1.SVN服务实战
1) 什么是SVN(Subversion)?
- Svn(subversion)是近年来崛起的非常优秀的版本管理工具,与CVS管理工具一样,SVN是一个跨平台的开源的版本控制系统。Svn版本管理工具管理着随时间改变的各种数据。这些数据放置在一个中央资料档案库(repository)中,这个档案库很像一个普通的文件服务器或者FTP服务器,但是,与其他服务器不同的是,SVN会备份并记录每个文件每一次的修改更新变动。这样我们就可以把任意一个时间点的档案恢复到想要的某一个旧的版本,当然也可以直接浏览指定文件的更新历史记录。
- 为什么会有svn这样一个项目?
- 官方解释:为了接管CVS的用户基础,确切的说,我们写了一个新的版本控制系统,它和CVS很相似,但是它修正了以前CVS所没有解决的许多问题。问题见SVN官方首页。
- SVN是一个非常通用的软件系统,它常被用来管理程序源码,但是它也可以管理任何类型的文件,如文本,视频,图片等等。
2) svn与git的区别
svn集中式版本控制系统
svn版本控制系统是集中式的数据管理,存在一个中央版本库,所有开发人员本地开发所使用的代码都是来自于这个版本库,提交代码也都必须提交到这个中央版本库。
svn版本控制系统工作流程如下:
- 在中央库上创建或从主干复制一个分支
- 从中央库check out 下这个分支的代码
- 增加自己的代码文件,修改现存的代码或删除代码文件
- commit代码,假设有人在刚刚的分支上提交了代码,你就会被提示代码过期,你得先up你的代码后再提交。up代码的时候如果出现冲突,需要解决好冲突后再进行提交。
缺点:
当无法连接到中央版本库的环境下,你无法提交代码,将代码加入版本控制; 你无法查看代码的历史版本以及版本的变化过程。提交到版本控制系统中的代码我们都默认通过自测可运行的,如果某个模块的代码比较复杂,不能短时间内实现为可测试的功能,那么你需要等很长的时间才能提交自己的代码,由于代码库集中管理,因此,需要对中央版本库的存储做备份。这点分布式的版本控制系统要好一些。Svn的备份要备份所有代码数据以及所有更改的版本记录。
git分布式的版本控制
- git是由Linus开发的,所以很自然的git和Linux文件系统结合的比较紧密,以至于在windows上你必须使用cygwin才能使其完美的工作。
- 那git凭啥叫做分布式的版本控制系统呢?还是从其工作模式讲起。
- git中没有了中央版本库的说法了,但是为了开发小组的代码共享,我们通常还是会搭建一个远程的git仓库。
- 但是和svn不同的是,开发者本地也包含了一个完整的git仓库,从某种程度上说本地的仓库和远程的仓库在身份上是等价的,没有主从之分。
- 如果你的项目是闭源项目,或者你习惯于以往的集中式的管理模式的话,那么在git下你也可以像svn那样的工作,只是流程中可能会增加一些步骤。
- 你本地创建一个git库,并将其add到远程git库中。
- 你在本地添加或者删除文件,然后commit,当然commit操作都是提交到本地的git库中了。(嗯,其实是提交到git目录下的objects目录中去了)
- 将本地git库的分支push到远程git库的分支,如果这个时候远程git库中已经有别人push过,那么远程git库将不允许你push,这时候你需要先pull,然后如果有冲突,处理好冲突,commit到本地git库后,再push到远程git库。
从上面的描述我们可以看到,我们每个开发人员的本地都会有一个git库,我们可以随时进行commit而不需要联网,可以随时查看历史版本,当某一个功能点开发完了之后我们可以将commit后的内容push到远程git库了,如果远程git库的版本在你上次clone或者pull之后变化了,那么你需要进行pull并处理冲突,提交之后,再push到远程git库。
运维人员掌握版本管理
对于版本管理系统,运维人员需要掌握的技术点:
- 安装,部署,维护,排障。
- 简单使用,很多公司都是由开发来管理,包括建立新仓库和添加删除账号
- 对于版本控制系统,运维人员相当于开发商,开发人员是业主,运维搭建的系统为开发人员服务的。
3)SVN服务端运行方式
svn服务常见的运行访问方式有3种:
(1)独立服务器访问
访问地址如:svn://svn.yunjisuan.org/sadoc;
(2)借助apache等http服务
访问地址如:http://svn.yunjisuan.com/sadoc;
a,单独安装apache+svn(不要用) b,CSVN(apache+svn)是一个单独的整合的软件,带web界面管理的SVN软件
(3)本地直接访问(例如:file://application/svndata/sadoc)
2.搭建SVN服务端
yum -y install subversion
mkdir -p /application/svndata #数据存储根目录
创建一个新的Subversion项目test,其实,类似yunjisuan这样的项目可以创建多个,每个项目对应不同的代码,这里只是以创建一个项目为例演示:
svnadmin create /application/svndata/test
tree /application/svndata/test 查看项目目录结构
cd /application/svndata/test/conf/
cp svnserve.conf{,.bak}
vim svnserve.conf 修改配置文件
anon-access = none #禁止匿名访问
auth-access = write #验证访问可写
password-db = passwd #密码文件位置
authz-db = authz #验证文件位置
此配置文件里的每条配置代码必须顶格写,不能有空格。
启动svn服务
svnserve -d -r /application/svndata/ 启动服务
netstat -antup | grep 3690 查看服务
vim /application/svndata/test/conf/passwd
test= 123123 #设置账号密码
yst = 123123 #设置账号密码
权限配置说明
vim /application/svndata/test/conf/authz
[groups]
yun= test,yst #新增本行,定义组名
[test:/] #定义授权的范围
yunjisuan = rw #用户单独授权
benet = r #用户单独授权
@sagroup = r #组用户授权
重启动svnserve
3.搭建SVN客户端
使用svn客户端(windows版)
推荐:TortoiseSVN-1.9.7.27907-x64-svn-1.9.7
一路 下一步,安装成功
先在本地创建一个目录,起名任意,比如data
选择右键菜单里的SVN Checkout,输入svn地址, 本例为svn://192.168.1.11/test
点ok,输入前面创建的用户名和密码test,123123,从版本库中取得代码
在本地修改,后要提交到版本库,右键点commit,提交生成第一版本,其他程序员修改会生成不同版本,我们本地要下载代码,右键点 update,下载最新的代码版本
4.SVN钩子脚本
1)常用钩子脚本
post-commit:在提交完成成功创建版本之后执行该钩子,提交已经完成,不可更改,因此,本脚本的返回值被忽略。提交完成时触发事务
pre-commit提交完成前触发执行该脚本
start-commit在客户端还没有向服务器提交数据之前,即还没有建立Subversion transaction之前,执行该脚本(提交前出发事务)
利用钩子脚本触发同步数据的注意事项
(1)一定要定义变量,主要是用过的命令的路径。因为SVN的考虑的安全问题,没有调用系统变量,如果手动执行是没有问题,但SVN自动执行就会无法执行了。
(2)SVN的同步目录在 update之前一定要先checkout一份出来,还有这里一定要添加用户和密码。
(3)加上了对前一个命令的判断,如果update的时候出了问题,程序没有退出的话还会继续同步代码到Web服务器上,这样会造成代码有问题。
(4)建议最好记录日志,出错的时候可以很快的排错
(5)最后是数据同步,rsync的相关参数一定要清楚。
svn钩子生产应用场景举例
- pre-commit:限制上传文件扩展名及大小,控制提交要输入的信息等。
- post-commit:SVN更新自动周知,MSN,邮件或短信周知。 SVN更新触发checkout程序,然后实时rsync推送到服务器等。
2)svn钩子生产应用实战
rsync与svn钩子结合实现数据实时同步某企业小案例
(1)建立同步WEB目录
mkdir -p /data/www
(2)将SVN中内容checkout到WEB目录一份。
svn checkout svn://192.168.1.13/test /data/www --username=test --password=123123
3)制作钩子脚本,post-commit
root@localhost yunjisuan]# cd /application/svndata/test/hooks/
[root@localhost hooks]# cp post-commit.tmpl post-commit #复制模板一份
[root@localhost hooks]# egrep -v "#|^$" post-commit #模板原始内容
REPOS="$1" REV="$2" mailer.py commit "$REPOS" "$REV" /path/to/mailer.conf [root@localhost hooks]# vim post-commit #修改post-commit脚本 [root@localhost hooks]# egrep -v "#|^$" post-commit REPOS="$1" #传参(未用上) REV="$2" #传参(未用上) SvnIP="192.168.1.13" #svn服务端的IP地址 ProjectName="test" #svn服务端的项目库名称 UserName="test" #账户姓名 PassWord="123123" #账户密码 LocalPath="/data/www" #位于svn本地的共享目录 SVN=/usr/bin/svn #svn命令的绝对路径 export LC_CTYPE="en_US.UTF-8" #中文字符集支持 export LC_ALL= if [ ! -d ${LocalPath} ];then mkdir -p ${LocalPath} $SVN checkout svn://${SvnIP}/${ProjectName} ${LocalPath} --username=${UserName} --password=${PassWord} #新创建目录需要先经过checkout才能update else $SVN update --username $UserName --password $PassWord /data/www #更新共享目录内容 fi if [ $? -eq 0 ];then /usr/bin/rsync -az --delete /data/www /tmp/ #数据同步推送到本地/tmp目录下(生产环境可以直接同步推送到Web测试服务器) fichmod 700 post-commit
特别提示:
当用户通过svn更新钩子post-commit所在的项目库时,在更新完毕之后会自动触发钩子脚本
模拟更新项目库版本
在windows系统中的data目录中添加代码文件,然后右键点commit,成功后触发钩子脚本
ll /tmp/www/ #推送后的数据目录
显示全部提交后的代码文件
综上,post-commit钩子脚本测试成功。
5.大中小型企业上线解决方案
1)小型公司代码上线案例(十几台服务器)
开发每次修改完代码就直接提交,然后通过FTP直接更新到Web服务器网页目录;没有专门的测试人员,完全是由用户来进行测试体验。
小型公司一般只有几个开发人员,网站核心程序大多数都是PHP语言开发,为了方便,会直接通过FTP直接上传程序代码到线上服务器,随时随地上线更新。
- 开发人员发布的代码不经过测试人员的测试,且用户访问页面刷新后页面即改变,也可能刷新瞬间程序在更新,到时无法访问,对网站用户的体验比较差,如果开发写错了代码,造成的影响就更大了,这是拿用户作为测试的上线方案。
- 据统计,网站中大概50%以上的故障是和开发程序代码有关的,(比如:开发写错了一个循环代码,导致了死循环,此时大量用户访问这个程序,就能把服务器资源耗尽,搞死服务器)
小型企业上线架构方案建议:
- 开发人员需在个人电脑搭建LAMP环境测试开发好的网站代码,并且在办公室或IDC机房的测试环境测试通过,最好有专职测试人员。
- 程序代码上线规定时间,例如,三天上线一次,如网站需经常更新可每天下午17点上线,这个看网站业务性质而定,原则就是影响用户体验最小。
- 代码上线之前需备份,网站程序出了问题方便回退,另外,网站程序出了问题方便回退,另外,从上线技巧上讲,上传代码时尽可能先传到服务器网站临时目录,传完整后一步mv过去,或者通过ln做软连接。(线上更新代码思路)
- 务必由运维人员管理上线,对于代码的功能性,开发人员更在意,而对于代码的性能和服务的稳定,运维更在意,因此,如果网站问题归运维管,就要让运维上线这样更规范科学。否则,开发随意更新,出了问题运维负责,这样就错了。
2)中型企业上线解决方案
中型企业上线,一般是规范运维人员操作步骤,制定统一的上线操作脚本,备份文件名称,备份文件路径。使操作人性化,统一化,自动化。
3)大型企业上线解决方案
大型企业上线一般制度和流程控制较多,比较严谨,下面是某大型企业上线解决方案架构:
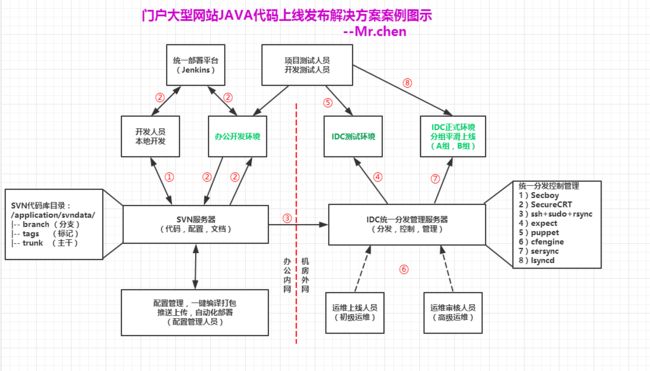
SVN里的内容:
1,程序代码
2,服务的配置
3,项目文档,设计文档,运维部署优化文档
门户大型网站架构环境代码上线具体方案:
- 本地开发人员从SVN中取代码。当天上线的提交到trunk,否则,长期项目单开分支开发,然后在合并主线(trunk)
- 办公内网开发测试时,由开发人员或配置管理员通过部署平台jenkins实现统一部署,(即在部署平台上控制开发机器从SVN取代码,编译,打包,发布到开发机器,包名如idc_dep.war)
- 开发人员通知或和测试人员一起测试程序,没有问题后,打上新的tag标记。
- 配置管理员,根据上步的tag标记,checkout出上线代码,并配置好IDC测试环境的所有配置,执行编译,打包(mvn,ant)(php不需要),然后发布到IDC内的统一分发服务器,这里要注意,不同环境的配置文件是随代码同时发布的。
- 配置管理员或SA上线人员,把分发的程序代码内容推送到相关测试服务器(包名如idc_test.war),然后通知开发及测试人员进行测试。如果有问题向上回退,继续修改。
- 如果测试没有问题,继续打好tag标记,此时,配置管理员,根据上步的tag标记,checkout出测试好的代码,并配置好IDC正式环境的所有配置,执行编译,打包(mvn,ant)(php不需要),然后发布到IDC内的统一分发服务器主机,准备批量发布。
- 配置管理员或SA上线人员,把分发的内容推送到相关正式服务器(包名如idc_product.war),然后通知开发及测试人员进行测试。如果有问题直接发布回滚指令。
IDC正式上线的过程对于JAVA程序,可以是AB分组上线的思路,即平滑下线一半的服务器,然后发布更新代码测试,无问题后,挂上服务器,同时在平滑下线另一半的服务器,然后发布更新代码测试(或者直接发布后就挂上线)
PHP程序代码上线的具体方案:
对于PHP上线方法:发布代码时(也需要测试流程)可以直接发布到正式线临时目录,然后mv或更改link的方式发布到正式线目录,不需要重启http服务。这是sina,ganji的上线方案。
JAVA程序代码上线的具体方案:
对于java上线方法:较大公司需要分组平滑上线,例如,首先从负载均衡器上摘掉一半的服务器,发布代码后,重启服务器测试,没问题后,挂上经过测试的这一半,再下另外一半。如果前端有DNS智能解析,上线还可以分地区上线若干服务器,逐渐普及到全国的服务器,这个被称为灰度发布。
和讯案例
ABCD 12:33:24
我们这里代码发布都不太标准,全部都是开发自己搞
12:35:14 目前是什么个方式呢 说下现状即可。 ABCD 12:36:04 就是很传统,开发有权限可以上机器,我们就把应用部署好,他们随便折腾。 ABCD 12:41:05 源代码是svn,静态内容都是同步分发(3)小米案例
XYZ 13:36:49
代码上线都是开发上,我们运维这边没有流程...如果代码发布导致了问题,就是开发的问题。
XYZ 13:37:55 服务器上面有一个客户端,开发自己在页面上点发布,客户端就去拉代码了。 就是这么个额流程,就像你以前说的,项目责任制,谁的项目出问题了。找开发和运维 13:49:08 不需要重启服务器么?还有直接拉到站点目录么? XYZ 13:49:17 嗯,都是自动的 他们有个管理系统 13:49:49 如何保证不影响用户呢? 还有怎么回滚的。 XYZ 13:50:12 还没有做到这点把 那个管理系统可以回滚的,好像 平时把客户的部署上去,再把机器加入到那个系统中 他们就可以发了。 XYZ 13:58:16 运维这边就管添加机器和安装客户端,也有发布权限,项目上线后很少发。一教就会没有在这块搞过太多,那个程序和版本管理结合的。实现原理应该就是客户端收到服务器发来的clone命令和路径,就去执行了。什么是配置管理员呢?
就是在开发和运维中间起一个连接纽带的一个职位,这个职位一般在大公司里会设置,负责SVN的管理,上线管理,申请,协调等工作。
自动化部署和上线代码管理
对于门户网站或重视规范或开发能力较强的公司也许会结合系统服务和WEB界面管理来更科学更自动的进行上线代码管理,如开发一个自动化代码上线部署平台,其实就是一个web管理界面(界面底层调用相关脚本实现分发推送代码以及重启服务器),然后普通的初级上线人员就可以在平台里实现仅仅点鼠标,敲回车,就能实现平滑上线和平滑回滚代码了,当然,自动化和完善的程度也许没我们说的这么好,但是,思路是这样的。