深度学习笔记(十)---RNN时间序列详解
目录
1.摘要(Abstract):
2.网络结构(Method)
2.1 RNN
2.2 RNN的变体
2.2.1 双向RNN
2.2.2 深层双向RNN
2.3 LSTM
2.3.1 LSTM内部结构详解
2.4 GRU
3.实验分析以及代码实现(Experiments)
4.结论(Coclusion)
5. 参考文献
1.摘要(Abstract):
RNN的目的使用来处理序列数据。在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的。但是这种普通的神经网络对于很多问题却无能无力。例如,你要预测句子的下一个单词是什么,一般需要用到前面的单词,因为一个句子中前后单词并不是独立的。RNN之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。理论上,RNN能够对任何长度的序列数据进行处理。
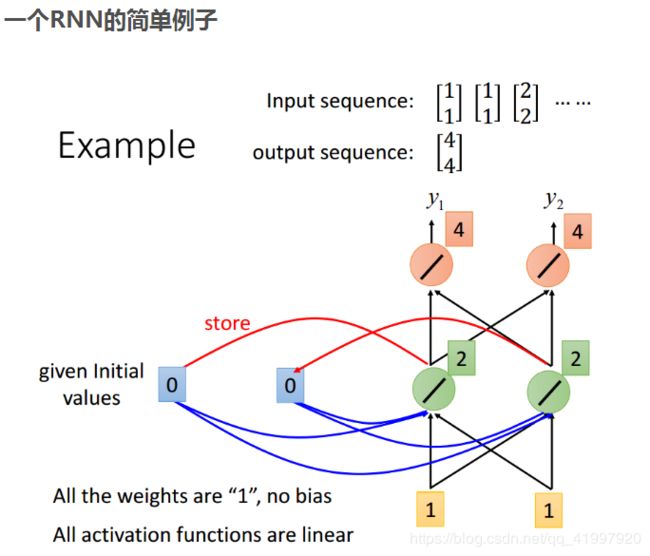
2.网络结构(Method)
2.1 RNN
中文分词、词性标注、命名实体识别、机器翻译、语音识别都属于序列挖掘的范畴。序列挖掘的特点就是某一步的输出不仅依赖于这一步的输入,还依赖于其他步的输入或输出。在序列挖掘领域传统的机器学习方法有HMM(Hidden Markov Model,隐马尔可夫模型)和CRF(Conditional Random Field,条件随机场),近年来又开始流行深度学习算法RNN(Recurrent Neural Networks,循环神经网络)。
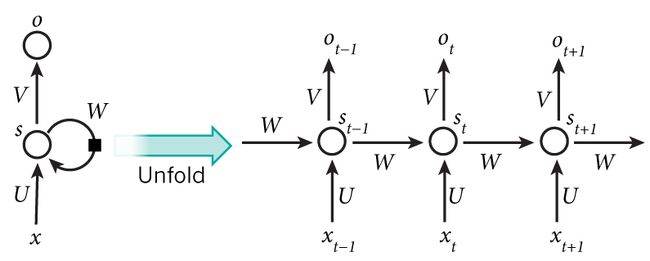
比如一个句子中有5个词,要给这5个词标注词性,那相应的RNN就是个5层的神经网络,每一层的输入是一个词,每一层的输出是这个词的词性。
- xtxt是第t层的输入,它可以是一个词的one-hot向量,也可以是Distributed Representation向量。
- stst是第t层的隐藏状态,它负责整个神经网络的记忆功能。stst由上一层的隐藏状态和本层的输入共同决定,st=f(Uxt+Wst−1)st=f(Uxt+Wst−1),ff通常是个非线性的激活函数,比如tanh或ReLU。由于每一层的stst都会向后一直传递,所以理论上stst能够捕获到前面每一层发生的事情(但实际中太长的依赖很难训练)。
- otot是第t层的输出,比如我们预测下一个词是什么时,otot就是一个长度为VV的向量,VV是所有词的总数,ot[i]ot[i]表示下一个词是wiwi的概率。我们用softmax函数对这些概率进行归一化。ot=softmax(Vst)ot=softmax(Vst)。
- 值得一提的是,每一层的参数U,W,VU,W,V都是共享的,这样极大地缩小了参数空间。
- 每一层并不一定都得有输入和输出,隐藏单元才是RNN的必备武器。比如对句子进行情感分析时只需要最后一层给一个输出即可。
RNN采用传统的backpropagation+梯度下降法对参数进行学习,第tt层的误差函数跟第otot直接相关,而otot依赖于前面每一层的xixi和sisi,i≤ti≤t,这就是所谓的Backpropagation Through Time (BPTT)。在《神经网络调优》中我已讲到过这种深层神经网络容易出现梯度消失或梯度爆炸的问题,为了避免网络太“深”,有些人对RNN进行改造,避免太长的依赖,即otot只依赖于{xi,si}{xi,si},其中t−n≤i≤tt−n≤i≤t。LSTM也属于一种改良的RNN,但它不是强行把依赖链截断,而是采用了一种更巧妙的设计来绕开了梯度消失或梯度爆炸的问题,下文会详细讲解LSTM。
2.2 RNN的变体
2.2.1 双向RNN
双向RNN认为otot不仅依赖于序列之前的元素,也跟tt之后的元素有关,这在序列挖掘中也是很常见的事实。

2.2.2 深层双向RNN
在双向RNN的基础上,每一步由原来的一个隐藏层变成了多个隐藏层。

2.3 LSTM
前文提到,由于梯度消失/梯度爆炸的问题传统RNN在实际中很难处理长期依赖,而LSTM(Long Short Term Memory)则绕开了这些问题依然可以从语料中学习到长期依赖关系。比如“I grew up in France... I speak fluent (French)”要预测()中应该填哪个词时,跟很久之前的"France"有密切关系。
传统RNN每一步的隐藏单元只是执行一个简单的tanh或ReLU操作。
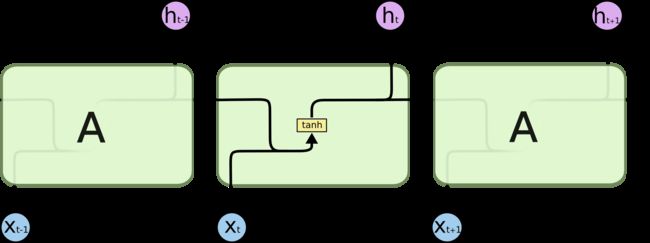
传统RNN每个模块内只是一个简单的tanh层

LSTM每个循环的模块内又有4层结构:3个sigmoid层,1个tanh层
LSTM每个模块的4层结构后文会详细说明,先来解释一下基本的图标。

粉色的圆圈表示一个二目运算。两个箭头汇合成一个箭头表示2个向量首尾相连拼接在一起。一个箭头分叉成2个箭头表示一个数据被复制成2份,分发到不同的地方去。
2.3.1 LSTM内部结构详解
LSTM的关键是细胞状态CC,一条水平线贯穿于图形的上方,这条线上只有些少量的线性操作,信息在上面流传很容易保持。

细胞状态的传送带
第一层是个忘记层,决定细胞状态中丢弃什么信息。把ht−1ht−1和xtxt拼接起来,传给一个sigmoid函数,该函数输出0到1之间的值,这个值乘到细胞状态Ct−1Ct−1上去。sigmoid函数的输出值直接决定了状态信息保留多少。比如当我们要预测下一个词是什么时,细胞状态可能包含当前主语的性别,因此正确的代词可以被选择出来。当我们看到新的主语,我们希望忘记旧的主语。
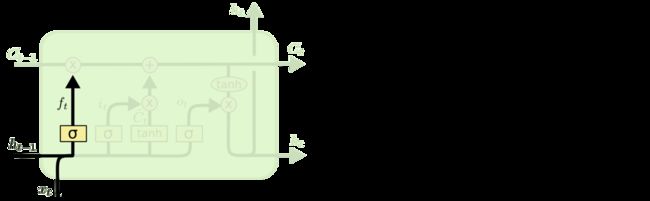
图8 细胞状态忘记一部分,保留一部分
上一步的细胞状态Ct−1Ct−1已经被忘记了一部分,接下来本步应该把哪些信息新加到细胞状态中呢?这里又包含2层:一个tanh层用来产生更新值的候选项C~tC~t,tanh的输出在[-1,1]上,说明细胞状态在某些维度上需要加强,在某些维度上需要减弱;还有一个sigmoid层(输入门层),它的输出值要乘到tanh层的输出上,起到一个缩放的作用,极端情况下sigmoid输出0说明相应维度上的细胞状态不需要更新。在那个预测下一个词的例子中,我们希望增加新的主语的性别到细胞状态中,来替代旧的需要忘记的主语。

图9 更新细胞状态
现在可以让旧的细胞状态Ct−1Ct−1与ftft(f是forget忘记门的意思)相乘来丢弃一部分信息,然后再加个需要更新的部分it∗C~tit∗C~t(i是input输入门的意思),这就生成了新的细胞状态CtCt。
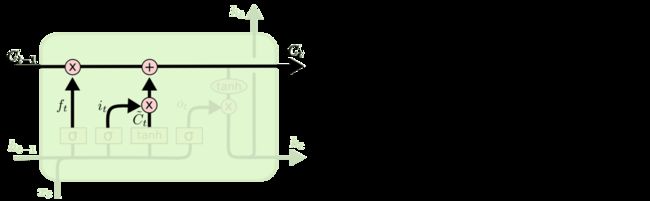
图10 生成新的细胞状态
最后该决定输出什么了。输出值跟细胞状态有关,把CtCt输给一个tanh函数得到输出值的候选项。候选项中的哪些部分最终会被输出由一个sigmoid层来决定。在那个预测下一个词的例子中,如果细胞状态告诉我们当前代词是第三人称,那我们就可以预测下一词可能是一个第三人称的动词。
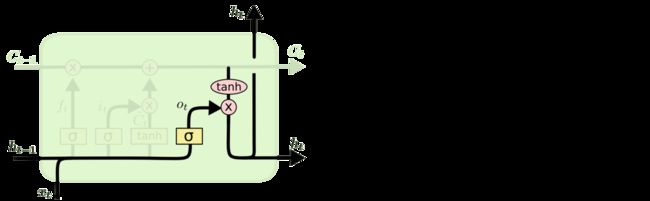
2.4 GRU
GRU(Gated Recurrent Unit)是LSTM最流行的一个变体,比LSTM模型要简单。

3.实验分析以及代码实现(Experiments)
下面就通过pytorch框架对飞机月流量的时间序列的分析,
"""
对于最简单的 RNN,我们可以使用下面两种方式去调用,分别是
torch.nn.RNNCell() 和 torch.nn.RNN(),
这两种方式的区别在于 RNNCell() 只能接受序列中单步的输入,
且必须传入隐藏状态,而 RNN() 可以接受一个序列的输入,
默认会传入全 0 的隐藏状态,也可以自己申明隐藏状态传入。
RNN() 里面的参数有:
input_size 表示输入 ??xt 的特征维度
hidden_size 表示输出的特征维度
num_layers 表示网络的层数
nonlinearity 表示选用的非线性激活函数,默认是 'tanh'
bias 表示是否使用偏置,默认使用
batch_first 表示输入数据的形式,默认是 False,就是这样形式,(seq, batch, feature),也就是将序列长度放在第一位,batch 放在第二位
dropout 表示是否在输出层应用 dropout
bidirectional 表示是否使用双向的 rnn,默认是 False
对于 RNNCell(),里面的参数就少很多,只有 input_size,hidden_size,bias 以及 nonlinearity
LSTM 和基本的 RNN 是一样的,他的参数也是相同的,
同时他也有 nn.LSTMCell() 和 nn.LSTM() 两种形式
"""下面是各部分代码实现,每一步尽量做了详尽的注释。
#数据包的导入
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import os
import csv
import torch
from torch import nn
from torch.autograd import Variable
# 读取csv文件
data_csv = pd.read_csv(u'chapter5_RNN\data.csv' , encoding='utf-8',usecols=[1])
plt.plot(data_csv)
plt.show()
在读取csv文件是常会出现一些报错,可以参考:报错解决方案
我们进行数据集的创建,我们想通过前面几个月的流量来预测当月的流量,比如我们希望通过前两个月的流量来预测当月的流量,我们可以将前两个月的流量当做输入,当月的流量当做输出。同时我们需要将我们的数据集分为训练集和测试集,通过测试集的效果来测试模型的性能,这里我们简单的将前面几年的数据作为训练集,后面两年的数据作为测试集。
# 数据预处理
data_csv = data_csv.dropna() # 滤除缺失数据
dataset = data_csv.values # 获得csv的值
dataset = dataset.astype('float32')
max_value = np.max(dataset) # 获得最大值
min_value = np.min(dataset) # 获得最小值
scalar = max_value - min_value # 获得间隔数量
dataset = list(map(lambda x: x / scalar, dataset)) # 归一化
"""
设置X,Y数据集。以look_back=2为准,取第一个和第二个为数组,形成data_X,
取第三个作为预测值,形成data_Y,完成训练集的提取。
将一列变成两列,第一列是 t 月的乘客数,第二列是 t+1 列的乘客数。
look_back 就是预测下一步所需要的 time steps:
timesteps 就是 LSTM 认为每个输入数据与前多少个陆续输入的数据有联系。
例如具有这样用段序列数据 “…ABCDBCEDF…”,当 timesteps 为 3 时,
在模型预测中如果输入数据为“D”,
那么之前接收的数据如果为“B”和“C”则此时的预测输出为 B 的概率更大,
之前接收的数据如果为“C”和“E”,则此时的预测输出为 F 的概率更大。
"""
def create_dataset(dataset, look_back=2):
dataX, dataY = [], []
for i in range(len(dataset) - look_back):
a = dataset[i:(i + look_back)]
dataX.append(a)
dataY.append(dataset[i + look_back])
return np.array(dataX), np.array(dataY)
# 创建好输入输出
data_X, data_Y = create_dataset(dataset)下面将处理完的数据集进行划分并规范为输入网络所需的维度:
# 划分训练集和测试集,70% 作为训练集
train_size = int(len(data_X) * 0.7)
test_size = len(data_X) - train_size
train_X = data_X[:train_size]
train_Y = data_Y[:train_size]
test_X = data_X[train_size:]
test_Y = data_Y[train_size:]
'''
最后,我们需要将数据改变一下形状,因为 RNN 读入的数据维度是
(seq, batch, feature),所以要重新改变一下数据的维度,这里只有一个序列,
所以 batch 是 1,而输入的 feature 就是我们希望依据的几个月份,这里我们
定的是两个月份,所以 feature 就是 2.
'''
train_X = train_X.reshape(-1, 1, 2)
train_Y = train_Y.reshape(-1, 1, 1)
test_X = test_X.reshape(-1, 1, 2)
train_x = torch.from_numpy(train_X)
train_y = torch.from_numpy(train_Y)
test_x = torch.from_numpy(test_X)下面定义模型:
# 定义模型
class lstm_reg(nn.Module):
def __init__(self, input_size, hidden_size, output_size=1, num_layers=2):
super(lstm_reg, self).__init__()
self.rnn = nn.LSTM(input_size, hidden_size, num_layers) # rnn
self.reg = nn.Linear(hidden_size, output_size) # 回归
def forward(self, x):
x, _ = self.rnn(x) # (seq, batch, hidden)
s, b, h = x.shape
x = x.view(s*b, h) # 转换成线性层的输入格式
x = self.reg(x)
x = x.view(s, b, -1)
return x
#定义好网络结构,输入的维度是 2,因为我们使用两个月的流量作为输入,
#隐藏层的维度可以任意指定,这里我们选的 4
net = lstm_reg(2, 4)
优化器以及loss函数的选择:
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(net.parameters(), lr=1e-2)现在开始训练模型:
# 开始训练
for e in range(1000):
var_x = Variable(train_x)
var_y = Variable(train_y)
# 前向传播
out = net(var_x)
loss = criterion(out, var_y)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (e + 1) % 100 == 0: # 每 100 次输出结果
print('Epoch: {}, Loss: {:.5f}'.format(e + 1, loss.item()))利用划分的测试集进行测试,测试钱依然需要将测试集的形状重塑。
net = net.eval() # 转换成测试模式
data_X = data_X.reshape(-1, 1, 2)
data_X = torch.from_numpy(data_X)
var_data = Variable(data_X)
pred_test = net(var_data) # 测试集的预测结果
# 改变输出的格式
pred_test = pred_test.view(-1).data.numpy()
# 画出实际结果和预测的结果
plt.plot(pred_test, 'r', label='prediction')
plt.plot(dataset, 'b', label='real')
plt.legend(loc='best')
plt.show()4.结论(Coclusion)
模型最后运行结果,从图可以看到使用 lstm 能够得到比较相近的结果,预测的趋势也与真实的数据集是相同的,因为其能够记忆之前的信息,而单纯的使用线性回归并不能得到较好的结果,从这个例子也说明了 RNN 对于序列有着非常好的性能。
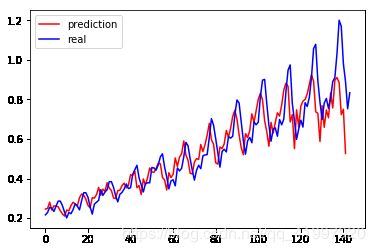
我们还可以改变输入月份,改变look_back参数的大小,进行实验看是否会得到更好的效果。注意模型输入的数据的重塑tensor的大小需要注意,否者会报错。可以尝试用jupyter notebook将数据的shape打印出,看看每一步到底进行怎样的数据变换。这点非常重要,当我们拿到一些data时,如何利用这些杂乱的data,是我们需要学习并掌握的。
5. 参考文献