LSSVM(Least Squares SVM)与SVR(支持向量回归)
SVR的推导
LSSVM(Least Square SVM)是将Kernel应用到ridge regression中的一种方法,它通过将所有样本用最小二乘误差进行拟合(这个拟合是在kernel变换过的高维空间),但是LSSVM的缺陷是计算复杂度大概是样本数的三次方量级,计算量非常大。为了解决这个问题于是提出了SVR(支持向量回归),SVR通过支持向量减小了LSSVM的计算复杂度,并且具备LSSVM的能够利用kernel在高纬度拟合样本的能力。
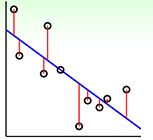
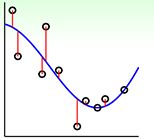
LSSVM
在上一篇降到的逻辑回归(Logistic Regression)和SVM的联系以及Kernel这篇中提到了优化误差形式如下面(1)这个形式的,最终求得的权重w是z的线性组合,然后把这个形式的w代入原式子中就可以利用kernel了,LSSVM的推导过程就是这样。
Ridge regression的优化形式如(2),刚好符合(1)式中的形式,因此把w代入(2)中可以将Ridge regression写成(3):
如果把(3)写成矩阵的形式,那么可以写成如(4)所示,其中K表示kernel_{n,m}组成的矩阵:
于是就变成了对 β 的求解,在这个凸函数中,求解方法就是求梯度为0的 β ,求解如下:
在SVM推导过程中讲到过,合法的Kernel必须是z_n,z_m组成Kernel的矩阵必须是半正定的,因此上面这个求逆过程必定有解。
再来看线性回归,线性回归中,最后求得的w如下式所示:
在线性回归的解(7)中,X^TX之后之和样本的维度d有关,因此计算复杂度大概是d的三次方级别。
但是(6)中K这个矩阵是N乘以N的,所以,解这个逆的过程中需要消耗O(N^3)的计算复杂度,如果训练过程中N过于大,比如几万,这个求解过程消耗的计算资源就变得不可承受了。
SVR
在SVM中,根据KKT条件,我们得到的w最后是support vector的线性组合,这个大大减少了w的计算成本。在回归问题中,LSSVM能够利用kernel拟合更复杂的模型,但是问题是LSSVM的计算量很大,我们从SVM中得到一个启发,在解决回归问题的时候,能否像SVM那样,只用很少数量的support vector来计算最后的模型,SVR就是这样的一个模型,它能够像SVM那样利用很少的一些点来计算得到最后得到类似LSSVM那样能够拟合复杂数据的模型。
SVR的模型假设
SVM中模型的假设是放宽条件,能够容忍边界附近的噪声存在,在margin里面的噪声可以忽略不计。在SVR中,我们也像SVM一样,设置一个margin,落在margin里面的样本点就不算它误差,如下图所示,这个margin的高度(不是宽度)是2 ϵ ,上面的样本距离margin的高度(误差)为 ξ∗ ,下面的样本距离margin的高度(误差)为 ξ :
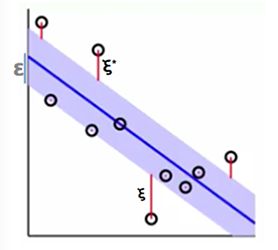
如上面的图所示,如果样本点落在margin里,则不算误差;如果落在外面则误差为 |y−s|−ϵ , y代表理想模型中的值,s代表观测到的样本的y值,那么这个tube error可以写成:
这个error和之前LSSVM的square error进行对比,如下图,可以看到两个误差其实比较接近,但是square error的增长是平方的,tube error的增长是线性的,square增长更快,所以在拟合过程中,LSSVM对错误的惩罚越重,它希望得到的是一条完美的没有错误的线,这和hard margin一样,更可能造成过拟合。

后面就是类似SVM一样,加上L2的正则项来推导sparse的support vector的回归,它的假设可以写成如下:
可以写成SVM那样用二次规划推导的形式:
SVR的推导
下面的解法和推导SVM过程一模一样啦,首先先把上面的式子写成Lagrange乘子法的形式:
把上面求得的结果全部代入L中,可以得到下式:
上式也是一个标准的二次规划问题,只是比SVM中的参数多了一点,可以用二次规划的软件来求解。根据KKT条件和求偏导过程,我们得到下面几个式子:
从这里看出w还是z的线性组合,为了说明这里的z是sparse的,我再做如下推导:
这里的点有下面两种
(1)点是落在margin里面的,那么这个 ξi 和 ξi *都为0,因为在margin里面,于是 ϵ+ξ∗i−yi+wTzi+b≠0 和 ϵ+ξi+yi−wTzi−b≠0 ,于是这种点的 α 都是0,这种点在上面w的线性组合中是完全没有贡献的
(2)点落在margin上,则括号里面的式子为0, α (包括带 的)可以为0,可以不为0;落在外面的,则 α (包括带的)不为0
这就说明的SVR中求w没有用到所有的z,而只是用了其中很小的一部分。
另外在SVR中,这个margin的宽度 ϵ 和C都是用户输入的,因此可以人为的去控制最后计算w点的多少。
总结
SVR通过设定一个margin,容忍margin中样本所犯的误差,解决了LSSVM中回归拟合计算量过大的问题,然后可以通过减小margin的大小去逼近LSSVM,而且这两个方法都具备的优势就是都利用了kernel,使模型具备了拟合更复杂数据的能力。
我的微信公众号是:数据科学家的日常,会记录一些我平时的学习心得以及各种机器学习算法的学习笔记,欢迎关注。