Deeplab系列(V1\V2\V3)论文理解
目录
Version1
Version2
Version3
Version3+
Version1
Pretrained model and prototxt
以前网络存在的问题:
重复的池化和下采样层组合有平移不变形,其增强了数据分层抽象的能力,但是会阻碍低级的视觉任务(精确定位/抽象的空间关系)。
本文结合了深度卷积神经网络(DCNNs)和概率图模型(DenseCRFs);DeepLab将DCNNs层的响应和完全连接的条件随机场(CRF)结合;同时将hole(空洞卷积)算法应用在DCNNs模型上,在GPU上速度为8FPS。
DCNN的图像转化的平移不变性(invariance),是源于重复的池化和下采样的组合。平移不变性增强了对数据分层的抽象能力,但是对语义分割、姿态估计不友好,因为这些任务倾向于精确的定位而不是抽象的空间关系。
DCNN在图像标记任务中的技术障碍:
- 空间下采样
- 空间信息不敏感
空间下采样: 重复的最大池化和下采样带来分辨率下降的问题,会丢失细节。DeepLab采用atrous(带孔)算法扩展感知野,获得更多上下文信息。
空间信息不敏感:DeepLab采用完全连接的条件随机场(DenseCRF)提高模型捕获细节的能力。
本文讨论了CRF和多尺度两种方式。
空洞卷积:
带孔的采样,又称atrous算法,可以稀疏的采样底层特征映射。在VGG16中使用不同采样率的空洞卷积,可以让模型在密集计算的同时,明确控制网络的感受野。
空洞卷积是在标准的卷积上注入空洞,以此增加receptive field,多了一个称为dilation rate即kernel间隔数量的超参数。
考虑一维信号,空洞卷积输出为![]() ,输入为
,输入为![x[i]](http://img.e-com-net.com/image/info8/a470029d69e24d1d9db0e874109b5194.gif) ,长度k的滤波器为
,长度k的滤波器为![]() ,定义为
,定义为![y[k]=\sum_{k=1}^{ K}x[i+r\cdot k]\omega [k]](http://img.e-com-net.com/image/info8/929d207f9abf4afc81ac4661064490c4.gif) ,输入采样的步幅为参数r,标准的采样率是
,输入采样的步幅为参数r,标准的采样率是![]() 。
。

空洞卷积能够放大滤波器的感受野,rate引入r-1个0,将感受野从k扩大到k+(k-1)(r-1),而不增加参数和计算量。
CRF在语义分割上的应用:
对于每个像素 具有类别标签
具有类别标签 还有对应的观测值
还有对应的观测值 。每个像素作为节点,像素与像素间的关系作为边,即构成了一个条件随机场。我们通过观测变量来推测像素对应的类别标签。
。每个像素作为节点,像素与像素间的关系作为边,即构成了一个条件随机场。我们通过观测变量来推测像素对应的类别标签。

条件随机场符合吉布斯分布( 是上面的观测值,下面的公式省略全局观测
是上面的观测值,下面的公式省略全局观测 :
:
![]()
 为能量函数,其定义为:
为能量函数,其定义为:
![]()
这里分为一元势函数![]() 和二元势函数
和二元势函数![]() 两部分。
两部分。
一元势函数![]() 是表示观察到当前像素点像素为,则其对应标签的概率值。
是表示观察到当前像素点像素为,则其对应标签的概率值。
![]()
二元势函数![]() 用于刻画变量之间的相关关系以及其观测序列对其的影响
用于刻画变量之间的相关关系以及其观测序列对其的影响

其中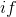
![]() ,则
,则![]() ,否则为1,
,否则为1,![]() 为
为![]() 之间的高斯和,
之间的高斯和, 为像素的特征向量,例如像素点的特征向量用
为像素的特征向量,例如像素点的特征向量用![]() 表示,对应的权重为
表示,对应的权重为
第一核取决于像素位置( )和像素颜色强度(),第二个核取决于像素位置()
)和像素颜色强度(),第二个核取决于像素位置()
多尺度预测:
在输入图像和前四个最大池化层的输出上增加了两层MLP(第一层是128个3*3卷积,第二层是128个1*1卷积),最终输出的特征映射送到模型的最后一层辅助预测。
DeepLab是由DCNN和CRF组成,训练策略是分段训练,即DCNN的输出是CRF的一元势函数,在训练CRF时是固定的。在对DCNN做了fine-tune后,对CRF做交叉验证,这里使用ω2=3ω2=3和σγ=3,σγ=3在小的交叉验证集上寻找最佳ω1,σα,σβω1,σα,σβ,采用从粗到细的寻找策略。
Version2
deeplabV2的prototxt deeplabV2模型
相对于Version1
- atrous方法改了一下
- 提出了ASPP方法
- 基础层从VGG16换成了ResNet
ASPP:
在给定的输入上以不同采样率的空洞卷积进行采样,相当于以多个比例捕捉图像的上下文。
在之前的多尺度版本处理中,浪费了大量的计算力和空间,该方法是收到SPPNet中的SPP模块的启发。
DeepLabv2的做法和SPPNet相似,并行的采用多个采样率的空洞卷积提取特征,再将特征融合,类似于空间金字塔结构,形象的称为Atous Spatial Pyramid Pooling(ASPP)。

在同一Input Feature Map的基础上,并行使用4个空洞卷积,r=6,12,18,24,核大小为3*3,最终将不同卷积层得到的结果做像素加融合在一起。

pool4后的空洞卷积为k=3,rate=2
layer {
name: "conv5_1"
type: "Convolution"
bottom: "pool4"
top: "conv5_1"
param {
lr_mult: 1
decay_mult: 1
}
param {
lr_mult: 2
decay_mult: 0
}
convolution_param {
num_output: 512
pad: 2
kernel_size: 3
dilation: 2
}
}Version3
相比于version2的变化:
- ASPP后加了BN层
- 没有使用CRF
- 复制了ResNet最后的block,并级联
- 使用了深层次的空洞卷积
首先添加BN层,因为我们发现随着采样率的增加,滤波器的有效权重在逐渐变小。当我们不同采样率3*3的卷积应用在65*65的特征映射上,当采样率接近特征映射大小时,3*3的滤波器不是捕捉全图像的上下文,而是退化为简单的1*1滤波器,只有滤波器的中心点权重起了作用,为了克服这个问题,我们考虑使用图片级特征。我们在模型最后的特征映射上应用全局平均,将结果经过1*1的卷积,再双线性上采样得到所需的空间纬度,最终我们改进的ASPP为:
- 一个1×11×1卷积和三个3×33×3的采样率为rates=6,12,18rates=6,12,18的空洞卷积,滤波器数量为256,包含BN层。针对output_stride=16的情况。如下图(a)部分
Atrous Spatial Pyramid Pooling - 图像级特征,即将特征做全局平均池化,经过卷积,再融合。如下图(b)部分
Image Pooling.


当空洞率较大时原来3*3卷积的9个参数只剩下中间参数有效,其他参数作用于前面feature层的padding部分,为无效参数,所以在rate变大时,3*3卷积退化成1*1卷积,所以这里的aspp去掉了rate=24的分支,增加了1*1卷积分支。另外,为了获得全局信息,加入了image pooling分支,其实这个分支做的操作就是将block4输出的feature进行全局池化,然后再双线性插值到与其他分支一样的分辨率。最后将五个分支连接,再做1*1卷积(通道数变化)。
Version3+
在本文中,使用了两种类型的神经网络,空间金字塔和encoder-decoder结构做语义分割

- (a): 即DeepLabv3的结构,使用ASPP模块获取多尺度上下文信息,直接上采样得到预测结果
- (b): encoder-decoder结构,高层特征提供语义,decoder逐步恢复边界信息
- (c): DeepLabv3+结构,以DeepLabv3为encoder,decoder结构简单
DeepLabV3+的整体结构:

简单说一下decoder的组成:
- encoder输出的feature的outputstride=16outputstride=16,经过双线性上采样4倍得到FAFA,FAFA的outputstride=4outputstride=4
- 再取encoder中对应着相同分辨率(即outputstride=4outputstride=4)的特征层,经过1×11×1卷积降通道,此时输出的feature记为FBFB。这里为什么要经过1×11×1卷积降通道,是因为此分辨率的特征通道较多(256或512),而FAFA输出只有256,故降通道以保持与FAFA所占比重,利于模型学习。
- 将FAFA和FBFB做concat,再经过一个3×33×3卷积细化feature,最终再双线性上采样4倍得到预测结果
encoder结构变化:
扩张分离卷积:
深度分离卷积,将标准卷积分解成深度卷积(depthwise convolution)和逐点卷积(pointwise convolution),我们对扩张卷积和深度卷积结合在一起,即扩张分离卷积,显著减少模型的计算复杂度并维持相似的表现。
与Xception不同的几点是:
- 层数变深了
- 所有的最大池化都被替换成了3x3 with stride 2 的separable convolution
- 在每个3x3 depthwise separable convolution的后面加了BN和ReLU
本文使用Xception的结构,在每个3*3的深度卷积后增加BN和ReLU,将此作为encoder网络主体,代替本来的ResNet101.
参考:
1.http://hellodfan.com/2018/01/22/%E8%AF%AD%E4%B9%89%E5%88%86%E5%89%B2%E8%AE%BA%E6%96%87-DeepLab%E7%B3%BB%E5%88%97/
2.http://hellodfan.com/2018/03/11/%E8%AF%AD%E4%B9%89%E5%88%86%E5%89%B2%E8%AE%BA%E6%96%87-DeepLabv3+/
3.https://zhangbin0917.github.io/2018/06/03/Encoder-Decoder-with-Atrous-Separable-Convolution-for-Semantic-Image-Segmentation/