第61课:SparkSQl数据加载和保存内幕深度解密实战学习笔记
第61课:SparkSQl数据加载和保存内幕深度解密实战学习笔记
本期内容:
1 SparkSQL加载数据
2 SparkSQL保存数据
3 SparkSQL对数据处理的思考
操作SparkSQL主要就是操作DataFrame,DataFrame提供了一些通用的LOAD、SAVE操作,
Spark版本:
大版本:主要是API变化的分支
版本:增加的特性
小版本:BUGS FIX版本
/**
* Returns the dataset stored at path as a DataFrame,
* using the default data source configured by spark.sql.sources.default.
*
* @group genericdata
* @deprecated As of 1.4.0, replaced by `read().load(path)`. This will be removed in Spark 2.0.
*/
@deprecated("Use read.load(path). This will be removed in Spark 2.0.", "1.4.0")
def load(path: String): DataFrame = {
read.load(path)
}
DataFrameReader:
* :: Experimental ::
* Interface used to load a [[DataFrame]] from external storage systems (e.g. file systems,
* key-value stores, etc). Use [[SQLContext.read]] to access this.
DataFrameReader中有format方法:
/**
* Specifies the input data source format.
*
* @since 1.4.0
*/
def format(source: String): DataFrameReader = {
this.source = source
this
}
读取数据时可以直接指定读取数据的文件类型,如JSON或Parquet。
/**
* Specifies the input schema. Some data sources (e.g. JSON) can infer the input schema
* automatically from data. By specifying the schema here, the underlying data source can
* skip the schema inference step, and thus speed up data loading.
*
* @since 1.4.0
*/
def schema(schema: StructType): DataFrameReader = {
this.userSpecifiedSchema = Option(schema)
this
}
/**
* Loads input in as a [[DataFrame]], for data sources that require a path (e.g. data backed by
* a local or distributed file system).
*
* @since 1.4.0
*/
// TODO: Remove this one in Spark 2.0.
def load(path: String): DataFrame = {
option("path", path).load()
}
/**
* Loads input in as a [[DataFrame]], for data sources that don't require a path (e.g. external
* key-value stores).
*
* @since 1.4.0
*/
def load(): DataFrame = {
val resolved = ResolvedDataSource(
sqlContext,
userSpecifiedSchema = userSpecifiedSchema,
partitionColumns = Array.empty[String],
provider = source,
options = extraOptions.toMap)
DataFrame(sqlContext, LogicalRelation(resolved.relation))
}
SparkSQL可以读取mysql数据库中的数据。
object ResolvedDataSource extends Logging {
/** A map to maintain backward compatibility in case we move data sources around. */
private val backwardCompatibilityMap = Map(
"org.apache.spark.sql.jdbc" -> classOf[jdbc.DefaultSource].getCanonicalName,
"org.apache.spark.sql.jdbc.DefaultSource" -> classOf[jdbc.DefaultSource].getCanonicalName,
"org.apache.spark.sql.json" -> classOf[json.DefaultSource].getCanonicalName,
"org.apache.spark.sql.json.DefaultSource" -> classOf[json.DefaultSource].getCanonicalName,
"org.apache.spark.sql.parquet" -> classOf[parquet.DefaultSource].getCanonicalName,
"org.apache.spark.sql.parquet.DefaultSource" -> classOf[parquet.DefaultSource].getCanonicalName
)
下面编写代码实战SparkSQL的数据加载和保存:
package SparkSQLByJava;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.DataFrame;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.SaveMode;
public class SparkSQLLoadSaveOps {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local").setAppName("RDD2DataFrameByProgrammatically");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
DataFrame peopleDF = sqlContext.read().format("json").load("D:\\DT-IMF\\testdata\\people.json");
peopleDF.select("name").write().mode(SaveMode.Append).save("D:\\DT-IMF\\testdata\\usersNames");
}
}
注意,这里的输出路径D:\\DT-IMF\\testdata\\usersNames不能存在,程序运行时会自动创建,否则会报错。
在eclipse中运行的console显示如下:
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
16/03/31 23:16:25 INFO SparkContext: Running Spark version 1.6.0
16/03/31 23:16:31 INFO SecurityManager: Changing view acls to: think
16/03/31 23:16:31 INFO SecurityManager: Changing modify acls to: think
16/03/31 23:16:31 INFO SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(think); users with modify permissions: Set(think)
16/03/31 23:16:35 INFO Utils: Successfully started service 'sparkDriver' on port 53575.
16/03/31 23:16:38 INFO Slf4jLogger: Slf4jLogger started
16/03/31 23:16:39 INFO Remoting: Starting remoting
16/03/31 23:16:41 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://[email protected]:53588]
16/03/31 23:16:41 INFO Utils: Successfully started service 'sparkDriverActorSystem' on port 53588.
16/03/31 23:16:41 INFO SparkEnv: Registering MapOutputTracker
16/03/31 23:16:41 INFO SparkEnv: Registering BlockManagerMaster
16/03/31 23:16:42 INFO DiskBlockManager: Created local directory at C:\Users\think\AppData\Local\Temp\blockmgr-20b3e769-f5e1-460b-afc7-4da0864bc453
16/03/31 23:16:42 INFO MemoryStore: MemoryStore started with capacity 1773.8 MB
16/03/31 23:16:43 INFO SparkEnv: Registering OutputCommitCoordinator
16/03/31 23:16:45 INFO Utils: Successfully started service 'SparkUI' on port 4040.
16/03/31 23:16:45 INFO SparkUI: Started SparkUI at http://192.168.56.1:4040
16/03/31 23:16:46 INFO Executor: Starting executor ID driver on host localhost
16/03/31 23:16:46 INFO Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 53595.
16/03/31 23:16:46 INFO NettyBlockTransferService: Server created on 53595
16/03/31 23:16:46 INFO BlockManagerMaster: Trying to register BlockManager
16/03/31 23:16:46 INFO BlockManagerMasterEndpoint: Registering block manager localhost:53595 with 1773.8 MB RAM, BlockManagerId(driver, localhost, 53595)
16/03/31 23:16:46 INFO BlockManagerMaster: Registered BlockManager
16/03/31 23:16:51 WARN : Your hostname, think-PC resolves to a loopback/non-reachable address: fe80:0:0:0:d401:a5b5:2103:6d13%eth8, but we couldn't find any external IP address!
16/03/31 23:16:53 INFO JSONRelation: Listing file:/D:/DT-IMF/testdata/people.json on driver
16/03/31 23:16:56 INFO MemoryStore: Block broadcast_0 stored as values in memory (estimated size 208.9 KB, free 208.9 KB)
16/03/31 23:16:56 INFO MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 19.4 KB, free 228.3 KB)
16/03/31 23:16:56 INFO BlockManagerInfo: Added broadcast_0_piece0 in memory on localhost:53595 (size: 19.4 KB, free: 1773.7 MB)
16/03/31 23:16:56 INFO SparkContext: Created broadcast 0 from load at SparkSQLLoadSaveOps.java:12
16/03/31 23:16:57 INFO FileInputFormat: Total input paths to process : 1
16/03/31 23:16:58 INFO SparkContext: Starting job: load at SparkSQLLoadSaveOps.java:12
16/03/31 23:16:58 INFO DAGScheduler: Got job 0 (load at SparkSQLLoadSaveOps.java:12) with 1 output partitions
16/03/31 23:16:58 INFO DAGScheduler: Final stage: ResultStage 0 (load at SparkSQLLoadSaveOps.java:12)
16/03/31 23:16:58 INFO DAGScheduler: Parents of final stage: List()
16/03/31 23:16:58 INFO DAGScheduler: Missing parents: List()
16/03/31 23:16:58 INFO DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[3] at load at SparkSQLLoadSaveOps.java:12), which has no missing parents
16/03/31 23:16:58 INFO MemoryStore: Block broadcast_1 stored as values in memory (estimated size 4.3 KB, free 232.7 KB)
16/03/31 23:16:58 INFO MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 2.4 KB, free 235.1 KB)
16/03/31 23:16:58 INFO BlockManagerInfo: Added broadcast_1_piece0 in memory on localhost:53595 (size: 2.4 KB, free: 1773.7 MB)
16/03/31 23:16:58 INFO SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:1006
16/03/31 23:16:58 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 0 (MapPartitionsRDD[3] at load at SparkSQLLoadSaveOps.java:12)
16/03/31 23:16:58 INFO TaskSchedulerImpl: Adding task set 0.0 with 1 tasks
16/03/31 23:16:58 INFO TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, partition 0,PROCESS_LOCAL, 2138 bytes)
16/03/31 23:16:59 INFO Executor: Running task 0.0 in stage 0.0 (TID 0)
16/03/31 23:16:59 INFO HadoopRDD: Input split: file:/D:/DT-IMF/testdata/people.json:0+73
16/03/31 23:16:59 INFO deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id
16/03/31 23:16:59 INFO deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id
16/03/31 23:16:59 INFO deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap
16/03/31 23:16:59 INFO deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition
16/03/31 23:16:59 INFO deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id
16/03/31 23:17:04 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 2845 bytes result sent to driver
16/03/31 23:17:04 INFO TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 5730 ms on localhost (1/1)
16/03/31 23:17:04 INFO TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
16/03/31 23:17:04 INFO DAGScheduler: ResultStage 0 (load at SparkSQLLoadSaveOps.java:12) finished in 5.950 s
16/03/31 23:17:04 INFO DAGScheduler: Job 0 finished: load at SparkSQLLoadSaveOps.java:12, took 6.508684 s
16/03/31 23:17:06 INFO MemoryStore: Block broadcast_2 stored as values in memory (estimated size 61.8 KB, free 296.9 KB)
16/03/31 23:17:07 INFO MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 19.3 KB, free 316.2 KB)
16/03/31 23:17:07 INFO BlockManagerInfo: Added broadcast_2_piece0 in memory on localhost:53595 (size: 19.3 KB, free: 1773.7 MB)
16/03/31 23:17:07 INFO SparkContext: Created broadcast 2 from save at SparkSQLLoadSaveOps.java:13
16/03/31 23:17:07 INFO MemoryStore: Block broadcast_3 stored as values in memory (estimated size 208.9 KB, free 525.1 KB)
16/03/31 23:17:07 INFO MemoryStore: Block broadcast_3_piece0 stored as bytes in memory (estimated size 19.4 KB, free 544.5 KB)
16/03/31 23:17:07 INFO BlockManagerInfo: Added broadcast_3_piece0 in memory on localhost:53595 (size: 19.4 KB, free: 1773.7 MB)
16/03/31 23:17:07 INFO SparkContext: Created broadcast 3 from save at SparkSQLLoadSaveOps.java:13
16/03/31 23:17:07 INFO ParquetRelation: Using default output committer for Parquet: org.apache.parquet.hadoop.ParquetOutputCommitter
16/03/31 23:17:08 INFO DefaultWriterContainer: Using user defined output committer class org.apache.parquet.hadoop.ParquetOutputCommitter
16/03/31 23:17:08 INFO FileInputFormat: Total input paths to process : 1
16/03/31 23:17:08 INFO SparkContext: Starting job: save at SparkSQLLoadSaveOps.java:13
16/03/31 23:17:08 INFO DAGScheduler: Got job 1 (save at SparkSQLLoadSaveOps.java:13) with 1 output partitions
16/03/31 23:17:08 INFO DAGScheduler: Final stage: ResultStage 1 (save at SparkSQLLoadSaveOps.java:13)
16/03/31 23:17:08 INFO DAGScheduler: Parents of final stage: List()
16/03/31 23:17:08 INFO DAGScheduler: Missing parents: List()
16/03/31 23:17:08 INFO DAGScheduler: Submitting ResultStage 1 (MapPartitionsRDD[7] at save at SparkSQLLoadSaveOps.java:13), which has no missing parents
16/03/31 23:17:08 INFO MemoryStore: Block broadcast_4 stored as values in memory (estimated size 66.3 KB, free 610.9 KB)
16/03/31 23:17:08 INFO MemoryStore: Block broadcast_4_piece0 stored as bytes in memory (estimated size 23.4 KB, free 634.2 KB)
16/03/31 23:17:08 INFO BlockManagerInfo: Added broadcast_4_piece0 in memory on localhost:53595 (size: 23.4 KB, free: 1773.7 MB)
16/03/31 23:17:08 INFO SparkContext: Created broadcast 4 from broadcast at DAGScheduler.scala:1006
16/03/31 23:17:08 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 1 (MapPartitionsRDD[7] at save at SparkSQLLoadSaveOps.java:13)
16/03/31 23:17:08 INFO TaskSchedulerImpl: Adding task set 1.0 with 1 tasks
16/03/31 23:17:08 INFO TaskSetManager: Starting task 0.0 in stage 1.0 (TID 1, localhost, partition 0,PROCESS_LOCAL, 2138 bytes)
16/03/31 23:17:08 INFO Executor: Running task 0.0 in stage 1.0 (TID 1)
16/03/31 23:17:08 INFO HadoopRDD: Input split: file:/D:/DT-IMF/testdata/people.json:0+73
16/03/31 23:17:09 INFO BlockManagerInfo: Removed broadcast_2_piece0 on localhost:53595 in memory (size: 19.3 KB, free: 1773.7 MB)
16/03/31 23:17:09 INFO BlockManagerInfo: Removed broadcast_1_piece0 on localhost:53595 in memory (size: 2.4 KB, free: 1773.7 MB)
16/03/31 23:17:09 INFO ContextCleaner: Cleaned accumulator 1
16/03/31 23:17:09 INFO BlockManagerInfo: Removed broadcast_0_piece0 on localhost:53595 in memory (size: 19.4 KB, free: 1773.7 MB)
16/03/31 23:17:10 INFO GenerateUnsafeProjection: Code generated in 1030.899988 ms
16/03/31 23:17:10 INFO DefaultWriterContainer: Using user defined output committer class org.apache.parquet.hadoop.ParquetOutputCommitter
16/03/31 23:17:10 INFO CodecConfig: Compression: GZIP
16/03/31 23:17:10 INFO ParquetOutputFormat: Parquet block size to 134217728
16/03/31 23:17:10 INFO ParquetOutputFormat: Parquet page size to 1048576
16/03/31 23:17:10 INFO ParquetOutputFormat: Parquet dictionary page size to 1048576
16/03/31 23:17:10 INFO ParquetOutputFormat: Dictionary is on
16/03/31 23:17:10 INFO ParquetOutputFormat: Validation is off
16/03/31 23:17:10 INFO ParquetOutputFormat: Writer version is: PARQUET_1_0
16/03/31 23:17:10 INFO CatalystWriteSupport: Initialized Parquet WriteSupport with Catalyst schema:
{
"type" : "struct",
"fields" : [ {
"name" : "name",
"type" : "string",
"nullable" : true,
"metadata" : { }
} ]
}
and corresponding Parquet message type:
message spark_schema {
optional binary name (UTF8);
}
16/03/31 23:17:10 WARN ZlibFactory: Failed to load/initialize native-zlib library
16/03/31 23:17:10 INFO CodecPool: Got brand-new compressor [.gz]
16/03/31 23:17:12 INFO InternalParquetRecordWriter: Flushing mem columnStore to file. allocated memory: 41
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
16/03/31 23:17:12 INFO ColumnChunkPageWriteStore: written 87B for [name] BINARY: 3 values, 35B raw, 51B comp, 1 pages, encodings: [PLAIN, BIT_PACKED, RLE]
16/03/31 23:17:13 INFO FileOutputCommitter: Saved output of task 'attempt_201603312317_0001_m_000000_0' to file:/D:/DT-IMF/testdata/usersNames/_temporary/0/task_201603312317_0001_m_000000
16/03/31 23:17:13 INFO SparkHadoopMapRedUtil: attempt_201603312317_0001_m_000000_0: Committed
16/03/31 23:17:13 INFO Executor: Finished task 0.0 in stage 1.0 (TID 1). 2044 bytes result sent to driver
16/03/31 23:17:13 INFO DAGScheduler: ResultStage 1 (save at SparkSQLLoadSaveOps.java:13) finished in 4.809 s
16/03/31 23:17:13 INFO DAGScheduler: Job 1 finished: save at SparkSQLLoadSaveOps.java:13, took 5.015964 s
16/03/31 23:17:13 INFO TaskSetManager: Finished task 0.0 in stage 1.0 (TID 1) in 4808 ms on localhost (1/1)
16/03/31 23:17:13 INFO TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
16/03/31 23:17:13 INFO ParquetFileReader: Initiating action with parallelism: 5
16/03/31 23:17:13 INFO DefaultWriterContainer: Job job_201603312317_0000 committed.
16/03/31 23:17:13 INFO ParquetRelation: Listing file:/D:/DT-IMF/testdata/usersNames on driver
16/03/31 23:17:13 INFO ParquetRelation: Listing file:/D:/DT-IMF/testdata/usersNames on driver
16/03/31 23:17:13 INFO SparkContext: Invoking stop() from shutdown hook
16/03/31 23:17:14 INFO SparkUI: Stopped Spark web UI at http://192.168.56.1:4040
16/03/31 23:17:14 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
16/03/31 23:17:14 INFO MemoryStore: MemoryStore cleared
16/03/31 23:17:14 INFO BlockManager: BlockManager stopped
16/03/31 23:17:14 INFO BlockManagerMaster: BlockManagerMaster stopped
16/03/31 23:17:14 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
16/03/31 23:17:14 INFO RemoteActorRefProvider$RemotingTerminator: Shutting down remote daemon.
16/03/31 23:17:14 INFO SparkContext: Successfully stopped SparkContext
16/03/31 23:17:14 INFO ShutdownHookManager: Shutdown hook called
16/03/31 23:17:14 INFO RemoteActorRefProvider$RemotingTerminator: Remote daemon shut down; proceeding with flushing remote transports.
16/03/31 23:17:14 INFO ShutdownHookManager: Deleting directory C:\Users\think\AppData\Local\Temp\spark-cc10774b-d5bc-4ca7-a1c8-357807ab6c3e
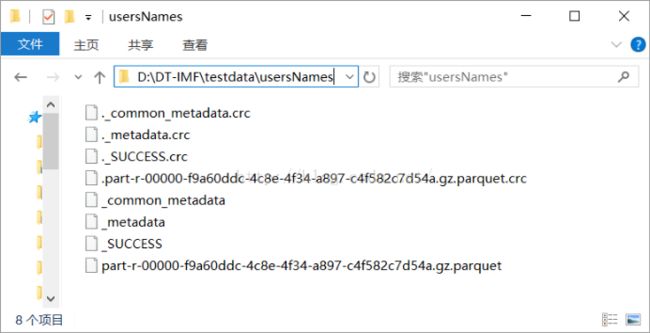
运行完成后程序自动创建D:\\DT-IMF\\testdata\\usersNames目录,并在其中生成parquet文件(默认生成Parquet文件)。如下图:
以上内容是王家林老师DT大数据梦工厂《 IMF传奇行动》第61课的学习笔记。
王家林老师是Spark、Flink、Docker、Android技术中国区布道师。Spark亚太研究院院长和首席专家,DT大数据梦工厂创始人,Android软硬整合源码级专家,英语发音魔术师,健身狂热爱好者。
微信公众账号:DT_Spark
电话:18610086859
QQ:1740415547
微信号:18610086859
新浪微博:ilovepains