Spark 共享变量:广播变量、累加器
通常,如下操作rdd.transformation(func),func所需要的外部变量都会以副本的形式从Driver端被发送到每个Executor的每个Task,当Task数目有成百上千个时,这种方式就非常低效;同时每个Task中变量的更新是在本地,也不会被传回Driver端。为此,Spark提供了两种类型的共享变量:广播变量、累加器。
广播变量
广播变量,Execoutor中的只读变量。在Driver端定义,在Exector中只读。
在Execoutor的Task中只读。可用来缓存全局只读变量到Exector中,减少网络通信和存储开销。
不使用广播变量
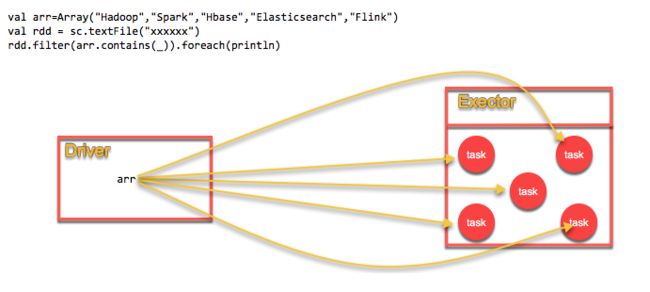
使用广播变量

广播变量使用
Broadcast Join
package com.bigData.spark
import org.apache.log4j.{Level, Logger}
import org.apache.spark.sql.SparkSession
/**
* Author: Wang Pei
* License: Copyright(c) Pei.Wang
* Summary:
*
*/
object BroadcastValue {
def main(args: Array[String]): Unit = {
//日志等级
Logger.getLogger("org").setLevel(Level.WARN)
//Spark环境
val spark = SparkSession.builder().master("local[3]").appName(this.getClass.getSimpleName).getOrCreate()
//原数据:studentId,language,math,english
val scoreRDD = spark.sparkContext.parallelize(Array(
(111,68,69,90),
(112,73,80,96),
(113,90,74,75),
(114,89,94,93)
))
//lookup table: studentId,classId
val lookupCache=spark.sparkContext.broadcast(
Map(111->"class1",112->"class1",113->"class2")
)
//broadcast join
val result=scoreRDD.map(item=>(item._1,item._2,item._3,item._4,lookupCache.value.getOrElse(item._1,None)))
result.foreach(println)
}
}
累加器
累计器,Execoutor中的只增变量。在Exector的Task中只增,在Driver端可读。可用来分布式全局计数和分布式全局聚合。
注意:从Spark 2.x开始,之前的Accumulator被废除,用AccumulatorV2代替。
累加器使用
分布式计数
package com.bigData.spark
import org.apache.spark.sql.SparkSession
/**
* Author: Wang Pei
* License: Copyright(c) Pei.Wang
* Summary:
*
* 使用累加器进行分布式计数
*
*/
object DistributedCounter {
def main(args: Array[String]): Unit = {
/**spark环境*/
val spark = SparkSession.builder().appName(this.getClass.getSimpleName).master("local[3]").getOrCreate()
/**rdd*/
val rdd = spark.sparkContext.parallelize(1 to 8)
/**定义累加器*/
val counter = spark.sparkContext.longAccumulator("DistributedCounter")
/**分布式计数*/
rdd.foreach(item=>{
if(item%2==0){
counter.add(item)
}
})
/**读取累加器的值*/
println(counter.value)
//累加器如果提供了名称(如上DistributedCounter),在Spark UI监控界面可查看每个Task对累加器的累加值
while(true){
}
}
}

异常数据收集
package com.bigData.spark
import com.alibaba.fastjson.{JSON, JSONException, JSONObject}
import org.apache.spark.sql.SparkSession
/**
* Author: Wang Pei
* License: Copyright(c) Pei.Wang
* Summary:
* 使用累加器收集异常数据
*
*/
object ExecptionLogCollect {
def main(args: Array[String]): Unit = {
/**spark环境*/
val spark = SparkSession.builder().appName(this.getClass.getSimpleName).master("local[3]").getOrCreate()
/**定义累加器*/
val collectionAcc = spark.sparkContext.collectionAccumulator[String]("ExecptionLogCollect")
/**解析原始Json,并收集异常Json*/
spark.sparkContext.parallelize(Array(
"{\"uid\":\"uid1\"}",
"{\"uid\":\"uid2\"}",
"{uid:\"uid3\""
)).foreach(item=>{
var ret:JSONObject=null
try{
ret=JSON.parseObject(item)
}catch {
//异常json收集
case e:JSONException => collectionAcc.add(item)
}
ret
})
/**读取累加器的值*/
println(collectionAcc.value)
//Spark UI监控界面查看累加器
while (true){
}
}
}

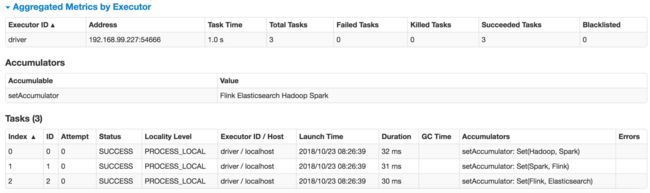
自定义累加器
继承抽象类AccumulatorV2,实现6个方法。
package com.bigData.spark
import org.apache.spark.sql.SparkSession
import org.apache.spark.util.AccumulatorV2
/**
* Author: Wang Pei
* License: Copyright(c) Pei.Wang
* Summary:
* 自定义Set 累加器
*
*/
object CustomAccumulator {
def main(args: Array[String]): Unit = {
/**spark环境*/
val spark = SparkSession.builder().appName(this.getClass.getSimpleName).master("local[3]").getOrCreate()
/**定义累加器,并注册*/
val setAcc = new SetAccumulator[String]()
spark.sparkContext.register(setAcc,"setAccumulator")
/**解析原始Json,并收集异常Json*/
spark.sparkContext.parallelize(Array("Hadoop","Spark","Spark","Flink","Flink","Elasticsearch"))
.foreach(setAcc.add(_))
/**读取累加器的值*/
println(setAcc.value)
//Spark UI监控界面查看累加器
while (true){}
}
}
/**自定义累加器 继承类,实现方法*/
class SetAccumulator[T](var value: Set[T]) extends AccumulatorV2[T, Set[T]] {
//构造方法
def this()=this(Set.empty[T])
//空值,则执行
override def isZero: Boolean = {
value.isEmpty
}
//复制
override def copy(): AccumulatorV2[T, Set[T]] = {
new SetAccumulator[T](value)
}
//重置
override def reset(): Unit ={
value=Set.empty[T]
}
//添加
override def add(v: T): Unit = {
value=value + v
}
//合并
override def merge(other: AccumulatorV2[T, Set[T]]): Unit = {
value=value ++ other.value
}
}