SVM支持向量机与sklearn支持向量机分类
一、SVM的基本概念
1、总览:
在之前的机器学习基本知识中,总结了支持向量机的相关基础概念。
支持向量机(Support Vector Machine, SVM)是定义在特征空间上间隔最大的线性分类器。它是一种二分类模型,当采用核技巧之后,支持向量机可以用于非线性分类。
划分超平面:能将训练集在样本空间中将不同类的样本划分开的超平面,划分超平面可以用wTx+b=0表示,w为法向量,b为超平面相对于原点的位移项,就是距离。该划分超平面由法向量w和位移b确定。
支持向量:划分超平面由法向量w和位移b确定。这时我们可知任一点x到超平面(w,b)的距离。对于二分类,若超平面可以将训练样本正确分类,如式子中显示,且那些离超平面最近的几个训练样本可以使用式子中的等号成立,这些样本就称为支持向量。
分类间隔:两个异类支持向量到超平面的距离之和就是间隔
优化目标:优化目标是最大化分类间隔,找到能满足不等式约束的w和b参数,从而得出支持向量机的基本型。上式为一凸二次规划问题,可以转化为最小化的形式,我们使用拉格朗日对偶算法求解。
核函数:前面的假设训练样本是线性可分的,现实中大部分不是。这时我们可将样本从原始空间映射到一个更高维的特征空间。找到合适的划分超平面,一定存在一个高位空间使样本可划分。高维向量的内积很难,使用核函数计算的是样本映射到特征空间之后的内积。核函数的合适的选择很重要,若不合适就会映射到一个不合适的特征空间里。
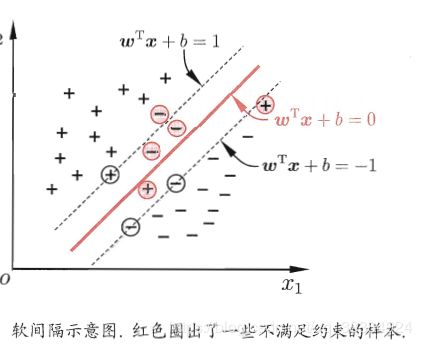
问题:即使恰好找到某个核函数使得训练集在特征空间线性可分,也难以确定这个结果不是由于过拟合造成的。可以让SVM在一些样本上出错,引入了软间隔的概念。
硬间隔:所有样本完全满足约束。当C无穷大时,为硬间隔。
软间隔:就是有一些样本不满足约束,可见软间隔的损失函数。当C为有限值时,允许一些样本不满足约束。
软间隔的替代损失函数:通常是凸的连续函数,如图所示。比如采用hinge损失,还可引入松弛变量,松弛比那里表示某样本不满足约束的程度。如果采用对数损失,几乎得到的就是对数几率回归模型。
软间隔的目标函数:使用替代损失函数后得到的模型的优化目标函数,第一项都是描述划分超平面的间隔大小,第二项表述训练集上的误差。前者称为结构风险,描述模型f的性质,后者为经验风险,描述模型与训练数据的契合程度。C对二者进行折中。从经验风险最小化的角度看,前一项为正则化项,其智能和称为正则化项,C为正则化常数。正则化项常有以下几种:Lp范数是常用的正则化项,L2范数||w||2倾向w的分量取值尽量均衡,即非零分量个数尽可能稠密,L0和L1倾向w尽可能系数,非零分量尽可能少。
因此软间隔SVM优化目标为最小化:分类间隔与(C乘以松弛变量之和)的和,C为λ的倒数,它是SVM中的约定,减小C相当于增大正则化强度,惩罚不严格,增大C,我们要施加大的惩罚力度。通过C,从而控制对错误变量的惩罚度。
支持向量回归:与传统的回归损失的计算不同,它SVR假设最大有e的偏差,当输出值和真实值差别绝对值大于e的时候才计算损失,f(x)为模型输出,可表示为超平面,以f(x)为中心,构建一个2e的间隔带,落在其中(在误差范围内)样本则认为是被正确预测的。
核方法:若不考虑偏移项b,则无论SVM还是SVR,学得的模型总能表示成核函数的线性组合形式。对于一般的损失函数和正则化项,优化问题的最优解可表示为核函数的线性组合。一系列基于核函数的学习方法,统称为“核方法”,最常见的是通过核化,将线性学习器拓展为非线性学习器。
因此SVM优化目标为最小化:分类间隔与(C乘以松弛变量之和)的和,C为λ的倒数,它是SVM中的约定,减小C相当于增大正则化强度,惩罚不严格,增大C,我们要施加大的惩罚力度。通过C,从而控制对错误变量的惩罚度。
我们可以运用不同类型的支持向量机解决不同的问题:
(1)线性可分支持向量机(也称为硬间隔支持向量机):当训练数据线性可分时,通过硬间隔最大化,学得一个线性可分支持向量机。
(2)线性支持向量机(也称为软间隔支持向量机):当训练数据近似线性可分时,通过软间隔最大化,学得一个线性支持向量机。
(3)非线性支持向量机:当训练数据不可分时,通过核技巧以及软间隔最大化,学得一个非线性支持向量机。核方法:使用SVM解决非线性问题:通过映射函数,将样本的原始特征映射到一个使样本到可分的更高维空间去,在新的特征空间上训练一个线性SVM模型。最常用的是高斯核,可见核是一对样本之间的映射函数。
下面是数学理解:

二、sklearn支持向量机学习
中文文档,英文文档
1、SVM的用途
支持向量机 (SVMs) 可用于以下监督学习算法: 分类, 回归 和 异常检测.。
支持向量机的优点:(1)在高维空间中非常高效,即使在数据维度比样本数量大的情况下仍然有效;(2)在决策函数(称为支持向量)中使用训练集的子集,因此它也是高效利用内存的;(3)通用性: 不同的核函数与特定的决策函数一一对应,常见的 kernel 已经提供,也可以指定定制的内核;
支持向量机的缺点:(1)如果特征数量比样本数量大得多,在选择核函数 核函数 时要避免过拟合, 而且正则化项是非常重要的;(2)支持向量机不直接提供概率估计,这些都是使用昂贵的五次交叉验算计算的。
2、支持向量机分类
2.1。基本分类
SVC,NuSVC 和 LinearSVC 能在数据集中实现多元分类。
(1)异同:SVC 和 NuSVC 是相似的方法, 接受稍许不同的参数设置并且有不同的数学方程。LinearSVC 是另一个实现线性核函数的支持向量分类.。 LinearSVC 不接受关键词 kernel, 因为它被假设为线性的。它也缺少一些 SVC 和 NuSVC 的成员(members) 比如 support_ 。
(2)输入类型:和其他分类器一样, 将两个数组作为输入:X是[n_samples, n_features] 大小的数组 ,作为训练样本;y是 [n_samples] 大小的数组,作为类别标签(字符串或者整数)。
以SCV为例:SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,decision_function_shape=‘ovr’, degree=3, gamma=‘scale’, kernel=‘rbf’,max_iter=-1, probability=False, random_state=None, shrinking=True,tol=0.001, verbose=False)
>>> from sklearn import svm
>>> X = [[0, 0], [1, 1]]
>>> y = [0, 1]
>>> clf = svm.SVC(gamma='scale')
>>> clf.fit(X, y)
>>> clf.predict([[2., 2.]])
(3)获取支持向量特性:SVMs 决策函数取决于训练集的一些子集, 称作支持向量. 这些支持向量的部分特性可以通过 support_vectors_, support_ 和 n_support 获得。
2.2、得分与概率
得分:decision_function,SVC和NuSVC的 decision_function方法: 给出样例在每个类别分值(scores)(或者二分类中每个样例的一个分值)。
概率:probability,当 probability 设置为 True 的时候, 类成员概率评估方法开启。(predict_proba 和 predict_log_proba 方法)。 在二分类中,概率使用 Platt scaling 进行标定:将模型输出转化为基于类别的概率分布, 它是在 SVM 分数上的逻辑回归,在训练集上用额外的交叉验证来训练。
使用建议: 对于大数据集来说,在 Platt scaling 中进行交叉验证是一项昂贵的操作。 另外,概率预测可能与 scores 不一致,因为 scores 的 “argmax” 得到的也许不是概率。 (例如,在二元分类中,一个样本可能通过预测predict被标记某一类,根据predict_proba得到属于该类的概率却小于0.5。.) Platt 的方法也有理论问题. 如果 confidence scores 必要,但是这些没必要是概率, 那么建议设置 probability=False ,并使用 decision_function 而不是 predict_proba。
2.3、非均衡问题
很多问题中,期望给予某一类或某个别样例提高权重(importance),这时可以使用的关键字class_weight 和 sample_weight。
类权重:SVC (而不是 NuSVC) 在 fit 方法中生成了一个关键词 class_weight.。它是形如 {class_label : value} 的字典, value 是大于 0 的浮点数。把参数 C 设置为 C * value即可。
样本权重:SVC, NuSVC, SVR, NuSVR 和 OneClassSVM,在 fit 方法中通过关键词 sample_weight 为个体样例实现进行权重。与 class_weight 相似,把参数 C 换成 C * sample_weight[i]。也就是fit(sample_weight=sample_weight_last_ten)。sample_weight_last_ten为预定义的权重列表。
2.4、数据类型
如果是样本特征值(x)的话是没有限制的,离散、连续的都可以。如果是样本标号值(y)的话,一般是取离散型的,如两类问题一般是{1,-1}。视情况而定,数据是否需要规范化。