Understanding Cubert Concepts(一)Partitioned Blocks
Understanding Cubert Concepts(一)Partitioned Blocks
Cubert Concepts
对于Cubert,我们要理解其核心的一些概念,比如BLOCK。这些概念也是区别于传统的关系型范式(Pig,Hive)等数据处理流程并使得Cubert在大规模数据下JOIN和Aggregation中取胜的关键因素。(自己测下来,CUBE的计算效率比Hive高好多倍。)
BLOCK
Cubert定义了一个BLOCK的概念,分为两种:Partitioned Blocks & Co-ParitionedBlocks
Hubert将这些Block存储为特殊的格式,叫做Rubix Format
Partitioned Blocks
从字面上来看,叫做分区块。
比如说有一个pageviews表,有三个列,分别为:memberId(int),pagekey(string),timestamp(long)
通常在HDFS中,这些数据会被切分为一个个的文件(part-00000.avro, part-00001.avro, etc),然后置于某一个目录下,这些数据默认是没有被分区和排序的。
然而,在Cubert的世界里,我们鼓励数据能被更加结构化的存储。
更确切的来说,我们希望数据能够根据一些分区键来进行分区成一些数据单元,这些数据单元就是Cubert中的Partitioned Blocks, 而且我们希望在每个Block中的数据能够在某些列上是有序的。
PS:这里面涉及到2个概念:PartitionKeys 和 SortKeys,对应于上述的分区键和排序键。
BLOCKGEN
将Raw data转化为partitioned和sorted的data units的过程称为BLOCKGEN。这个是Cubert语法里一个非常重要的操作符。
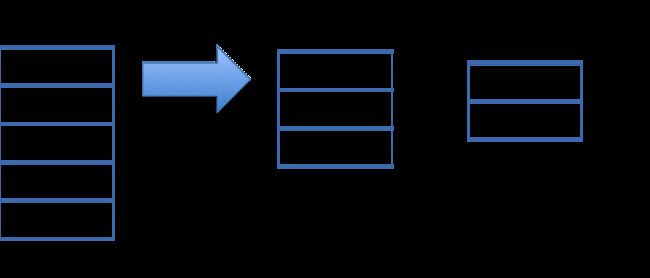
这张图告诉我们:
1. 我们有一个table,2列,JK和GK
2. BLOCKGEN的过程就是选择一个partitionKey为JK,根据这个分区键来对数据块分区。然后对分区后的数据块内部选择GK作为排序键,来对分区后的数据块排序。
3. 这样原始数据划分称为了2个partitionedBlocks即BLOCK#1,BLOCK#2
BLOCKGEN Checklist
作为一个Cubert的开发者,我们需要遵从4个规范:
1.定义PartitionKeys
从这个数据集的列中选择要根据哪几个列进行分区。
举个来说:
对于pageviews这个表:
如果指定分区键为memberId,那么我们可以确定的是,所有memberId=1234的数据Row都会被分区到一个partitionedBlock中去.
2.定义SortKeys(可选)
从这个数据集的列中选择要根据哪几个列进行排序,如果不指定,默认和分区键相同。
Note:这个排序操作不是全局排序,只是在每个已经分区好的block内部进行局部排序。
举个来说:
还是pageviews这个表:
我们分区后的数据,可以根据timestamp这个时间字段,在对block内部的rows进行排序。
3.定义代价函数CostFunction
前面一直提到分区,具体如何来划分block呢?这时候cost function起到了作用:
- BY ROW 根据数据行数来划分,每个block中最多油多少行记录。如果超出阀值,则新生成一个
block。 - BY PARTITION KEYS 根据分区键来划分,每个block要有指定数目的
partition keys。如果partition keys是主键的话,那么和BY ROW这个cost function效果类似。 - BY SIZE 根据数据块的大小来划分,单位bytes。超过指定阀值,就会新建一个block。
4.存储结果数据格式(必须)为RUBIX格式
RUBIX是一种特殊的数据格式,它存储了数据的一些索引细信息和BLOCKGEN过程需要的一些metadata
Creating Partitioned Blocks(Demo)
Note: BLOCKGEN是一个shuffle command
该程序的分区键:memberId
排序键:timestamp
JOB "our first BLOCKGEN"
REDUCERS 10;
MAP {
data = LOAD "/path/to/data" USING AVRO();
}
// Create blocks that are (a) partitioned on memberId, (b) sorted on timestamp, and
// (c) have a size of 1000 rows
BLOCKGEN data BY ROW 1000 PARTITIONED ON memberId SORTED ON timestamp;
// ALWAYS store BLOCKGEN data using RUBIX file format!
STORE data INTO "/path/to/output" USING RUBIX();
END由于我们设定了reducer的个数为10,那么将会有10个part-xxx.rbx文件,e.g.:(part-r-00000.rbx through part-r-00009.rbx)
Note:每个rbx文件中可以包含>=1个block。所以不用担心会生产太多的file.
参考
Cubert官方文档blocks
Ps:本文的写作是基于对Cubert官方文档的翻译和个人对Cubert的理解综合完成 :)
原创文章,转载请注明:
转载自:OopsOutOfMemory盛利的Blog, 作者: OopsOutOfMemory
本文链接地址:
注:本文基于署名-非商业性使用-禁止演绎 2.5 中国大陆(CC BY-NC-ND 2.5 CN)协议,欢迎转载、转发和评论,但是请保留本文作者署名和文章链接。如若需要用于商业目的或者与授权方面的协商,请联系我。