PAF ----Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
论文简介
Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields ∗这篇论文用了一种不一样方法进行姿态估计,他的准确率现在可能感觉不高,后期我们会讲一下face++最新的夺冠coco比赛的论文,不过它提供了一种新的思路。
论文原文地址:http://download.csdn.net/download/lin_xiaoyi/10163688
论文比较好懂的源代码:http://download.csdn.net/download/lin_xiaoyi/10163706
论文介绍
pose estimation的挑战
1.图像中不知道有多少人,在什么位置,什么尺度
2. 人与人之间因接触,遮挡而变得复杂
3.实时性的要求,图像中的人越多,计算复杂度就越大
pipline
人体姿态估计一般的pipline是(top->down方法)
top->down方法的步骤是先生成一个person detection(行人检测器),然后把每个人在切割出来,进行pose estimation for each person
top-down方法存在的缺陷:
1.如果人离得很近的的话,行人检器容易检测不到,检测不到会导致精度变低
2.计算时间和人数有关,人越多越耗费时间
另外一种方法是bottom up 方法
bottom-up方法不存在以上两个问题,不过bottom-up不直接受益于global imformation ->关键是利用了other body parts and other people 的 contextual cues(上下文信息)
本文使用了bottom-up方法,但是没有忽略 global contextual imformation in the detection of parts and their association
论文实现步骤
1.首先生成一堆2D的confidence map S of part affinities 和一堆的2D vector fields L of part affinities
2.利用第一步生成的2D vector L 求 Part Affinity Field 然后求出 Part Association
3.最后求Multi-Person Parsing using PAFs—>把Multi-person parsing问题转换成graphs问题—>Hungarian algorithm(匈牙利算法)
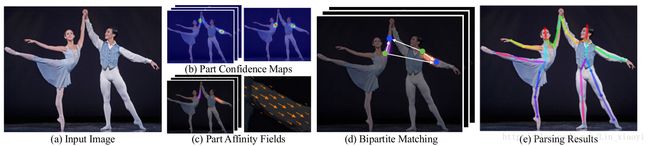
(原文)Overall pipeline. Our method takes the entire image as the input for a two-branch CNN to jointly predict confidence maps for body part detection, shown in (b), and part affinity fields for parts association, shown in (c). The parsing step performs a set of bipartite matchings to associate body parts candidates (d). We finally assemble them into full body poses for all people in the image (e).
论文方法
train
input: a colors images of size w*h
output: the 2D locations of anatomical keypoints for each person in the image
网络结构
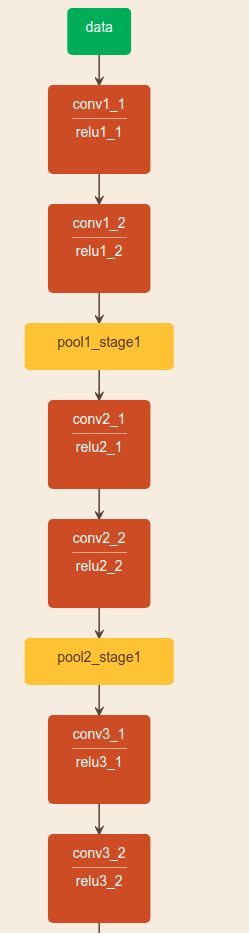
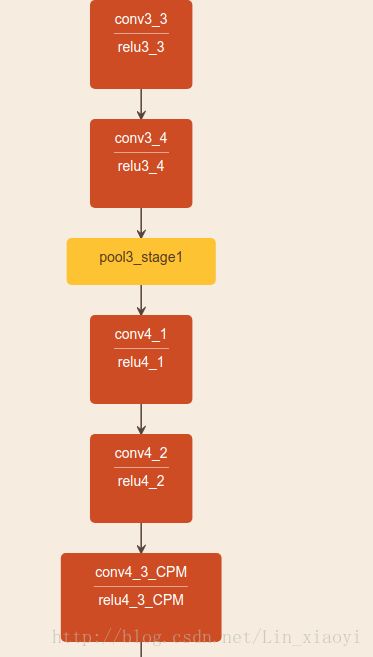
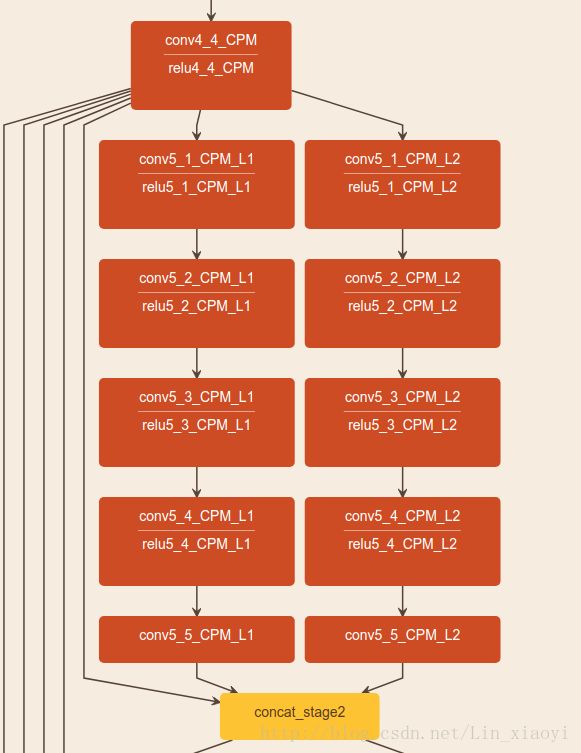
网络详解
图片先进行一个卷积神经网络(利用VGG19的前十层和fineturned),得到一些feature maps F,然后把这个feature maps 扔进第一个stage ,每个stage包含两个branch,第一个stage中的branch1产生了a set of detection confidence maps S,branch2产生了a set of part affinity fields L.在第前一个stage的基础上,第二个stage的输入就是original images features F+前一个stage的输出。以此循环。 ![]()
![]()
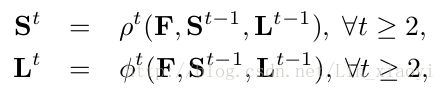
where ρ t and φ t are the CNNs for inference at Stage
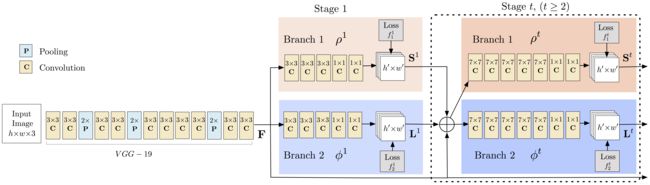
Architecture of the two-branch multi-stage CNN. Each stage in the first branch predicts confidence maps S t , and each stage in the second branch predicts PAFs L t . After each stage, the predictions from the two branches, along with the image features, are concatenated for next stage.
计算Loss
本文计算prediction 和 groundtruth part 之间的loss用的还是L2loss,两个branch都是计算L2 loss 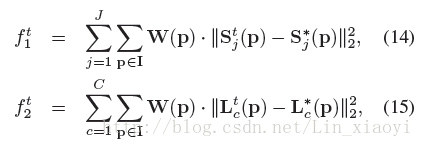
是第t个stage中的j个预测的confidence maps,
是第t个stage中的j个groundtruth的confidence maps,
是第t个stage中的c个degree of association(两个部位的联系程度)
是第t个stage中的groundtruth part affinity vector field.
loss方程有一个空间上的加权weight spatially,是因为有些数据集并没有完全标记所有的人,用其提供的mask说明有些区域可能包含unlabeled的人。
W是一个binary mask ,在没标记的位置W为0。
The mask is used to avoid penalizing the
true positive predictions during training. The intermediate supervision at each stage addresses the vanishing gradient problem by replenishing the gradient periodically [31].
总的loss是branch1 和branch2 loss的和: 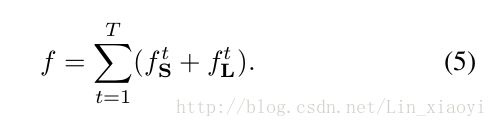
Confidence map 和 Part Associaton
上文我们说了
1.branch1是产生S的网络ρ,输出一个S的集合S =(S 1 , S 2 , …, Sn) ,n表示人身上的第n个部位,如:脖子,对于S的每个元素都是一个图片大小的集合,S的意义理解为对于人身体的属于每一个部位的概率为何。
2.branch2 是产生L的网络φ,输出一个L的集合L = (L 1 , L 2 , …, Ln ), n表示人身体的第n个链接,如:脖子与胸部,对于L的每个元素都是一个图片大小*2的集合,L的意义可以理解为对于人身体的每一链接的单位向量表示(比较抽象,后面详说)。
为了更好的解释网络的运作,在这我先解释下label的设定: 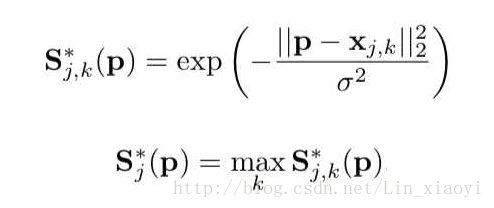
对于S的label,有如上两个公式,其中(P为当前的预测图片locationp,p ∈ R 2,
为对于第k个人第j个部位的位置,σ为一常量(为了不让太多非常小的数字压垮训练而设定,个人使用1e+2,效果还行)),对于如上第一个公式的解释就是对于当前位置(x,y)与第k个人的第j个部位越近这个位置的分数越高,然后第二个公式表示对K取max意思就是不在乎是哪一位的第j部位,找分最高的一个就好了。S这个set 被作者称为confidence map。
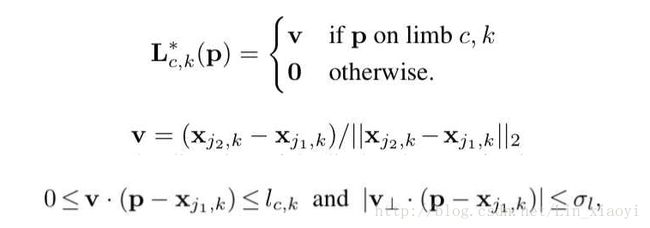
对于L的label,首先解释第一个公式,对于当前的位置P,如果P在第k个人的第c个链接上那么对于p这个位置的label就取这个链接的单位向量,否则就取0.第二个公式就是向量除膜长求单位向量的公式,第三个公式就是在讨论P是否在这一链接c上的标准。
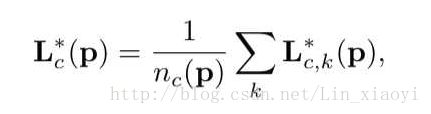
后一部分作者是在讨论一个问题,如果出现一个点p,同时存在于两个人的同一部位如何处理,作者的做法是取avg,暴力了点,但是这个情况实属少见,所以无伤大雅。取完label了,下一步就是讨论如何测试这个模型的问题。

对于这一部分的公式先看第二个,第二个简化一下不难看出u取0时p(u)=dj1,这个公式的意义在于取不同的u让p点在dj1与dj2之间移动。然后看第一个公式,对u在0~1之间取线积分,或者取离散求和,对于j1与j2两个点之间取离散,如5个点,放入产生L的网络将会产生5个单位向量,这5个单位向量表示链接的趋势(在label中设定的),对于这五个单位向量分别与j1与j2之间做内积,如果这两个之间存在连接就期望趋近于最大的值为5。如此取一个最大E就是该链接的两点了。
在test时,confidence score的计算方法:
计算预测的PAF(vector)与candidate limb 方向的alignment (方向是否一致,用点积计算)。
During testing, we measure association between candidate part detections by computing the line integral over the corresponding PAF, along the line segment connecting the candidate part locations. In other words, we measure the alignment of the predicted PAF with the candidate limb that would be formed by connecting the detected body parts. Specifically, for two candidate part locations d j 1 and d j 2 , we sample the predicted part affinity field, L c along the line segment to measure the confidence in their association:
Multi-Person Parsing using PAFs
这部分讲在得到了confidence map 和 part affinity fields后如何进行推理分析,也就是所谓的bottom-up算法。
先定义一些表达:
假设通过对confidence map进行极大值抑制,得到多个body part,每个body part 有多个detection candidate。 (图像中有多人,所以会有多个detection candidate)。
假设![]() 是第j个body part 的第m 个detection candidate的location.
是第j个body part 的第m 个detection candidate的location.
下面的z表示连接关系,目的是找到最优的可能连接方式。
找到两两body part 之间最优连接的问题:
就变成了a maximum weight bipartite graph matching 的问题
关于maximum weight bipartite graph matching problem:可参考http://www.csie.ntnu.edu.tw/~u91029/Matching.html 来理解概念
本paper使用Hungarian algorithm是链接中的匈牙利演算法。具体参考http://blog.csdn.net/u011837761/article/details/52058703
后面其他的一些细节就不详细说了,自己看论文原文去吧
本博客参考了:http://blog.csdn.net/yengjie2200/article/details/68064095
https://zhuanlan.zhihu.com/p/31505485