3D Human Pose Estimation from Monocular Images with Deep Convolutional Neural Network(2014)
Deep network for 3D pose estimation(2014)
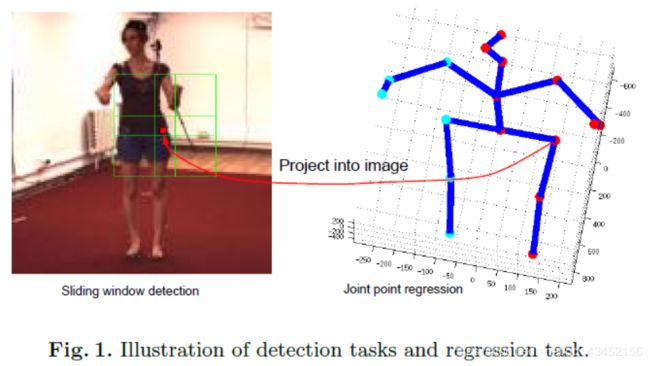
本文提出两种策略去训练deep convolutional neural network以进行3D pose estimation。网络框架包含两个任务:(1)a joint point regression task;(2)joint point detection tasks。两个任务的输入都是包含human subjects的bounding box图片。回归任务是估计关节点相对于根关节点的位置。We define a set of detection tasks,each of which is associated with one joint point and one local window.The aim of each detection task is to clssify whether one local window contains the specific joint or not.
###1. Notation
J i = ( J i , x , j i , y , J i , z ) J_i=(J_{i,x},j_{i,y},J_{i,z}) Ji=(Ji,x,ji,y,Ji,z)——the location of the i-th joint in the camera coordinate system.
P——人体的结构化骨骼模型,即关节之间的父子关系。
P(i)——the parent joint of the i-th joint.
根关节的父关节是本身。
2. Joint point regression task
目标:关节点相对于父关节的位置
R i = J i − J P ( i ) ( 1 ) R_i=J_i-J_{P(i)}\space (1) Ri=Ji−JP(i) (1)
—— R i 和 R i ^ 分 别 是 i − t h 个 关 节 点 的 g r o u n d − t r u t h 和 估 计 的 相 对 位 置 R_i和\hat{R_i}分别是i-th个关节点的ground-truth和估计的相对位置 Ri和Ri^分别是i−th个关节点的ground−truth和估计的相对位置
原因:
(1)父子关节点之间的相对位置关系更容易获取
(2)由于人体的对称性,不同关节点之间可以分享信息;如左臂和右臂有相同的长度
(3)在给定对称部分的前提下,易于推断出遮挡关节点的位置
损失函数:
E r ( R i , R i ^ ) = ∣ ∣ R i − R i ^ ∣ ∣ 2 2 ( 2 ) E_r(R_i,\hat{R_i})={||R_i-\hat{R_i}||_2^2}\space(2) Er(Ri,Ri^)=∣∣Ri−Ri^∣∣22 (2)
—— R i 和 R i ^ 分 别 是 i − t h 个 关 节 点 的 g r o u n d − t r u t h 和 估 计 的 相 对 位 置 R_i和\hat{R_i}分别是i-th个关节点的ground-truth和估计的相对位置 Ri和Ri^分别是i−th个关节点的ground−truth和估计的相对位置
3. Joint point detection task
Inspired by[25],we define a set of detection tasks for each joint i and each window l,where the goal is to predict the indicator variable
h i , l = { 1 , i f B i i s i n s i d e w i n d o w s l , 0 , o t h e r w i s e , ( 3 ) h_{i,l}= \begin{cases} 1,if B_i \space is \space inside\space windows\space l,\\ 0,otherwise, \end{cases} (3) hi,l={1,ifBi is inside windows l,0,otherwise,(3)
—— B i 是 输 入 b o u n d i n g b o x 中 i − t h 的 关 节 点 的 2 D 图 片 位 置 B_i是输入bounding box中i-th的关节点的2D图片位置 Bi是输入boundingbox中i−th的关节点的2D图片位置
B i B_i Bi可以通过将 J i J_i Ji映射到图片,计算与与bounding box的相对位置而得到。In this work, we do not consider whether the joints are visible or not, i.e., the indicator variables are calculated regardless if the joint is occluded. The reason for doing this is to train the network to learn features for pose estimation even in the presence of occlusions, which might enable the network to predict valid poses when occlusion occur.
损失函数:
E d ( h ^ i , l , h i , l ) = − h i , l l o g ( h ^ i , l ) − ( 1 − h i , l ) l o g ( 1 − h ^ i , l ) ( 4 ) E_d(\hat{h}_{i,l},h_{i,l})=-h_{i,l}log(\hat{h}_{i,l})-(1-h_{i,l})log(1-\hat{h}_{i,l})\space (4) Ed(h^i,l,hi,l)=−hi,llog(h^i,l)−(1−hi,l)log(1−h^i,l) (4)
——最小化ground-truth label h i , l h_{i,l} hi,l和estimated label h ^ i , l \hat h_{i,l} h^i,l的cross-entropy
The relationship between the regrssion tasks and detection tasks is illustrated in Figure 1
4. Network architecture and multi-task training
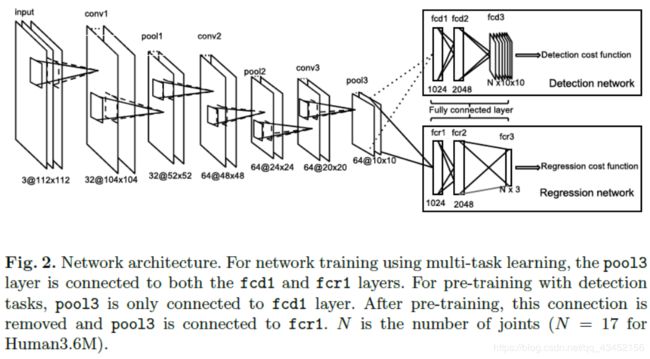
The whole network consists of 9 trainable layers - 3 convolutional layers that are shared by both regression and detecton networks, 3 fully connected layers for the regression network, and 3 fully connected layers for th detection networks.Rectified linear units(ReLu)[30] are used for conv1, conv2, and the first two fully connected layers for both regression and detection networks. We use tanh as the activation function for the last regression normalization layers after conv2,which applies the following function to calculate the output values,
f ( u x , y ) = u x , y ( 1 + α ∣ W x ∣ ⋅ ∣ W y ∣ ∑ x ′ ∈ W x ∑ y ′ ∈ W y u x ′ , y ′ 2 ) β ( 5 ) f(u_{x,y})=\frac{u_{x,y}}{(1+\frac{\alpha}{|W_x|\cdot|W_y|}\sum_{x'\in W_x}\sum_{y'\in W_y}{u_{x',y'}^2})^\beta}\space (5) f(ux,y)=(1+∣Wx∣⋅∣Wy∣α∑x′∈Wx∑y′∈Wyux′,y′2)βux,y (5)
—— u x , y u_{x,y} ux,yis the value of the previous layer at location ( x , y ) (x,y) (x,y), ( W x , W y ) (W_x,W_y) (Wx,Wy)are the neighborhood of locations ( x , y ) (x,y) (x,y), ∣ W ∣ |W| ∣W∣represents th number of pixels within the neighborhood,and{ α , β \alpha,\beta α,β}are hyper-parameters.
We train the network within a multi-task learning framework. As in [25], we allow features in the lower layers to be shared between the regression and detection tasks during joint training. During the training, the gradients from both networks will be back-propagated to the same shared feature network, i.e., the network with layers from conv1 to pool3. In this case, the shared network tends to learn features that will benefit both tasks. The global cost function for multi-task training is
ϕ M = 1 2 ∑ t = 1 T ∑ i = 1 N E r ( R i ( t ) , R ^ i t ) + 1 2 ∑ t = 1 T ∑ i = 1 N ∑ l = 1 L E d ( h i , l ( t ) , h ^ i , l ( t ) ) ( 6 ) \phi_M=\frac{1}{2}\sum_{t=1}^{T}\sum_{i=1}^NE_r(R_i^{(t)},\hat R_i^{t})+\frac{1}{2}\sum_{t=1}^{T}\sum_{i=1}^{N}\sum_{l=1}^{L}E_d(h_{i,l}^{(t)},\hat h_{i,l}^{(t)})\space(6) ϕM=21t=1∑Ti=1∑NEr(Ri(t),R^it)+21t=1∑Ti=1∑Nl=1∑LEd(hi,l(t),h^i,l(t)) (6)
——上标 t t t是训练样本的索引, N N N是关节点的数目, T T T是训练样本总数
5.Pre-training with the detction task
As an alternative to the multi-task training discussed earlier, another approach is to train the pose regression network using pre-trained weights from the detection network. Firstly we train the detection network alone, i.e., the connections between the pool3 layer and the fcr1 layer are blocked. In this stage, we only minimize the second term in (6). After training the detection tasks, we block the connection between pool3 and fcd1 (thus removing the detection task), and reconnect pool3 to fcr1 layer. Using this strategy, the training for pose regression is initialized using the feature layer weights (conv1-conv3) learned from the detection tasks. Finally, the pose regression is trained using the first term in (6) as the cost function. Note that we do not use the weights of the fully-connected layers of the detectors (fcd1 and fcd2) to initialize fully-connected layers of the regression task (fcr1 and fcr2). The reason is that the target for the detection and regression tasks are quite different, so that the higher-level features used by the detection tasks might not be useful for regression.
6.Training details
For both the multi-task and pre-training approaches, we use back propagation [31] to update the weights during training. In multi-task training, the pool3 layer forwards its values to both fcd1 and fcr1, and receives the average of the gradients from fcd1 and fcr1 when updating the weights. To reduce overfitting, we use “dropout” [32] in fcr1 and fcd1, and set the dropout rate to 0.25. The hyper-parameters for the local response normalization layer are set to α \alpha α = 0.0025 and β \beta β = 0.75. More training details can be found in [13].
Experiment
Data augmentation
After obtaining the bounding box of the human subject (provided by the Human3.6M dataset), we resize the bounding box to 128⇥128, such that the aspect ratio of the image is maintained. In order to make the network robust to the selection of the bounding box, in each iteration, a sub-window of size 112⇥112 is randomly selected as the training image (the 2D joint point projections are also adjusted accordingly). Random pixel noise is also added to each input image during training to make the network robust to small perturbations of pixel values. As in [13] we apply PCA on the RGB channels over the whole training samples. In the training stage, we add random noise to all the pixels in each image,
p ^ = p + [ e 1 , e 2 , e 3 ] ⋅ [ g 1 α 1 , g 2 α 2 , g 3 α 3 ] T , ( 7 ) \hat p = p+[e_1,e_2,e_3]\cdot [g_1\sqrt\alpha_1,g_2\sqrt\alpha_2,g_3\sqrt\alpha_3]^T,\space (7) p^=p+[e1,e2,e3]⋅[g1α1,g2α2,g3α3]T, (7)
—— [ e 1 , e 2 , e 3 ] [e_1,e_2,e_3] [e1,e2,e3]and [ α 1 , α 2 , α 3 ] [\alpha_1,\alpha_2,\alpha_3] [α1,α2,α3]are the eigenvectors and eigenvalues of the 3 × 3 3× 3 3×3RGB covariance matrix of the triaining set,and { g c } c = 1 3 \{g_c\}_{c=1}^3 {gc}c=13 are each Gaussian distributions with zero mean and variance 0.1.In each iteration,all the pixels within one training sample will share the same random values { g c } c = 1 3 \{g_c\}_{c=1}^3 {gc}c=13.
Evaluation on Human36M
详见原文
Pose predictions are evaluated using the mean per joint position error(MPJPE)[12],
M P J P E = 1 T 1 N ∑ t = 1 T ∑ i = 1 N ∣ ∣ ( J i ( t ) − J r o o t ( t ) ) − ( J ^ i ( t ) − J ^ r o o t ( t ) ) ∣ ∣ , ( 8 ) MPJPE=\frac{1}{T}\frac{1}{N}\sum_{t=1}^T\sum_{i=1}^N||(J_i^{(t)}-J_root^{(t)})-(\hat J_i^{(t)}-\hat J_root^{(t)})||,\space (8) MPJPE=T1N1t=1∑Ti=1∑N∣∣(Ji(t)−Jroot(t))−(J^i(t)−J^root(t))∣∣, (8)
Visualization of learned structures
详见原文
Conclusion
(1)采用多任务训练框架:检测和回归
(2)共享低层特征(共享权值)
(3)探讨了DNN如何编码人体结构的依赖性与相关性