Python + PySpider 抓取百度图片搜索的图片
说明
1、PySpider 是一个方便并且功能强大的Python爬虫框架
2、PySpider 依赖于PhantomJS
3、windows平台,PySpider 与64位的Python兼容不太好,需要使用32位Python
4、本文环境:Python3.5(32位)+PhantomJS2.1.1+PySpider 0.4.0
环境配置
- 安装Python(32位)
下载地址:https://www.python.org/downloads/windows/
下载Windows x86 executable installer后按指示安装,并将安装路径加入环境变量 - 列表内容
下载地址:http://phantomjs.org/download.html
下载后解压,并将bin目录放入环境变量(命令行phantomjs -v测试) - 安装PySpider
使用pip安装:命令行输入 pip install pyspider
验证安装结果:
安装完成后,命令行输入 pyspider all,然后浏览器访问http://localhost:5000
如果正常出现PySpider页面,则说明安装成功
开始抓取
获取抓取链接
在百度图片http://image.baidu.com/里随便输入搜索,将搜索结果页地址作为我们抓取的链接。我这里输入“猫咪”,然后获取到的链接是https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&fm=index&pos=history&word=%E7%8C%AB%E5%92%AA新建PySpider项目
命令行输入 pyspider all,然后浏览器访问http://localhost:5000
点击右下角的“Create”按钮
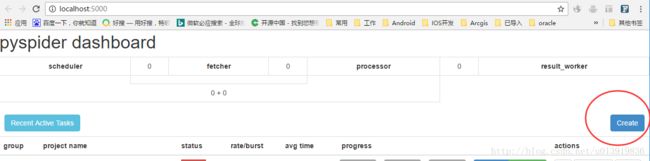
输入项目名称和我们第一步获取到的URL

然后点击“Create”即可完成创建,并打开项目的编辑界面。具体使用方式请自行百度
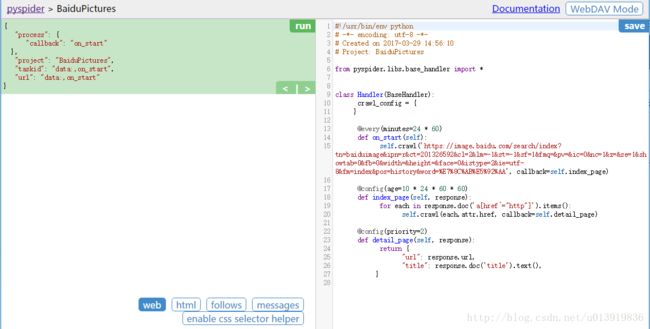
抓取思路
搜索结果页面本身已包含所有的图片,通过图片标签就可以获取到。但此种方法获取的图片分辨率较低,我们需要获取分辨率较高的图片。
搜索结果页,点击图片,会进入图片详情页,这里展示的图片分辨率较高,符合我们的要求。
所以,我们的目标就是:搜索结果页获取图片详情页的地址列表,然后再遍历进入详情页获取图片的URL,最后下载保存到本地。
下面正式开始抓取index_page中获取图片详情页地址列表
使用PySpider内置的PyQuery,通过css匹配到我们要找的链接标签,然后获取链接的地址,通过PySpider的crawl方法传递给detail_page处理图片详情页数据。
crawl方法的save参数会传递给detail_page数据,可通过detail_page方法的response参数获取
def index_page(self, response):
count = 1
#获取图片详情链接标签列表
for each in response.doc('.imgbox a').items():
url = each.attr.href
#进入图片详情页
self.crawl(url, callback=self.detail_page,validate_cert=False, fetch_type="js",save={"count":count})
count +=1 5. detail_page中获取图片地址并下载
此处也是通过PyQuery匹配到图片标签,然后获取图片地址,最后交由自定义的下载方法save_img去下载图片并保存本地
def detail_page(self, response):
#获取图片标签
imgElem = response.doc(".currentImg")
#获取图片地址
imgUrl = imgElem.attr.src
if imgUrl:
#获取图片文件后缀
extension = self.tool.get_extension(imgUrl)
#拼接图片名
file_name = str(response.save["count"]) + "." + extension
self.crawl(imgUrl,callback=self.save_img,save={"file_name":file_name},validate_cert=False)6. 保存图片方法
#保存图片
def save_img(self,response):
content = response.content
file_name = response.save["file_name"]
file_path = self.dir_path + os.path.sep + file_name
self.tool.save_img(content,file_path)7. 创建文件夹、保存图片的工具类
#工具类
class Tool:
def __init__(self):
self.dir = DIR_PATH
#创建文件夹(如果不存在)
if not os.path.exists(self.dir):
os.makedirs(self.dir)
#保存图片
def save_img(self,content,path):
f = open(path,"wb" )
f.write(content)
f.close()
#获取url后缀名
def get_extension(self,url):
extension = url.split(".")[-1]
return extension 8. 完整代码
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2017-03-29 14:56:10
# Project: BaiduPictures
from pyspider.libs.base_handler import *
import os
#图片存放目录
DIR_PATH = "D:\python_workspace\pyspider_baiduPicture"
class Handler(BaseHandler):
crawl_config = {
}
def __init__(self):
self.base_url = "https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=index&fr=&hs=0&xthttps=111111&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&word=%E7%8C%AB%E5%92%AA&oq=%E7%8C%AB%E5%92%AA&rsp=-1"
self.dir_path = DIR_PATH
self.tool = Tool()
@every(minutes=24 * 60)
def on_start(self):
#validate_cert:是否验证SSL;fetch_type:为了支持JS
self.crawl(self.base_url, callback=self.index_page, validate_cert=False, fetch_type="js")
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
count = 1
#获取图片详情链接标签列表
for each in response.doc('.imgbox a').items():
url = each.attr.href
#进入图片详情页
self.crawl(url, callback=self.detail_page,validate_cert=False, fetch_type="js",save={"count":count})
count +=1
@config(priority=2)
def detail_page(self, response):
#获取图片标签
imgElem = response.doc(".currentImg")
#获取图片地址
imgUrl = imgElem.attr.src
if imgUrl:
#获取图片文件后缀
extension = self.tool.get_extension(imgUrl)
#拼接图片名
file_name = str(response.save["count"]) + "." + extension
self.crawl(imgUrl,callback=self.save_img,save={"file_name":file_name},validate_cert=False)
#保存图片
def save_img(self,response):
content = response.content
file_name = response.save["file_name"]
file_path = self.dir_path + os.path.sep + file_name
self.tool.save_img(content,file_path)
#工具类
class Tool:
def __init__(self):
self.dir = DIR_PATH
#创建文件夹(如果不存在)
if not os.path.exists(self.dir):
os.makedirs(self.dir)
#保存图片
def save_img(self,content,path):
f = open(path,"wb" )
f.write(content)
f.close()
#获取url后缀名
def get_extension(self,url):
extension = url.split(".")[-1]
return extension