使用NLP预测电影类型 - 多标签分类
Introduction
上周,我对这篇关于构建多标签图像分类模型的精彩文章很感兴趣。 我的数据科学家开始探索将这个想法转化为自然语言处理(NLP)问题的可能性。
那篇文章展示了计算机视觉技术来预测电影的类型。 所以我必须找到一种方法将该问题陈述转换为基于文本的数据。 现在,大多数NLP教程都着眼于解决单标签分类挑战(每次观察时只有一个标签)。
但电影不是一维的。 一部电影可以跨越多种类型。 现在,这是一个我喜欢接受数据科学家的挑战。 我提取了一堆电影情节摘要,并开始使用这种多标签分类的概念。 即使使用简单的模型,结果也确实令人印象深刻。

在本文中,我们将采用非常实用的方法来理解NLP中的多标签分类。 我使用NLP建立电影类型预测模型很有趣,我相信你也会这样做。 我们来挖掘吧!
目录
- 多标签分类简介
- 设置我们的多标签分类问题陈述
- 关于数据集
- 我们构建电影类型预测模型的策略
- 实现:使用多标签分类来构建电影类型预测模型(在Python中)
多标签分类简介
我很高兴你跳进代码并开始构建我们的类型分类模型。 然而,在我们这样做之前,让我向您介绍NLP中多标签分类的概念。 在深入实施之前首先了解该技术非常重要。
基本概念在名称中是显而易见的 - 多标签分类。 这里,实例/记录可以有多个标签,每个实例的标签数量不固定。
让我用一个简单的例子解释一下。 看看下面的表格,其中’X’代表输入变量,'y’代表目标变量(我们预测):
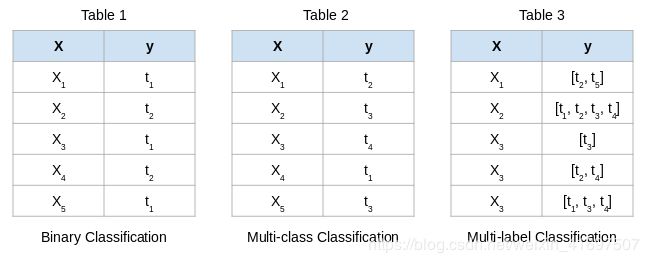
多标签分类
'y’是表1中的二进制目标变量。因此,只有两个标签 - t1和t2
'y’在表2中包含两个以上的标签。但是,请注意这两个表中每个输入只有一个标签
你必须猜到了表3引人注目的原因。 我们这里有多个标签,不仅在表格中,而且还有单独的输入
我们不能直接在这种数据集上应用传统的分类算法。 为什么? 因为这些算法希望每个输入都有一个标签,所以我们有多个标签。 这是一个有趣的挑战,我们将在本文中解决这个挑战。
您可以在下面的文章中更深入地了解多标签分类问题:
Solving Multi-Label Classification Problems (using Case Studies)
Setting up our Multi-Label Classification Problem Statement
有建立推荐引擎的几种方法。 在电影类型方面,您可以根据多个变量对数据进行切片和切块。 但这是一个简单的方法 - 构建一个可以自动预测流派标签的模型! 我已经可以想象为推荐者添加这样一个选项的可能性。 对每个人来说都是双赢的。
我们的任务是建立一个模型,只使用情节细节(以文本形式提供)来预测电影的类型。
从IMDb看下面的快照,然后选择展出的不同内容:
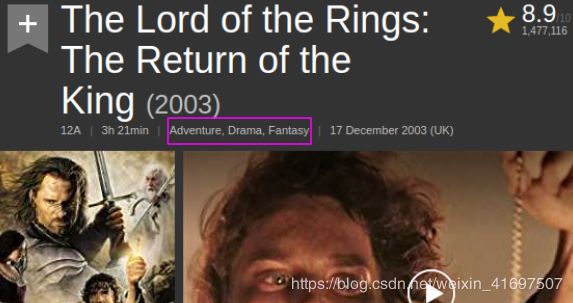
在这么小的空间里有很多信息:
- 电影标题
- 右上角的电影评级
- 电影总持续时间
- 发布日期
- 当然,我在洋红色彩色边框中突出显示的电影类型
类型告诉我们电影的期待。 由于这些类型是可点击的(至少在IMDb上),它们允许我们发现其他类似的同类电影。 看起来像一个简单的产品功能突然有这么多有希望的选择。?
About the Dataset
我们将为我们的项目使用CMU电影摘要语料库开放数据集。 您可以直接从link下载数据集。
此数据集包含多个文件,但我们现在只关注其中两个文件:
movie.metadata.tsv:从2012年11月4日Freebase转储中提取的81,741部电影的元数据。 电影类型标签在此文件中可用
plot_summaries.txt:从2012年11月2日英语维基百科翻新中提取的42,306部电影的摘要。 每行包含维基百科电影ID(索引到movie.metadata.tsv),然后是剧情摘要
Our Strategy to Build a Movie Genre Prediction Model(构建电影类型预测模型的策略)
我们知道我们不能直接在多标签数据集上使用监督分类算法。 因此,我们首先必须转换目标变量。 让我们看看如何使用虚拟数据集执行此操作:
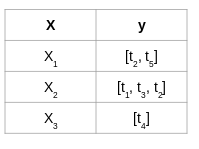
这里,X和y分别是特征和标签 - 它是一个多标签数据集。 现在,我们将使用** Binary Relevance **方法来转换目标变量y。 我们将首先在数据集中取出唯一标签:
唯一标签= [t1,t2,t3,t4,t5]
数据中有5个唯一标记。 接下来,我们需要用多个目标变量替换当前目标变量,每个变量都属于数据集的唯一标签。 由于有5个唯一标签,因此将有5个新的目标变量,其值为0和1,如下所示:
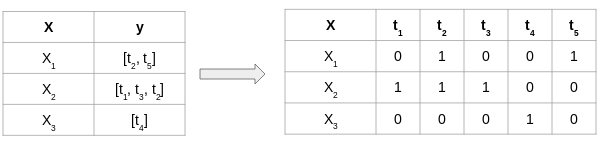
我们现在已经覆盖了最终开始解决这个问题的必要基础。 在下一节中,我们将最终使用Python制作自动电影类型预测系统!
Implementation:使用多标签分类构建电影类型预测模型(Python)
我们已经理解了问题陈述并构建了一个逻辑策略来设计我们的模型。 让我们把它们放在一起并开始编码!
导入所需的库
我们将首先导入项目所需的库:
import pandas as pd
import numpy as np
import json
import nltk
import re
import csv
import matplotlib.pyplot as plt
import seaborn as sns
from tqdm import tqdm
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
%matplotlib inline
pd.set_option('display.max_colwidth', 300)
Load Data
我们先加载电影元数据文件。 使用’\ t’作为分隔符,因为它是制表符分隔文件(.tsv):
meta = pd.read_csv("movie.metadata.tsv", sep = '\t', header = None)
meta.head()
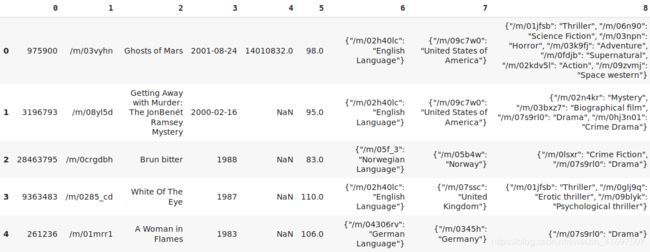
哦等等 - 这个数据集中没有标题。 第一列是唯一的电影ID,第三列是电影的名称,最后一列是电影类型。 我们不会在此分析中使用其余列。
让我们为上述三个变量添加列名:
# rename columns
meta.columns = ["movie_id",1,"movie_name",3,4,5,6,7,"genre"]
现在,我们将电影情节数据集加载到内存中。 此数据以文本文件形式出现,每行包含电影ID和电影情节。 我们将逐行阅读:
plots = []
with open("plot_summaries.txt", 'r') as f:
reader = csv.reader(f, dialect='excel-tab')
for row in tqdm(reader):
plots.append(row)
接下来,将影片ID和绘图分成两个单独的列表。 我们将使用这些列表来形成数据帧:
movie_id = []
plot = []
# extract movie Ids and plot summaries
for i in tqdm(plots):
movie_id.append(i[0])
plot.append(i[1])
# create dataframe
movies = pd.DataFrame({'movie_id': movie_id, 'plot': plot})
让我们看看我们在’电影’数据帧中有什么:
movies.head()
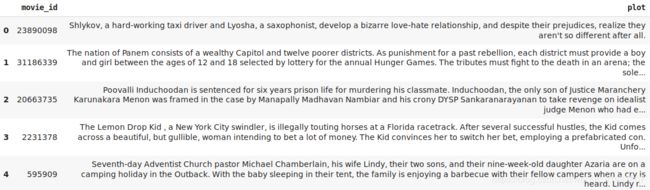
完善! 我们有电影ID和相应的电影情节。
数据探索和预处理
让我们根据movie_id列将后者合并到前者中,从电影元数据文件中添加电影名称及其类型:
# change datatype of 'movie_id'
meta['movie_id'] = meta['movie_id'].astype(str)
# merge meta with movies
movies = pd.merge(movies, meta[['movie_id', 'movie_name', 'genre']], on = 'movie_id')
movies.head()
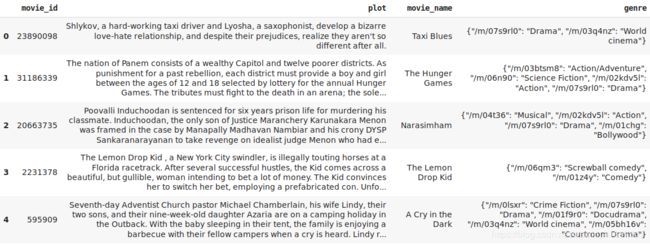
我们添加了电影名称和流派。 但是,这些类型采用字典表示法。 如果我们可以将它们转换为Python列表,那么使用它们会更容易。 我们将使用第一行执行此操作:
movies['genre'][0]
Output:
'{"/m/07s9rl0": "Drama", "/m/03q4nz": "World cinema"}'
我们不能通过使用.values()来访问此行中的类型。 你能猜到为什么吗? 这是因为这个文本是一个字符串,而不是一个字典。 我们必须将此字符串转换为字典。 我们将在这里借助json库:
type(json.loads(movies['genre'][0]))
Output:
dict
我们现在可以轻松访问此行的类型:
json.loads(movies['genre'][0]).values()
Output:
dict_values(['Drama', 'World cinema'])
此代码可帮助我们从电影数据中提取所有类型。 完成后,将提取的类型作为列表添加回电影数据帧:
# an empty list
genres = []
# extract genres
for i in movies['genre']:
genres.append(list(json.loads(i).values()))
# add to 'movies' dataframe
movies['genre_new'] = genres
某些示例可能不包含任何类型标记。 我们应该删除这些样本,因为它们不会参与我们的模型构建过程:
# remove samples with 0 genre tags
movies_new = movies[~(movies['genre_new'].str.len() == 0)]
movies_new.shape, movies.shape
Output:
((41793, 5), (42204, 5))
只有411个样本没有类型标签。 让我们再看看数据帧:
movies.head()

请注意,类型现在采用列表格式。 您是否想知道此数据集中涵盖了多少电影类型? 以下代码回答了这个问题:
# get all genre tags in a list
all_genres = sum(genres,[])
len(set(all_genres))
Output:
363
我们的数据集中有超过363种独特的流派标签。 这是一个相当大的数字。 我能够回想起5-6种类型! 让我们看看这些标签是什么。 我们将使用nltk库中的FreqDist()创建一个类型字典及其在数据集中的出现次数:
all_genres = nltk.FreqDist(all_genres)
# create dataframe
all_genres_df = pd.DataFrame({'Genre': list(all_genres.keys()),
'Count': list(all_genres.values())})
我个人觉得可视化数据是一种比简单输出数字更好的方法。 那么,让我们绘制电影类型的分布:
g = all_genres_df.nlargest(columns="Count", n = 50)
plt.figure(figsize=(12,15))
ax = sns.barplot(data=g, x= "Count", y = "Genre")
ax.set(ylabel = 'Count')
plt.show()
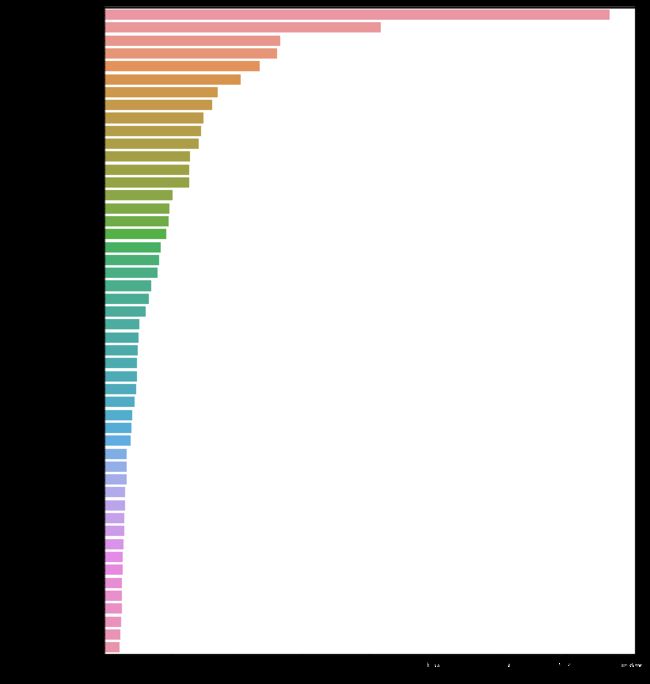
接下来,我们将清理一下我们的数据。 我将使用一些非常基本的文本清理步骤(因为这不是本文的重点领域):
# function for text cleaning
def clean_text(text):
# remove backslash-apostrophe
text = re.sub("\'", "", text)
# remove everything except alphabets
text = re.sub("[^a-zA-Z]"," ",text)
# remove whitespaces
text = ' '.join(text.split())
# convert text to lowercase
text = text.lower()
return text
让我们使用apply-lambda duo在电影情节中应用这个功能:
movies_new['clean_plot'] = movies_new['plot'].apply(lambda x: clean_text(x))
随意检查新旧电影情节。 我在下面提供了一些随机样本:

在clean_plot列中,所有文本都是小写的,并且也没有标点符号。 我们的文字清洁工作就像一个魅力。
下面的函数将在一组文档中显示单词及其频率。 让我们用它来找出电影情节列中最常用的单词:
def freq_words(x, terms = 30):
all_words = ' '.join([text for text in x])
all_words = all_words.split()
fdist = nltk.FreqDist(all_words)
words_df = pd.DataFrame({'word':list(fdist.keys()), 'count':list(fdist.values())})
# selecting top 20 most frequent words
d = words_df.nlargest(columns="count", n = terms)
# visualize words and frequencies
plt.figure(figsize=(12,15))
ax = sns.barplot(data=d, x= "count", y = "word")
ax.set(ylabel = 'Word')
plt.show()
# print 100 most frequent words
freq_words(movies_new['clean_plot'], 100)
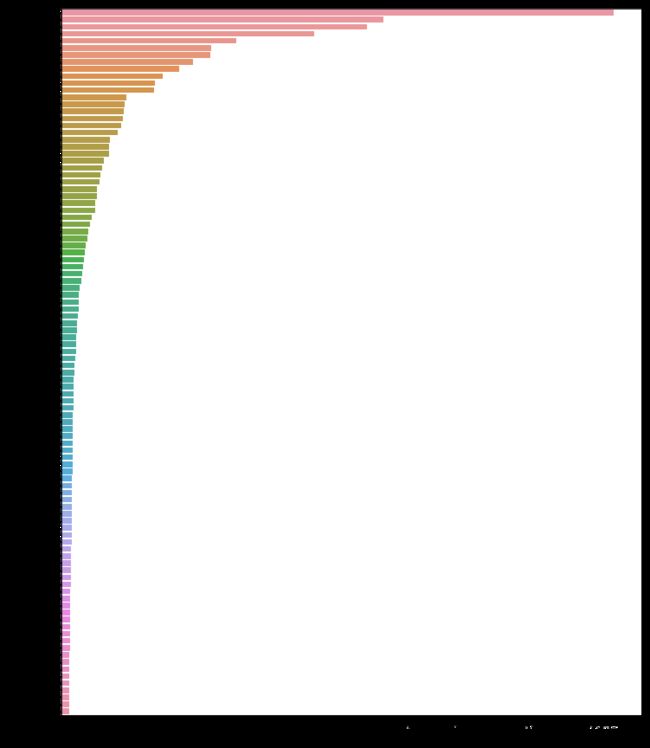
上图中的大多数术语都是停用词。 这些停用词比文本中的其他关键词具有更少的含义(它们只是为数据添加噪声)。 我将继续将它们从剧情文本中删除。 您可以从nltk库下载停用词列表:
nltk.download('stopwords')
让我们删除停用词:
from nltk.corpus import stopwords
stop_words = set(stopwords.words('english'))
# function to remove stopwords
def remove_stopwords(text):
no_stopword_text = [w for w in text.split() if not w in stop_words]
return ' '.join(no_stopword_text)
movies_new['clean_plot'] = movies_new['clean_plot'].apply(lambda x: remove_stopwords(x))
检查最常用的术语没有停用词:
freq_words(movies_new['clean_plot'], 100)
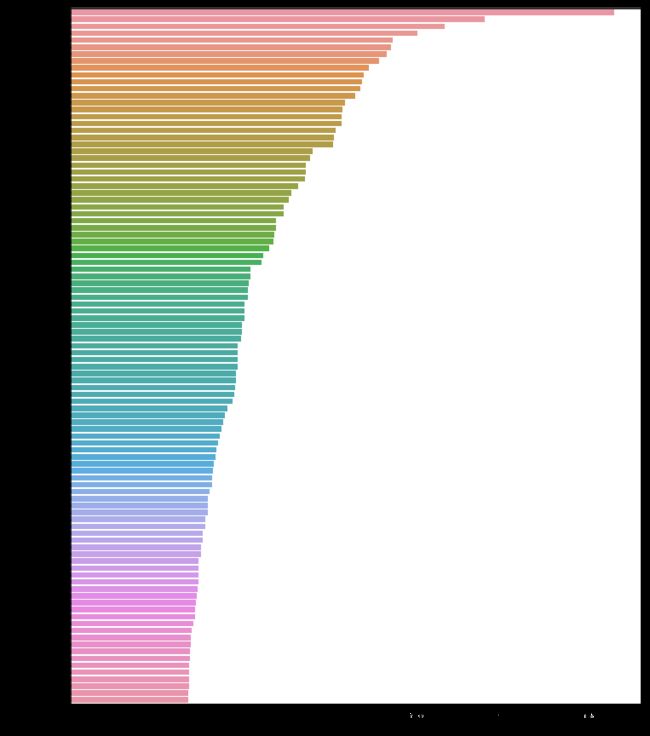
看起来好多了,不是吗? 现在出现了更多有趣和有意义的词,如“警察”,“家庭”,“钱”,“城市”等。
将文本转换为函数
我之前提到过,我们会将这个多标签分类问题视为二元关联问题。 因此,我们现在将通过使用sklearn的MultiLabelBinarizer()对目标变量进行热编码,即genre_new。 由于有363个独特的流派标签,因此将有363个新的目标变量。
from sklearn.preprocessing import MultiLabelBinarizer
multilabel_binarizer = MultiLabelBinarizer()
multilabel_binarizer.fit(movies_new['genre_new'])
# transform target variable
y = multilabel_binarizer.transform(movies_new['genre_new'])
现在,是时候将注意力转移到从清理版的电影情节数据中提取特征了。 对于本文,我将使用TF-IDF功能。 您可以随意使用其他任何您熟悉的特征提取方法,例如Bag-of-Words,word2vec,GloVe或ELMo。
我建议查看以下文章,以了解有关从文本创建功能的不同方法的更多信息:
An Intuitive Understanding of Word Embeddings: From Count Vectors to Word2Vec
A Step-by-Step NLP Guide to Learn ELMo for Extracting Features from Text
tfidf_vectorizer = TfidfVectorizer(max_df=0.8, max_features=10000)
我在数据中使用了10,000个最常用的单词作为我的功能。 您也可以尝试使用max_features参数的任何其他数字。
现在,在创建TF-IDF功能之前,我们会将数据拆分为训练集和验证集,以便进行培训和评估模型的性能。 我将使用80-20分割 - 火车组中80%的数据样本,其余的在验证集中:
# split dataset into training and validation set
xtrain, xval, ytrain, yval = train_test_split(movies_new['clean_plot'], y, test_size=0.2, random_state=9)
现在我们可以为训练和验证集创建功能:
# create TF-IDF features
xtrain_tfidf = tfidf_vectorizer.fit_transform(xtrain)
xval_tfidf = tfidf_vectorizer.transform(xval)
Build Your Movie Genre Prediction Model
我们都为模型构建部分设置了! 这就是我们一直在等待的。
请记住,我们必须为每个热门编码的目标变量构建一个模型。 由于我们有363个目标变量,我们必须使用相同的预测变量(TF-IDF特征)来拟合363个不同的模型。
可以想象,在适度的系统上训练363个模型可能需要相当长的时间。 因此,我将建立一个Logistic回归模型,因为它可以快速训练有限的计算能力:
from sklearn.linear_model import LogisticRegression
# Binary Relevance
from sklearn.multiclass import OneVsRestClassifier
# Performance metric
from sklearn.metrics import f1_score
我们将使用sk-learn的OneVsRestClassifier类将此问题解决为二元相关性或一对一问题:
lr = LogisticRegression()
clf = OneVsRestClassifier(lr)
最后,将模型设置在训练集上:
# fit model on train data
clf.fit(xtrain_tfidf, ytrain)
预测验证集上的电影类型:
# make predictions for validation set
y_pred = clf.predict(xval_tfidf)
让我们看看这些预测的样本:
y_pred[3]

它是长度为363的二进制一维数组。基本上,它是唯一类型标签的单热编码形式。 我们必须找到一种方法将其转换为电影类型标签。
幸运的是,sk-learn再次来到我们的救援。 我们将使用inverse_transform()函数和MultiLabelBinarizer()对象将预测数组转换为电影类型标记:
multilabel_binarizer.inverse_transform(y_pred)[3]
Output:
('Action', 'Drama')
哇! 那很顺利。
但是,要评估模型的整体性能,我们需要考虑验证集的所有预测和整个目标变量:
# evaluate performance
f1_score(yval, y_pred, average="micro")
Output:
0.31539641943734015
我们得到了一个不错的F1得分0.315。 这些预测是基于阈值0.5进行的,这意味着大于或等于0.5的概率被转换为1,其余的被转换为0。
让我们尝试更改此阈值,看看是否可以改善我们的模型得分:
# predict probabilities
y_pred_prob = clf.predict_proba(xval_tfidf)
现在设置一个阈值:
t = 0.3 # threshold value
y_pred_new = (y_pred_prob >= t).astype(int)
我已经尝试过0.3作为阈值。 您还应该尝试其他值。 让我们再次检查这些新预测的F1分数。
# evaluate performance
f1_score(yval, y_pred_new, average="micro")
Output:
0.4378456703198025
这对我们模型的性能起到了很大的推动作用。 找到正确阈值的更好方法是使用k倍交叉验证设置并尝试不同的值。
Create Inference Function
等等 - 我们还没有完成这个问题。 我们还必须处理将来出现的新数据或新电影情节,对吧? 我们的电影类型预测系统应该能够以原始形式拍摄电影情节作为输入并生成其类型标签。
为此,让我们构建一个推理函数。 它将拍摄电影情节文本并按照以下步骤操作:
- 清理文字
- 从已清理的文本中删除停用词
- 从文本中提取功能
- 作出预测
- 返回预测的电影类型标签
def infer_tags(q):
q = clean_text(q)
q = remove_stopwords(q)
q_vec = tfidf_vectorizer.transform([q])
q_pred = clf.predict(q_vec)
return multilabel_binarizer.inverse_transform(q_pred)
让我们在我们的验证集中的几个样本上测试这个推理函数:
for i in range(5):
k = xval.sample(1).index[0]
print("Movie: ", movies_new['movie_name'][k], "\nPredicted genre: ", infer_tags(xval[k])), print("Actual genre: ",movies_new['genre_new'][k], "\n")

好极了! 我们已经建立了一个非常有用的模型。 该模型尚不能预测罕见的流派标签,但这是另一个时间的挑战(或者你可以接受并让我们知道你所遵循的方法)。
从这往哪儿走?
如果您正在寻找类似的挑战,您会发现以下链接很有用。 我在自然语言处理课程中使用机器学习和深度学习模型解决了Stackoverflow问题标记预测问题。
以下是课程链接供您参考:
Certified Program: NLP for Beginners
The Ultimate AI & ML BlackBelt Program
End Notes
我希望我们的社区能够看到不同的方法和技术,以取得更好的结果。 尝试使用不同的特征提取方法,构建不同的模型,微调这些模型等。你可以尝试很多东西。 不要在这里阻止自己 - 继续尝试!
欢迎在下面的评论部分讨论和评论。 完整的代码可以在这里找到。