Python 线性回归分析之岭回归
当使用最小二乘法计算线性回归模型参数的时候,如果数据集合矩阵存在多重共线性(数学上称为病态矩阵),那么最小二乘法对输入变量中的噪声非常的敏感,如果输入变量x有一个微小的变动,其反应在输出结果上也会变得非常大,其解会极为不稳定。为了解决这个问题,就有了优化算法 岭回归(Ridge Regression )。
多重共线性
在介绍岭回归之前时,先了解一下多重共线性。
在线性回归模型当中,我们假设每个样本中每个变量之间是相互独立的
就是说下面的公式中,
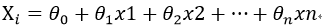
x1,x2,.....,xn中的某几个变量之间存在相关性,或者用矩阵的形式表示的话,矩阵中的某一列可以用其他的列,或其他的某几个列来表示,那么就认为存在共线性。

岭回归
在线性回归问题求解过程中,如果存在共线性,那么求解的参数结果其方差和标准差变大,进而导致用此参数进行预测时,预测结果产生很大的偏离。
那么如何克服这个问题呢?
一般,解决多重共线性可以采用如下的一些方法:
1、排除引起共线性的变量(逐步回归法)
2、差分法
3、减小参数估计量的方差(例如增加样本容量);
4、变量变换(例如可以把相关的两个变量合并到一起);
5、利用先验信息做约束(例如增加惩罚项)。
在线性回归问题中,如果在回归模型后面增加L2范数的惩罚项,则为岭回归,如果增加L1范数的惩罚项,则为套索回归。
本文只写岭回归,其模型为(最小二乘法):

这里增加的是对求解参数的惩罚项约束,很显然,当a取很大的值时,惩罚项的作用就很明显了,因为,惩罚项必须足够小,那么就达到目的了。
岭回归(Ridge Regression)
所谓岭回归,就是对于一个线性模型,在原来的损失函数加入参数的 范数的惩罚项,其损失函数为如下形式:
范数的惩罚项,其损失函数为如下形式:
![]()
这里α是平法损失和正则项之间的一个系数,α≥0。
α的数值越大,那么正则项,也是惩罚项的作用就越明显;α的数值越小,正则项的作用就越弱。极端情况下,α=0则和原来的损失函数是一样的,如果α=∞,则损失函数只有正则项,此时其最小化的结果必然是w=0。
关于alpha的数值具体的选择,归于“模型选择”章节,具体的方法可以参见“模型选择”。
其实,这个式子和拉格朗日乘子法的结果差不多,如果逆用拉格朗日乘子法的话,那么,上面的损失函数可以是下面的这种优化模型:

在《线性回归》中,给出了线性回归的损失函数可以写为:
![]()
关于参数w求导之后:
![]()
其解为:
![]()
这里,岭回归的损失函数为:
![]()
关于参数w求导之后:
![]()
其解为:
![]()
下面给出一个岭回归简单的代码示例,这个代码显示了不同的alpha对模型参数w的影响程度。alpha越大,则w的数值上越小;alpha越小,则w的数值上越大,注意所生成的图片为了更好的观察,将x轴做了反转。
#!/usr/bin/python
# -*- coding: utf-8 -*-
"""
author : [email protected]
time : 2016-06-03-14-34
岭回归测试代码
这里需要先生成一个线性相关的设计矩阵X,再使用岭回归对其进行建模
岭回归中最重要的就是参数alpha的选择,本例显示了不同的alpha下
模型参数omega不同的结果
"""
print(__doc__)
import numpy as np
import matplotlib.pyplot as plt
from sklearn import linear_model
# 这里设计矩阵X是一个希尔伯特矩阵(Hilbert matrix)
# 其元素A(i,j)=1(i + j -1),i和j分别为其行标和列标
# 希尔伯特矩阵是一种数学变换矩阵,正定,且高度病态
# 即,任何一个元素发生一点变动,整个矩阵的行列式的值和逆矩阵都会发生巨大变化
# 这里设计矩阵是一个10x5的矩阵,即有10个样本,5个变量
X = 1. / (np.arange(1, 6) + np.arange(0, 10)[:, np.newaxis])
y = np.ones(10)
print '设计矩阵为:'
print X
# alpha 取值为10^(-10)到10^(-2)之间的连续的200个值
n_alphas = 200
alphas = np.logspace(-10, -2, n_alphas)
print '\n alpha的值为:'
print alphas
# 初始化一个Ridge Regression
clf = linear_model.Ridge(fit_intercept=False)
# 参数矩阵,即每一个alpha对于的参数所组成的矩阵
coefs = []
# 根据不同的alpha训练出不同的模型参数
for a in alphas:
clf.set_params(alpha=a)
clf.fit(X, y)
coefs.append(clf.coef_)
# 获得绘图句柄
ax = plt.gca()
# 参数中每一个维度使用一个颜色表示
ax.set_color_cycle(['b', 'r', 'g', 'c', 'k'])
# 绘制alpha和对应的参数之间的关系图
ax.plot(alphas, coefs)
ax.set_xscale('log') #x轴使用对数表示
ax.set_xlim(ax.get_xlim()[::-1]) # 将x轴反转,便于显示
plt.grid()
plt.xlabel('alpha')
plt.ylabel('weights')
plt.title('Ridge coefficients as a function of the regularization')
plt.axis('tight')
plt.show()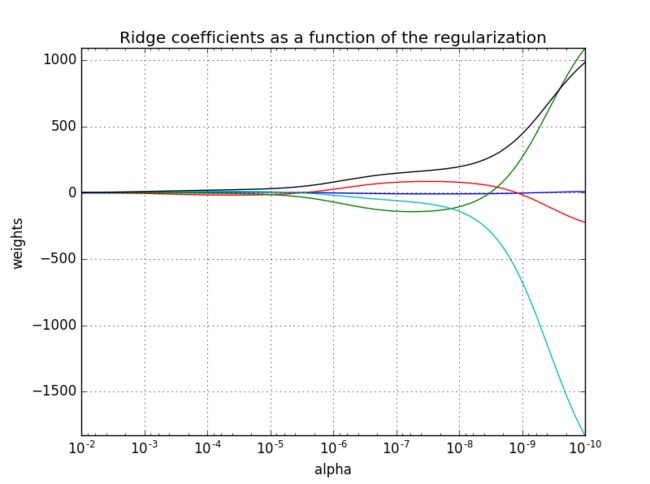
基于交叉验证的岭回归
在前面提到过,岭回归中,alpha的选择是一个比较麻烦的问题,这其实是一个模型选择的问题,在模型选择中,最简单的模型选择方法就是交叉验证(Cross-validation),将交叉验证内置在脊回归中,就免去了alpha的人工选择,其具体实现方式如下:
#!/usr/bin/python
# -*- coding: utf-8 -*-
"""
author : [email protected]
time : 2016-06-19-20-59
基于交叉验证的岭回归alpha选择
可以直接获得一个相对不错的alpha
"""
print(__doc__)
import numpy as np
import matplotlib.pyplot as plt
from sklearn import linear_model
# 这里设计矩阵X是一个希尔伯特矩阵(Hilbert matrix)
# 其元素A(i,j)=1(i + j -1),i和j分别为其行标和列标
# 希尔伯特矩阵是一种数学变换矩阵,正定,且高度病态
# 即,任何一个元素发生一点变动,整个矩阵的行列式的值和逆矩阵都会发生巨大变化
# 这里设计矩阵是一个10x5的矩阵,即有10个样本,5个变量
X = 1. / (np.arange(1, 6) + np.arange(0, 10)[:, np.newaxis])
y = np.ones(10)
print '设计矩阵为:'
print X
# 初始化一个Ridge Cross-Validation Regression
clf = linear_model.RidgeCV(fit_intercept=False)
# 训练模型
clf.fit(X, y)
print
print 'alpha的数值 : ', clf.alpha_
print '参数的数值:', clf.coef_
其运行结果如下:
设计矩阵为:
[[ 1. 0.5 0.33333333 0.25 0.2 ]
[ 0.5 0.33333333 0.25 0.2 0.16666667]
[ 0.33333333 0.25 0.2 0.16666667 0.14285714]
[ 0.25 0.2 0.16666667 0.14285714 0.125 ]
[ 0.2 0.16666667 0.14285714 0.125 0.11111111]
[ 0.16666667 0.14285714 0.125 0.11111111 0.1 ]
[ 0.14285714 0.125 0.11111111 0.1 0.09090909]
[ 0.125 0.11111111 0.1 0.09090909 0.08333333]
[ 0.11111111 0.1 0.09090909 0.08333333 0.07692308]
[ 0.1 0.09090909 0.08333333 0.07692308 0.07142857]]
alpha的数值 : 0.1
参数的数值: [-0.43816548 1.19229228 1.54118834 1.60855632 1.58565451]