机器学习面试SVM常见问题汇总
1. 简单介绍SVM(详细原理)
(回答的思路:从分类平面,到求两类间的最大间隔,到转化为求间隔分之一,等优化问题,然后就是优化问题的解决办法,首先是用拉格拉日乘子把约束优化转化为无约束优化,对各个变量求导令其为零,得到的式子带入拉格朗日式子从而转化为对偶问题, 最后再利用SMO(序列最小优化)来解决这个对偶问题。svm里面的c有啥用)
个人理解:SVM又叫最大间隔分类器,最早用来解决二分类问题。SVM有三宝,间隔, 对偶 ,核技巧。****
1.1间隔:
1.1.1 hard-margin svm (数据完全线性可分)
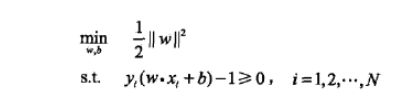
1.1.2 soft-margin svm(数据近似线性可分)
个人理解为 hard-margin svm + loss
loss 损失函数有 :
0-1 损失函数 (函数不连续可导)
合页损失函数 (max( 0, 1 - yi * ( wx + b )))**
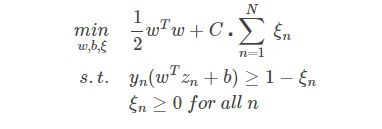
**其中 c为惩罚系数,调节优化方向中两个指标(间隔大小,分类准确度)偏好的权重. C值越大,分类器就越不愿意允许分类错误(“离群点”)。如果C值太大,分类器就会竭尽全力地在训练数据上少犯错误,而实际上这是不可能/没有意义的,于是就造成过拟合。而C值过小时,分类器就会过于“不在乎”分类错误,于是分类性能就会较差。
1.1.3 kernel svm (数据线性不可分)
1.2.对偶:
原来的问题是一个凸优化问题 , 看到凸优化问题一般会想到, 利用拉格朗日乘子法, 将有约束的问题转换为无约束的问题, 在将无约束的原问题转化为对偶问题(注意这里面的KKT条件), 进而利用SMO(序列最小优化)来解决这个对偶问题。
1. 3. 核技巧
核函数的思想在于它事先在低维上进行计算,而将实质上的分类效果表现在了高维上,也就是避免了直接在高维空间的复杂计算。核技巧有助于解决非线性SVM的问题。
1.3.1 常见的核函数有
线性核(Linear核)
多项式核 (Polynomial核)
高斯核(RBF核 / 径向基核
1.3.2 核函数的选取方法
如果特征的数量大到和样本数量差不多,则选用LR或者线性核的SVM;
如果特征的数量小,样本的数量正常,则选用SVM+高斯核函数;
如果特征的数量小,而样本的数量很大,则需要手工添加一些特征从而变成第一种情况
2. SVM的推导
2.1 hardmargin SVM



2.2 soft -margin SVM

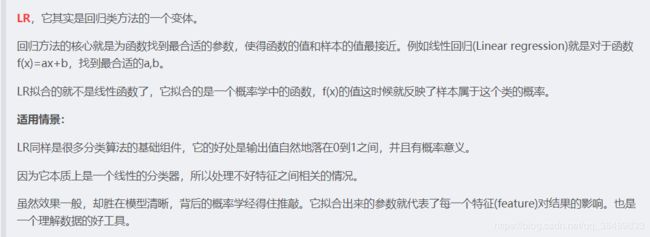
3. SVM与LR区别
1. 损失函数不同 , SVM使用的是Hinge损失函数(max(0, 1 - yi *( w * x + b ))), LR 使用的是交叉熵损失函数(yi* log(h(x)) + ( 1 - yi) * log(1 - h(x)))
2. SVM对异常值不敏感, LR对异常值敏感
3. SVM只考虑觉得边界边界上面的点, 而LR需要考虑所有的点
4. SVM自带结构风险最小化,LR需要加入正则化
5. SVM在解决非线性问题时采用SVM+ Kernel , LR 则没有显性的核函数
4. 为什么要把原问题转换为对偶问题?
- 降低复杂度 , 原问题需要考虑的是样本维度问题, 转化为对偶问题以后变成了考虑样本数量问题。
- 更加高效, 原问题是凸二次规划问题,转换为对偶问题更加高效。因为只需要求解alpha系数,而alpha系数只有支持向量才非0,其他全部为0.
- 方便引入核函数
5.加大训练数据量一定能提高SVM准确率吗?
SVM本质上是凸优化问题,如果增加的样本点只是无效约束,并不会影响其最后的结果
6. 与感知机的联系和优缺点比较
感知机的思想是, 误分类最小策略, 得到的分类平面有无数个。
SVM利用最大间隔的方的思想, 得到的分类平面只有一个, 且该平面是鲁棒的。
7.如何解决多分类问题、可以做回归吗,怎么做?
一对多法。训练时依次把某个类别的样本归为一类,其他剩余的样本归为另一类,这样k个类别的样本就构造出了k个SVM。分类时将未知样本分类为具有最大分类函数值的那类。
一对一法。其做法是在任意两类样本之间设计一个SVM,因此k个类别的样本就需要设计k(k-1)/2个SVM。当对一个未知样本进行分类时,最后得票最多的类别即为该未知样本的类别。Libsvm中的多类分类就是根据这个方法实现的。
层次支持向量机(H-SVMs)。层次分类法首先将所有类别分成两个子类,再将子类进一步划分成两个次级子类,如此循环,直到得到一个单独的类别为止。
SVM不可以做回归, 但是SVR可以做回归。
我们知道,最简单的线性回归模型是要找出一条曲线使得残差最小。同样的,SVR也是要找出一个超平面,使得所有数据到这个超平面的距离最小。
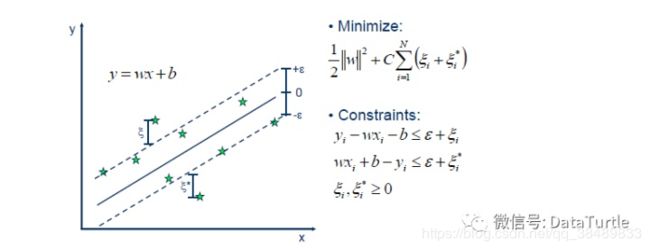 前面说了,SVR是SVM的一种运用,基本的思路是一致,除了一些细微的区别。使用SVR作回归分析,与SVM一样,我们需要找到一个超平面,不同的是:在SVM中我们要找出一个间隔(gap)最大的超平面,而在SVR,我们定义一个ε,如上图所示,定义虚线内区域的数据点的残差为0,而虚线区域外的数据点(支持向量)到虚线的边界的距离为残差(ζ)。与线性模型类似,我们希望这些残差(ζ)最小。所以大致上来说,SVR就是要找出一个最佳的条状区域(2ε宽度),再对区域外的点进行回归。
前面说了,SVR是SVM的一种运用,基本的思路是一致,除了一些细微的区别。使用SVR作回归分析,与SVM一样,我们需要找到一个超平面,不同的是:在SVM中我们要找出一个间隔(gap)最大的超平面,而在SVR,我们定义一个ε,如上图所示,定义虚线内区域的数据点的残差为0,而虚线区域外的数据点(支持向量)到虚线的边界的距离为残差(ζ)。与线性模型类似,我们希望这些残差(ζ)最小。所以大致上来说,SVR就是要找出一个最佳的条状区域(2ε宽度),再对区域外的点进行回归。
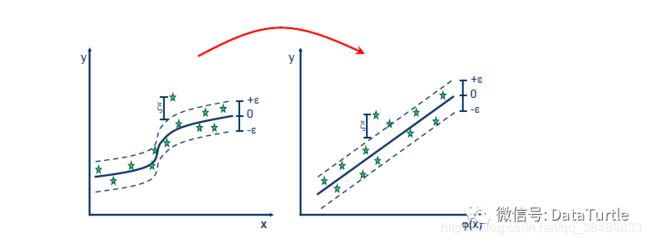 对于非线性的模型,与SVM一样使用核函数(kernel function)映射到特征空间,然后再进行回归。
对于非线性的模型,与SVM一样使用核函数(kernel function)映射到特征空间,然后再进行回归。
8.它与其他分类器对比的优缺点,它的速度?
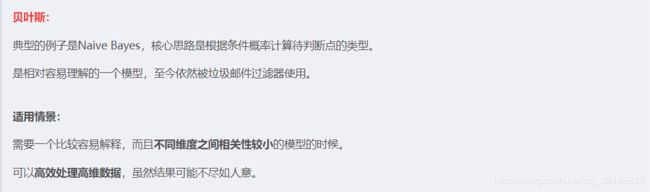
1、贝叶斯分类器
优点: 同时具备接收大数据量训练和查询时具备高速度的特点 具有支持增量式训练的能力(不借助于旧有训练数据,每一组新的训练数据都有可能引起概率值的变化,而如决策树和支持向量机,则需要我们一次性将整个数据集都传给它们。)
对贝叶斯分类器实际学习状况的解释相对简单。 缺点:
无法处理基于特征值组合所产生的变化结果。例如:“在线”和“药店”分开出现时一般出现在正常邮件中,但当组合起来时“在线药店”却一般出现在垃圾邮件中,贝叶斯分类器无法理解这种特征组合。2、决策树分类器
优点: 利用决策树可以很容易的解释一个受训模型,而且算法将最重要的判断因素很好的安排在了靠近树的根部位置。 决策树能找到能使信息增益达到最大化的分界线,因此它能够同时处理分类数据和数值数据。
与贝叶斯分类器相比,它能够很容易地处理变量之间的相互影响。 缺点: 不支持向量式训练,每次训练都要从头开始。3、神经网络
优点: 能够处理复杂的非线性函数,并且能发现不同输入之间的依赖关系。 允许增量式训练 缺点: 神经网络是一种黑盒方法,无法确知推导过程。 在选择训练数据的比率及与问题相适应的网络规模方面,并没有明确的规则可以遵循。
4、支持向量机
优点: 在对新的观测数据进行分类时速度极快,因为支持向量机分类时只需判断坐标点位于分界线的哪一侧即可。 通过将分类输入转换成数值输入,可以令支持向量机同时支持分类数据和数值数据。 缺点:
针对每个数据集的最佳核变换函数及其相应的参数都是不一样的,而且每当遇到新的数据集时都必须重新确定这些函数及参数。 和神经网络一样,SVM也是一种黑盒技术,实际上,由于存在向高维空间的变换,SVM的分类过程甚至更加难于解释。
5、k-最近邻算法
优点:
能够利用复杂函数进行数值预测,同时又保持简单易懂的特点 合理的数据缩放量不但可以改善预测的效果,而且还可以告诉我们预测过程中各个变量的重要程度。
KNN是一种在线(online)技术,这意味着新的数据可以在任何时候被添加进来,而不需要进行任何的计算。 缺点:
为了完成预测,它要求所有的训练数据都必须缺一不可,为了找到最为接近的数据项,每一项待预测的数据必须和其他数据项进行比较,会产出极大的数据计算量。
寻找合理的缩放因子并不是那么简单。SVM的速度
SVM训练速度慢,主要是因为大量的非支持向量参与训练过程,从而进行了大量的二次规划计算,导致分类计算量大、分类速度慢。
9. 支持向量机(SVM)是否适合大规模数据?
我个人支持的答案:
我理解SVM并不是不适合大规模数据,而应该说,SVM在小样本训练集上能够得到比其它算法好很多的结果。支持向量机之所以成为目前最常用,效果最好的分类器之一,在于其优秀的泛化能力,这是是因为其本身的优化目标是结构化风险最小,而不是经验风险最小,因此,通过margin的概念,得到对数据分布的结构化描述,因此减低了对数据规模和数据分布的要求。而大规模数据上,并没有实验和理论证明表明svm会差于其它分类器,也许只是相对其它分类器而言,领先的幅度没有那么高而已。
更多答案参考: (https://www.zhihu.com/question/19591450)
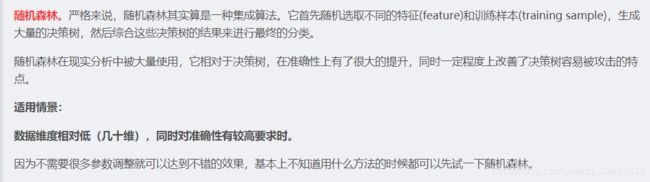
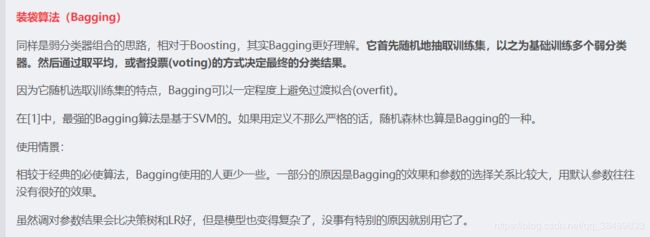
10.各种机器学习的应用场景分别是什么?例如,k近邻,贝叶斯,决策树,svm,逻辑斯蒂回归和最大熵模型。







11.为什么SVM对缺失数据敏感?
这里说的缺失数据是指缺失某些特征数据,向量数据不完整。SVM没有处理缺失值的策略(决策树有)。而SVM希望样本在特征空间中线性可分,所以特征空间的好坏对SVM的性能很重要。缺失特征数据将影响训练结果的好坏。
12. SVM的优缺点:
-
优点:
-
1.SVM可以解决小样本下的机器学习问题, 泛化能力强
2. SVM可以解决高维的特征
3. SVM+ Kernel可以解决非线性问题
4. SVM无需依赖所有样本, 只依赖支持向量 -
缺点:
-
1.SVM对缺失值敏感
2.如果特征维度远大于样本个数, SVM表现一般
3.SVM在样本巨大且使用核函数时计算量很大
13. SVM对噪声敏感的原因?
SVM的基本形态是一个硬间隔分类器,它要求所有样本都满足硬间隔约束(即函数间隔要大于1),所以当数据集有噪声点时,SVM为了把噪声点也划分正确,超平面就会向另外一个类的样本靠拢,这就使得划分超平面的几何间距变小,降低模型的泛化性能。除此之外,当噪声点混入另外一个类时,对于硬间隔分类器而言,这就变成了一个线性不可分的问题,于是就使用核技巧,通过将样本映射到高维特征空间使得样本线性可分,这样得到一个复杂模型,并由此导致过拟合(原样本空间得到的划分超平面会是弯弯曲曲的,它确实可以把所有样本都划分正确,但得到的模型只对训练S集有效)
14. SVM原理详细介绍:
https://zhuanlan.zhihu.com/p/49331510
(个人总结整理,如有错误请提醒更改)
参考资源:
https://zhuanlan.zhihu.com/p/33692660
https://blog.csdn.net/sinat_33231573/article/details/99709784
https://www.zhihu.com/question/19591450/answer/12690826
https://blog.csdn.net/szlcw1/article/details/52259668
https://zhuanlan.zhihu.com/p/58434325