推导还为使用两帧之间的差异提供了理论支持。
通过直接计算深度特征映射的逐像素时空梯度,OFF可以嵌入任何现有的基于CNN的视频动作识别框架中,仅需要少量额外成本。
它使CNN能够同时提取时空信息,尤其是帧之间的时间信息。
这个简单但强大的想法通过实验结果得到验证。
仅通过RGB输入馈电的OFF网络在UCF-101上实现了93.3%的竞争准确度,这与两个流(RGB和光流)获得的结果相当,但速度快15倍。
实验结果还表明,OFF与其他运动方式(如光流)互补。当所提出的方法插入到最先进的视频动作识别框架中时,它在UCF-101和HMDB-51上的准确率分别为96.0%和74.2%。
介绍
如何设计/使用既快速又健壮的运动表示?为此,所需的计算应该是经济的,并且表示应该由运动信息充分指导。
考虑到上述要求,我们提出了光流导引特征(OFF),它计算速度快,可以综合地表示视频片段中的运动动力学。
在本文中,我们从正交空间的光流部分在特征级上定义了一个新的特征表示。 这种定义将光流的引导带到这里的表示,因此,我们称之为光流引导特征(OFF)。
该特征包括水平方向和垂直方向的特征映射的空间梯度,以及从不同帧的特征映射之间的差异获得的时间梯度。
由于OFF中的所有操作都是可微的,所以当OFF插入到一个CNN架构中时,整个过程是端到端可训练的。
实际上,OFF单元仅由CNN特征的像素化算子组成。
这些操作符应用迅速,并使得具有RGB输入的网络能够同时捕获空间和时间信息。
OFF中的一个重要组成部分是来自不同图像/片段的特征之间的差异。
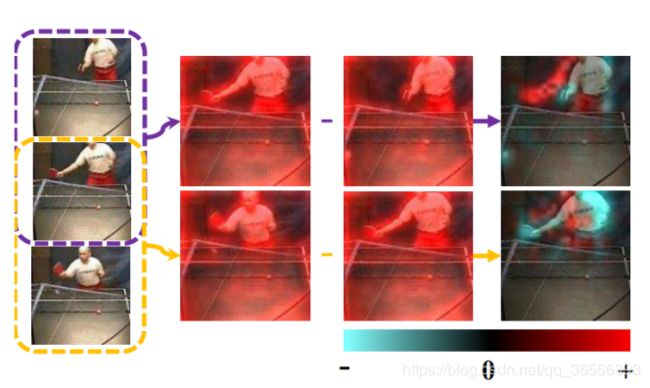
如图1所示,来自两个图像的特征之间的差异提供了可以由CNN方便地使用的代表性运动信息。
差异图像中的负值描绘了身体部位/物体消失的位置,而正值表示它们出现的位置。
这种在一个位置消失并在另一个位置出现的模式可以很容易地被视为特定的运动模式并被后来的CNN层捕获。
时间差可以进一步与空间梯度组合,使得根据我们在后面部分中的推导,由特征水平上的光流引导构成的OFF。
图1 光流引导功能(OFF)
左栏:输入框架。 中间两列:在将OFF应用到两个帧之前的标准深度特征。 右栏:OFF的时间差异。 红色和青色分别用于正值和负值。 两帧之间的特征差异在表示运动信息时是有效且全面的。
此外,特征级别的运动动态的计算更快且更稳健,因为
1)它使空间和时间网络具有权重共享的能力
2)深度学习的特征传达更多的语义和判别表示,可靠地消除局部和原始帧中的背景噪声。
贡献
首先,OFF是快速且稳健的运动表示。
OFF快速启用超过200帧/秒,只有RGB作为输入,并且来自光流并由光流引导。
仅从视频中获取RGB,实验结果表明,与最先进的基于光流的算法相比,具有OFF的CNN性能接近。
具有OFF的CNN在UCF-101上可以达到93.3%,只有RGB作为输入,这是目前基于RGB的动作识别方法中最先进的。
当以双流方式(RGB +光流)在最先进的动作识别方法中插入OFF时,我们的算法的性能可以导致UCF-101的96.0%和HMDB-51的74.2%。。
其次,可以以端到端的方式训练配备OFF的网络。
以这种方式,空间和运动表示可以通过单个网络共同学习。
此属性适用于大型数据集上的视频任务,因为它可能不需要网络预先计算和存储运动模式以进行训练。
此外,OFF可以在图像级别和特征级别的视频剪辑中的图像/片段之间使用。
相关工作
传统方法提取手工制作的局部视觉特征,如3DHOG,运动边界直方图(MBH),改进的密集轨迹(iDT),然后将它们编码为稀疏或紧凑的特征向量分类器。
之后,又发现深度学习的特征比手工制作的动作识别特征更好。
基于TwoStream的框架使用深度CNN学习光学流动和iDT等手工艺动作特征作为动作识别的重大突破。
这些尝试在提高识别准确度方面取得了显着进步,但仍然依赖于预先计算的光流或iDT,这限制了整个框架的速度。
为了快速获得运动模态,最近的工作仅在训练阶段使用光流,或者提出的运动矢量作为光流的简化版本。
这些尝试产生了降低的光流结果,并且仍然没有与使用传统光流作为输入流的方法相同。
许多方法学习使用3D CNN直接从输入帧捕获运动信息。
通过时间卷积和池化操作,3D CNN可以提取连续帧之间的时间信息,而无需将它们分割成短片段。
与学习捕获运动信息的滤波器相比,我们的OFF是数学上从光流中得出的原理表示。
受网络设计,训练样本和重量衰减等参数正则化约束的3D CNN可能无法像OFF一样学习良好的运动表示。
因此,当前最先进的基于3D CNN的算法仍然依赖于传统的光流来帮助网络捕获运动模式。
相比之下,我们的OFF:
1)捕获运动模式,使得带有OFF的RGB流与两种流方法相同
2)也与光流等其他运动表示互补
为了从视频中捕获长期的时间信息,一种直观的方法是引入长短期存储器(LSTM)模块作为编码器,以编码序列说明的深层特征之间的关系。
LSTM仍然可以应用于OFF。
因此,我们的OFF与这些方法是互补的。
与我们的工作同时地,另一个最新的方法应用了称为分级池的策略,该策略生成快速视频级别的描述符,即,动态图像。
然而,动态图像与我们的设计和实现的本质是不同的。
动态图像被设计为概括一系列帧,而我们的方法被设计为捕获与光流相关的运动信息。
光流引导特征
我们提出的OFF受到传统光流定义的著名亮度常数约束的启发。 它的表述如下:
I(x, y, t) = I(x + ∆x, y + ∆y, t + ∆t)
其中I(x, y, t) 表示a的位置(x,y)处的像素在时间t的框架。 对于帧t和(t +Δt),Δx和Δy分别是x和y轴上的空间像素位移。
假设对于在帧t从(x,y)移动到帧t +Δt处的(x +Δx,y +Δy)的任何点,其亮度随时间保持不变。 当我们在特征级别应用此约束时,我们有
f(I; w)(x, y, t) = f(I; w)(x + ∆x, y + ∆y, t + ∆t)
其中f是用于从图像I中提取特征的映射函数.w表示映射函数中的参数。 映射函数f可以是任何可微函数
在本文中,我们采用可训练的CNN,包括卷积,ReLU和汇集操作。 根据光流的定义,我们假设p =(x,y,t)并得到如下等式:
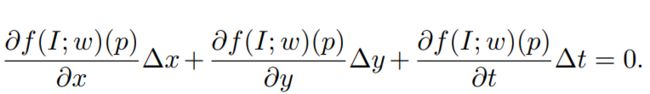
通过将上面等式两侧的除以Δt得到

其中p =(x,y,t),(vx,vy)表示p处特征点的二维速度
 和
和 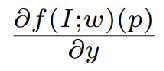 分别是x和y轴上∂f(I; w)(p)的空间梯度。
分别是x和y轴上∂f(I; w)(p)的空间梯度。
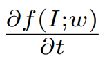 是沿时间轴的时间梯度。
是沿时间轴的时间梯度。
作为特殊情况,当f(I; w)(p)= I(p)时,则f(I; w)(p)仅表示p处的像素。
在这种特殊情况下,(vx,vy)称为光流。
对于每个p ,通过用上面最后一个等式中的约束求解优化问题来获得光流。
在这种情况下,术语  表示RGB帧之间的差异。
表示RGB帧之间的差异。
以前的研究表明,帧之间的时间差异在视频相关任务中很有用,然而,没有理论证据可以帮助解释为什么这个简单的想法很有效。
在这里,我们可以发现它与空间特征和光流的相关性。
我们概括了从像素I(p)到特征f(I; w)(p)的光流表示。
在这种一般情况下,[vx,vy]称为特征流。
从式4可以看出, 与包含特征级光流的矢量
与包含特征级光流的矢量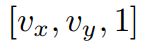 正交。
正交。 随着特征级光流的变化而变化。
随着特征级光流的变化而变化。
因此,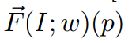 由特征级光流引导。
由特征级光流引导。
我们将  称为光流引导特征(OFF)。
称为光流引导特征(OFF)。
OFF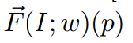 对特征级光流(vx,vy)正交且互补地编码空间 - 时间信息。
对特征级光流(vx,vy)正交且互补地编码空间 - 时间信息。
在卷积神经网络中使用光流引导特征——网络架构
网络架构概述。
图2显示了整个网络架构的概述。
该网络包括三个用于不同目的的子网:特征生成子网,OFF子网和分类子网。 特征生成子网使用常见的CNN结构生成基本特征。
在OFF子网中,使用来自特征生成子网的特征提取OFF特征,然后堆叠若干残余块以获得精细特征。
然后,分类子网使用前两个子网的特征来获得动作识别结果。
图2 网络架构概述
特征生成子网络为从视频采样的每个帧提取特征。
基于由特征生成子网络提取的两个相邻帧的特征,应用OFF子网络以生成OFF以进行进一步分类。
来自所有子网络的分数被融合以获得最终结果。
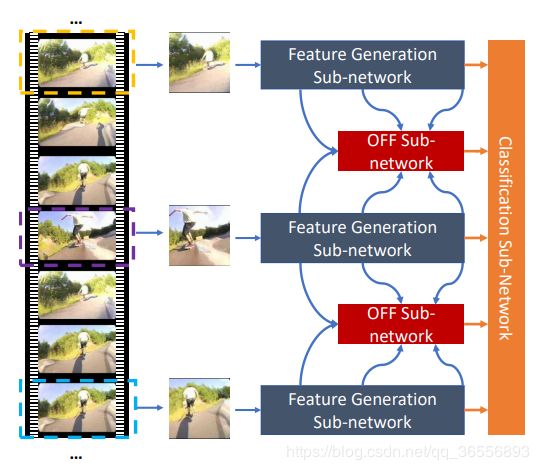
图3展示了具有两个段输入的更详细的网络结构。
如图3所示,我们通过将它们连接在一起并将它们馈送到一个OFF单元,从特定级别的多个层中提取具有相同分辨率的特征。
整个网络有3个不同规模的OFF单元。
图3 两个网段的网络架构概述
输入是蓝色和绿色的两个段,分别馈入特征生成子网以获得基本特征。
在我们的实验中,每个特征生成子网络的主干是BN-Inception 。
这里K表示选择用于经历OFF子网以获得OFF特征的方形特征映射的最大边长。
OFF子网由几个OFF单元组成,并且几个残余块连接在不同分辨率级别的OFF单元之间。
当从整体上看时,这些残余块构成ResNet-20。
由不同子网络获得的分数是独立监督的。
OFF单元的详细结构如图4所示。

特征生成子网
基本特征f(I)(相当于前一节中的表示f(I; w))是使用几个卷积层从输入图像中提取的,其中整流线性单元(ReLU)用于非线性函数,最大池用于下采样。
我们选择BN-Inception 作为网络结构来提取特征图。
功能生成子网可以由任何其他网络架构替换。
OFF子网
OFF子网由几个OFF单元组成。
不同的单位使用不同深度的基本特征f(I)。
如图4所示,OFF单元包含OFF层以产生OFF。
每个OFF层包含用于每个特征的1×1卷积层,以及包括用于OFF生成的sobel和元素减法的一组运算符。
在获得OFF之后,OFF单元将它们与来自较低级别的特征连接在一起,然后组合的特征将输出到以下残余块。
图4 OFF单元的详细结构
1x1卷积层连接到输入基本特征以进行降维。
之后,我们利用Sobel算子和逐元素减法分别计算空间和时间梯度。
梯度的组合构成OFF,并且Sobel算子,减法运算符和它们之前的1×1卷积层构成OFF层。

OFF层负责从基本特征f(I)生成OFF。
图4显示了OFF层的详细实现。
根据等式3,OFF应包括特征的空间和时间梯度。
将f(I,c)表示为基本特征f(I)的第c个通道。
将Fx和Fy分别表示为x和y方向的梯度的OFF,其对应于空间梯度。
我们将Sobel算子应用于空间梯度生成如下

其中*表示卷积运算,常数Nc表示特征f(I)的通道数。 将Ft表示为时间方向上的梯度的OFF。
时间梯度通过元素减法获得如下:
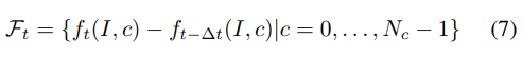
通过上面获得的Fx,Fy和Ft特征,我们将它们与较低级别的特征连接在一起作为OFF层的输出。
我们在Sobel和减法运算之前使用1×1卷积层来减少通道数。
在我们的实验中,无论输入通道有多少,通道尺寸都会减小到128。
然后将该特征输入OFF单元以计算我们在前一节中定义的OFF。
在获得OFF之后,几个残余块以不同的分辨率水平连接在OFF单元之间作为细化。
在OFF单元附近的残余块中,OFF的维数进一步降低,以节省计算量和参数数量。
不同分辨率级别的残差区块最终构成ResNet-20。
请注意,在我们的残差网络中没有应用批量标准化操作以避免过度拟合问题。
OFF单元可以应用于不同级别的CNN层。
一个OFF单元的输入包括两个段的基本深度特征,以及前一个特征级别的OFF单元的特征(如果存在)。
以这种方式,前一语义级别的OFF可用于在当前语义级别上细化OFF。
分类子网
分类子网络从不同来源获取特征,并使用多个内积分类器来获得多个分类分数。
然后,通过对每个特征生成子网或OFF子网进行平均来组合所有采样帧的分类分数。
语义级别的OFF可以用于在训练阶段产生分类分数,使用其相应的损失来学习。
事实证明,这种策略在许多任务中都很有用。 在测试阶段,可以组装来自不同子网的分数以获得更好的性能。
网络训练
动作识别被视为多类分类问题。
接下来是TSN中的设置,因为每个分段产生多个分类分数,我们需要将它们分别融合在每个子网中,以生成用于损失计算的视频级分数。
这里,对于OFF子网,由级别1上的第t段的OFF子网的输出产生的特征由Ft,l表示。
使用Ft,l在级别 l 上的段t的分类得分由Gt,l表示。 级别1的聚合视频级别得分由G1表示。
视频级动作分类得分Gl通过以下方式获得:

其中Nt表示用于提取特征的帧数。
由G表示的聚合函数用于总结从不同段沿时间预测的分数。
在TSN进行调查后,G通过平均汇集实现以获得更好的性能。
对于特征生成子网,上述等式也是适用的。
虽然我们不需要对特征生成子网络进行中间监督,但是对于段t,级别1的特征Ft,l简单地等同于子网络的最终特征输出。
为了更新整个网络的参数,将损失设置为标准分类交叉熵损失。
由于每个特征级别的子网都是独立监督的,因此每个级别都使用一个损失函数:

其中C是动作类别的数量,Gl,c是来自级别l的特征的类c的估计分数,yc代表地面实况类别标签。
通过使用此损失函数,我们可以通过反向传播优化网络参数。
训练的详细实施——两阶段培训策略
整个网络的培训包括两个阶段。
第一阶段确实是应用现有方法,例如 TSN ,用于训练特征生成子网。
在第二阶段,我们训练OFF和分类子网络,其中特征生成子网络中的所有权重都被冻结。
从头开始学习OFF子网和分类子网的权重。
整个网络可以以端到端的方式进一步微调,但是,我们在这个阶段没有发现显著的收益。
为了简化培训过程,我们只使用前两个阶段训练网络。
训练的详细实施——培训期间的中级监督
在许多其他计算机视觉任务中,中级监督已被证明是实用的培训策略。
由于OFF子网由中间输入馈送,这里我们在每个级别添加中间监督,以在每个分辨率级别上获得更好的OFF。
训练的详细实施——降低内存成本
由于我们的框架由几个子网络组成,因此它比原始TSN框架花费更多的内存,TSN框架在训练CNN之前提取和存储运动帧,并且独立地训练多个网络。
为了降低计算和纪念成本,我们在训练阶段采样的帧少于测试阶段,并且仍然获得满意的结果。
网络测试
由于不同的子网络产生了多个分类分数,我们需要在测试阶段将它们融合在一起以获得更好的性能。
在本研究中,我们通过简单的求和操作来汇总特征生成子网和最后一级OFF子网的分数。
我们选择基于最先进的框架TSN来测试我们的模型。
TSN框架下的测试设置如下所示:
- 在TSN的测试阶段,从RGB,RGB差异和光流中采样25个段。
- 但是,每个段中的帧数在这些模态中是不同的。
- 我们使用TSN采用的原始设置分别为RGB,RGB差异和光流采样每段1,5,5帧。
- 我们网络的输入是25个段,其中第t个段被视为图3中的帧T。
- 在这种情况下,由我们的特征生成子网的单独分支提取的特征是用于段而不是帧时使用TSN。
- 其他设置与TSN中的设置保持一致。
测试与评估——数据集
实验结果在两个流行的视频动作数据集UCF-101和HMDB-51上进行了评估。
UCF-101数据集有13320个视频,分为101个类,而HMDB51包含6766个视频和51个类。
我们的实验遵循官方提供的方案,该方案将数据集划分为3个训练和测试分裂,最后计算所有3个分裂的平均准确度。
我们通过直接使用OpenCV实现的算法在训练之前准备帧之间的光流。
测试与评估——实施细节
我们使用4个NVIDIA TITAN X GPU训练我们的模型,在Caffe和OpenMPI上实施。
我们首先使用相应方法中提供的相同策略训练特征生成子网络。
然后在第二阶段,我们从头开始训练OFF子网络,并冻结特征生成子网络中的所有参数。
这里采用小批量随机梯度下降算法来学习网络参数。
当特征生成子网由RGB帧馈送时,OFF子网的整个训练过程需要20000次迭代才能收敛,初始化为0.02的学习率,并在迭代10000,15000处使用多步策略降低到0.1。
当输入改变为光流等时间模态时,学习速率初始化为0.05,其他策略与RGB中提出的策略保持一致。
Batch大小设置为128,并应用前面部分中描述的所有训练策略。
在UCF-101和HMDB-51上进行评估时,我们在OFF的空间流上添加了丢失模块。不同方式的训练参数没有差异。
然而,当输入是RGB差异或光流时,随着更多帧被读入网络,在训练和测试阶段将花费更多时间。
先决条件
- OpenCV 2.4.12
- OpenMPI 1.8.5(安装时启用线程多重)
- CUDA 7.5
- CUDNN 5
- Caffe依赖
模型下载

表1
在三个分裂splits上的UCF-101上的不同实时视频动作识别方法的准确性和效率的实验结果。 这里的符号流表示运动模态光流。 请注意,我们的基于OFF的算法可以实现实时算法中最先进的性能。

表2
使用UCF-101 Split1上的OFF的不同模态的实验结果。这里Flow表示光流。 OFF(*)表示输入*使用OFF。 例如,OFF(RGB)表示对RGB输入使用OFF。这里的速度说明了网络转发的时间成本。RGB和RGB + Flow的结果来自[43]。 当与RGB融合时,OFF(RGB)可提供4.5%的强劲改善。

表3
超级网络精度的实验结果以及与UCF-101 Split1上的OFF的比较。 “Hyp-Net”表示超列组网络的输出。

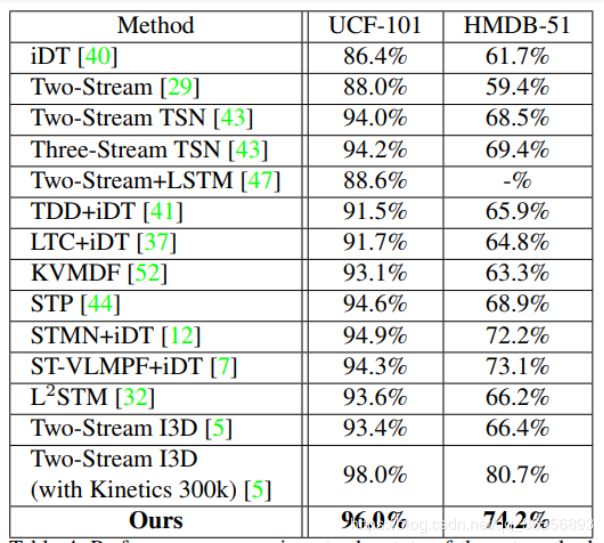
表4
与UCF-101和HMDB-51上最先进的方法进行3次分割的性能比较。
结论
在本文中,我们提出了光流引导特征(OFF),这是一种源自光流并由光流引导的新颖运动表示。
OFF既快又强劲。
通过将OFF插入CNN框架,在UCF-101上只有RGB作为输入的结果甚至可以与双流(RGB +光流)方法获得的结果相比,同时,OFF插入的网络仍然是非常高效,速度超过每秒200帧。
此外,已经证明OFF仍然是其他运动表示(如光流)的补充。
基于此表示,我们提出了一种用于视频动作识别的新CNN架构。
该架构在两个流行的视频数据集UCF-101和HMDB-51上优于许多其他最先进的视频动作识别方法,并且可用于加速基于视频的任务的速度。
在未来的工作中,我们将在其他基于视频的任务和数据集上验证我们的方法。