为什么要用时序数据库?
很凑巧,我们在上一篇浅谈数据存储文章中,谈到了时序数据库,最近我们的项目中正好用到了现在很火的时序数据库TDengine,所以在这里,顺便和大家分享一下我在学习以及使用时序数据库的一些心得。
在大数据的背景下,如果我们将数据类型进行细分,每个细分类型的数据都会有一定的存储优化空间,主要是看这个优化有没有新增一套细分类型数据的处理方案来的更有价值(当然如果我们的系统只有某一种细分类型的数据,那么选择细分类型的处理方案会好很多) (来自我的瞎总结)
时序数据就是大数据背景下一种数据类型的细分,由于物联网时代的到来,时序数据的总量越来越多,专门针对于时序数据类型的处理方案不断浮现,它们被称为时序数据库,下面,我们就开始揭开时序数据库的神秘面纱吧!
下面,我们主要是通过这几个方面聊聊:
1.时序数据的特点以及大数据背景下的可优化空间?
2.TDengine时序数据库的解决方案?
3.influxdb相对于TDengine在使用场景上又有什么区分(为什么TDengine的性能要比其他时序数据库高,为了高性能它牺牲了什么)?
1.时序数据的特点以及大数据背景下的可优化空间?
大数据时代已经到来了很多年,大数据解决方案基本成熟, Hadoop集群处理方案基本成为了一个处理大数据的最佳实践。他所处理的数据包含结构化,半结构化,非结构化的数据,通过Sqoop、Flume、kafka收集数据,通过hbase、hdfs存储数据、通过mapreduce、sparkstreaming等计算数据,最后通过hive作为数据仓库为应用层提供需要的数据。
这是一套通用的,综合的大数据解决方案。
那如果把数据类型细分一下,针对于大量的时序数据,我们应该怎么优化存储?
首先,什么是时序数据?
简单来说,时序数据就是按照时间维度索引的数据,比如车辆轨迹数据,传感器温度数据。随着物联网时代的到来,时序数据的数据量呈井喷式爆发,针对于这一数据细分的优化存储显得越来越重要。
那么时序数据有什么特点呢?针对于这些特点我们怎么去优化存储呢?
同样在浅谈数据存储文章中,我们简单并且不成熟的总结了一下时序数据库的特点以及解决方案,如下:
一般的时序数据都会有这几个属性:
度量的数据集,类似于关系型数据库中的 table;
一个数据点,类似于关系型数据库中的 row;
时间戳,表征采集到数据的时间点;
维度列,代表数据的归属、属性,表明是哪个设备/模块产生的,一般不随着时间变化,供查询使用;
指标列,代表数据的测量值,随时间平滑波动。
如下图所示的数据:
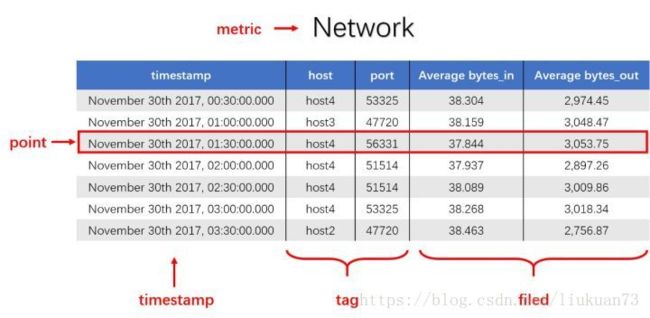
对于时序数据,我们总结了以下特点:
1.数据特点:数据量大,数据随着时间增长,相同维度重复取值,指标平滑变化(某辆车的某个设备上传上来平滑变化的轨迹坐标)。
2.写入特点:高并发写入,且不会更新(轨迹不会更新)。
3.查询特点:按不同维度对指标进行统计分析,存在明显的冷热数据,一般只会查询近期数据(一般我们只会关心近期的轨迹数据)。
针对特点可以有如下改进:
第一个特点,数据量大,相同维度重复取值,我们可以将这些相同的维度压缩存储(因为是重复的),减少存储成本,比如将重复的host和port只存储一份就好了。
第二个特点,高并发写入,和hbase一样,我们可以采用LSM代替B树
第三个特点,聚合以及冷热数据,我们可以对于冷数据降低精度存储,也就是对历史数据做聚合,节省存储空间。
乍一看是没有问题的,但是在我细细研究了时序数据库的原理之后,对此又有了新的理解。
首先对于第一个改进,我们完全可以将这些相同维度放到mysql等传统数据库中,然后每个维度生成一个唯一id,再将变化的指标数据和唯一id存储在hbase中,这样就不会存在相同维度重复存储的问题了,顶多是查询的时候多查一次mysql而已,在维度不多的情况下,完全是可以接受的①。
对于第二个改进就更不用说了,hbase完全满足。
第三个改进只是一个优化点,不能成为决定性因素。
那么时序数据库和传统的大数据存储解决方案到底有哪些本质区别呢?
我觉得最重要的区别就是结构化数据。
1.存储的是结构化数据。我们都知道传统的大数据方案要存储的数据包含结构化,半结构化,非结构化的数据,这样就决定了我们不能决定有哪些字段以及定义各个字段的数据类型,像hbase就是通过byte类型统一存储的,也就是说放到hbase中的数据都是byte数组,从普通类型转换成byte数组需要我们自己来做,我们并不知道怎样转换成byte它的存储效率会更高。但是时序数据产生的数据都是结构化的数据,我们可以事先定义好数据的字段以及类型,让数据库系统根据不同的字段类型选择最优的压缩方式,大大提高存储的利用率。
2.分析聚合的是结构化数据。既然分析聚合是结构化数据,那么我们就不需要使用mapreduce那种复杂的计算工具、一般也不需要hive那种数据仓库,而只需要在数据库存储层面内聚类似于sum、avg在这种计算工具就可以了,甚至还可以做一些简单的流式计算,为‘超融合’提供了基础(超融合就是说将类似于之前对于大数据处理方案的多个组件融合成一个组件,主要还是因为结构化数据太简单了,收集计算等都比较简单,这也是后续时序数据库的发展趋势,减少系统复杂度)。
2.TDengine时序数据库的解决方案(主要是和大数据方案做比较,因为传统的数据库在数据量大的情况下毫无用武之地)?
我们来粘贴一下TDengine官方文档对于数据模型的介绍:
数据模型:
因为采集的数据一般是结构化数据,而且为降低学习门槛,TDengine采用传统的关系型数据库模型管理数据。因此用户需要先创建库,然后创建表,之后才能插入或查询数据。
没错,TDengine就是需要先定义数据类型才能存储和查询数据。
其外,时序数据库还有一些通用的设计思想,这里我们拿TDengine来举例(就是大多数时序数据库都会遵循的)。
1.一个设备一张表,也就是说,将一个设备的数据存储到一块地方,这样查询的时候就可以连续查询,加快查询速度。当然这个表,可以动态创建的(相当于hbase强制性按设备分列簇,这也不算是什么技术创新,应该算是一种设计创新)。
2.有一个超级表,存储了设备的标签属性,就是我们在①处说的可以用mysql代替的存储,使用超级表有两个好处:第一如果没有其他需求可以不用mysql,增加系统复杂度,第二点就是可以将我们在业务系统中做的一些聚合操作移到数据库系统中去做,减少开发难度(比如上面的数据我们要查询host为host4的数据,那么在传统过程中,我们需要先在数据库中查询出host为4的设备有哪些,然后一个一个的去hbase里面查询数据,再去聚合,现在来看的话,时序数据库就可以帮助我们完成这一切)。
3.influxdb相对于TDengine在使用场景上又有什么区分,为什么性能会有很大区别?
influxdb对于tdengine设计思想上的核心区别:
核心区别:TDengine认为所有的数据都应该是有序上报,且没有更新和删除操作。 而 influxdb可以支持数据逆序上报,而且influxdb就像是CRud,支持ud,但是不建议ud。
主要因为这个思想,才会有tdengine存储和查询的优势。
首先,在存储的时候,tdengine认为数据是有序的,不更新和删除,所以在LSM从内存刷到磁盘的时候可以不使用复杂的compact(参照LSM的原理;influx compact 占用了cpu使用的20%左右,是一个很费力的操作),大大加快写入速度。
其次,在查询的时候,我们不需要考虑内存中的更新和删除语句,像上一篇我们讲到的hbase的LSM,我们就不需要再去查询全部storeFile,大大加快了查询速度。
最后,在聚合查询的时候,因为我们的数据是不变的,所以可以将不变的数据文件预聚合,比如2.3日存了一个车辆轨迹的文件,我们就可以预先知道这个文件经纬度的最大最小值,这样就会大大加快聚合查询速度。
其他还有一些小区别:
1.tdengine有个设计思想就是如果序列有多组采集量,每一组的采集频次是不一样的,需要对同一序列建多张表。这就说明每个表的多个列可以共用同一个时间戳,而不是每一列有一个时间戳。influxdb的设计思想是多组采集量可以在同一张表中,每个采集量都有时间戳标志,会加大存储。比如说 在车辆网系统中车辆的轨迹和温度是分开上报的,那么在tdengine的设计思想中,对于同一个设备需要建立两张表,每个表中的同一行的数据使用同一个时间戳标识(会造成成倍的表数量)。在influxdb中,轨迹和温度是在同一张表中,因为都是同一个设备的,那么同一行中的每个属性都需要一个时间戳去标识。
2.tdengine为了加快查询速度,将超级表放在了内存里,但是如果超级表过大(发生概率不大,因为设备量一般不会很大很大),内存中就会装不下,tdengine就会有问题,但是influxdb将 measurement(类似于超级表)存储在磁盘上,用倒排索引去查询,容量更大。
4.tdengine将大量的计算都移到了客户端,会加重客户端的负担,也会增加客户端的复杂度,不轻量,需要安装客户端。但是influxdb都在服务端进行计算(和tdengine restful方式相似)
经过上面的介绍,我们也就大概可以知道为什么TDengien对比influxdb的性能优势这么大了:
1. 写入性能5倍
2. 读取性能35倍 。
3. 聚合函数性能140倍
4. 标签分组性能250倍
5. 时间分组12倍
6. 压缩1.8倍
当然TDengine也有着自己的局限性,比如不是很好地支持逆序,不能更新和删除等等。
重要的还是要看使用场景。最后还是建议大家深入了解一下LSM模型,对于理解所有高并发写入的存储方案都有很大的帮助。
到这里就结束了,谢谢大家,如有问题,欢迎探讨。
另:
还有一些TDengine针对其数据模型独有的比较好的设计思想:
1.last文件的设计,可以减少数据的碎片化。(tdengine的刷盘机制有时间和空间两个条件,也就是说每隔一段时间或者说是达到一定存储大小就去刷盘,但是如果数据很稀疏,时间到了之后数据其实很少,就会造成很多小文件,不利于存储和查询,last文件就是用来存储这些小文件的,last文件最终还是会和内存文件合并成一个大的存储文件的)。
2.TDengine有一个针对于相同时间间隔数据的压缩方式,可以大大减少存储空间,原理就是数据时间间隔一致可以压缩时间戳,如果时间间隔一致的话,我们只需要定义一个开始时间戳,然后查询的时候,所有数据的时间戳都是可以推算出来的(比较局限)。
在使用tdengine的时候,我也发现了一些问题:
1.tdengine在安装的时候提示了只支持在使用systemd做进程服务管理的linux系统上安装,我也查过了,要使用systemd做进程管理系统必须是centos7以上或者ubuntu16.04以上的系统(如果要使用低版本,会遇见各种各样的坑) 并且是服务端和客户端都需要,所以要使用tdengine的话,就要有整个系统切换环境的思想准备。
2.tdengine不支持乱序插入,也就是说,要插入的数据必须按照时间戳顺序的,否则会丢弃掉,所以如果对于对数据有完整性要求的,就不太适合了(虽然后期可以通过import命令导入进去,但是如果数据乱序频繁发生的话,还是很耗费精力的)。
3.不支持更新和删除。
4.表数量太多导致的问题(超级表都是放在了内存里,如果设备过多,有可能内存会装不下。另外,官方测试,256G内存的机器上,建了8000万table,还没有发现任何性能问题 因此这也不算是什么大问题)。