论文阅读CENet-Detecting Text in the Wild with Deep character Embedding Network
论文名称: Detecting Text in the Wild with Deep character Embedding Network
论文原文:原文链接
概览
本文提出了一个字符嵌入网络CENet。通过字符的检测和聚类分组,完成任意形状文本(水平、倾斜、曲文)的检测。
步骤:
- 运行CENet,得到字符候选集合+字符对候选集合
- 利用分数阈值s过滤非字符噪声
- 对每个字符运用r-KNN,查找local的character pairs,得到character group字符组
- 使用piecewise linear model(分段线性模型)来得到character group的最外接任意多边形
亮点
检测单个字符,而不是检测整个文本,然后将文字的字符合并问题转成字符embedding问题,利用一个网络来学习字符间的连接关系。
CENet模型结构
网络设计
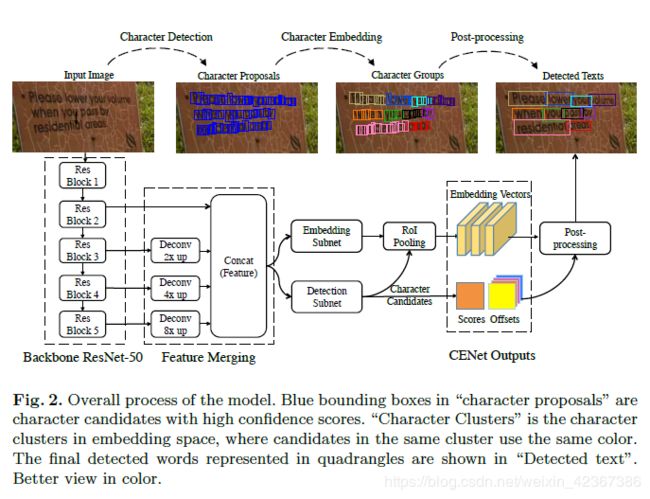
模型采用ResNet-50作为骨干网络 ,对三、四、五阶段的特征图进行反卷积,上采样到第二阶段的特征图大小(即原始图像的1/4),然后进行特征图的concat连接;
之后是两个主要的模块:(这两个模块共享骨干CNN网络)
- 字符检测模块:完成检测单个字符的任务,从而得到候选字符
- 字符嵌入模块:将检测到的字符映射到嵌入空间,生成每个字符的嵌入向量
字符检测子网
字符检测子网是一个卷积网络,产生5个通道作为最终输出。通道设置分别为字符框的左上和右下的x、y坐标偏移和置信度得分,检测到的候选字符的左上和右下边界框坐标可以通过(x-Δxtl,y-Δytl)和(x +Δxbr,y +Δybr)计算,其中x和y是得分大于一定阈值的像素坐标。
字符嵌入子网
在残差卷积单元RCU模块之后,我们采用具有线性激活函数的1x1卷积层来输出128通道嵌入图,然后对嵌入图进行1*1的RoI pooing输出每个字符提取嵌入向量。
推断与后处理
在推断阶段,我们从模型提取到置信度得分图、坐标偏移图、嵌入图。在得分图上进行阈值处理并对字符框执行NMS处理,通过嵌入图上1×1的RoI Poling来提取嵌入向量。
最后,我们输出格式为**{得分,字符中心的坐标(x,y),宽度,高度,128D嵌入向量}**的候选字符。
最后经过后处理步骤,将字符聚类到文本块中。
训练字符检测器
定义损失函数
采取多任务损失函数,包含文本/非文本二值分类损失和box回归的损失
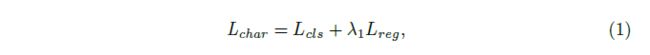
难例挖掘:我们将采样率设置为1:3以平衡正样本和负样本。
这里采用IOU损失作为回归损失,它处理大小物体之间的边界框精度偏差问题而不是采用L2损失。
标签制作——从粗略标签中学习字符检测器

基于出发点:**近似水平(或垂直)文本的短边大约等于其中字符的高度(或宽度)。**短边可用于以下步骤纠正不精确的预先确定的字符。
首先,每个标签的四边形或多边形沿中心线均匀地划分为N个边界框,其中N表示字符编号。我们将初步边界框分割称为粗糙字符框(即coarse_char框)。
之后,收集一些具有高置信度的候选字符框作为预测字符框(称为pred-char框)。
最后,精细字符框(即fine-char框)由粗糙字符框及其相应的匹配的预测字符框生成。
生成规则:
- 如果没有匹配的pred-char框,则粗char框直接用作fine-char框。
- 有匹配的情况下:如果带注释的文本更倾向于水平,则将fine-char框的宽度设置为pred-char框的宽度,并将高度设置为粗char框的高度;
- 如果带注释的文本更倾向于垂直,则将fine-char框的高度设置为pred-char框的高度,并将宽度设置为粗char框的宽度;
coarse_char框c与pred-char框p相匹配,应满足以下约束:
其中S(p)表示pred-char框的置信得分,IoU(p,c)表示coarse_char框c与pred-char框p的IOU。 在我们的实验中,t1和t2预先定义为0.2和0.5。
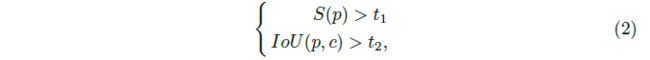
获得的fine-char框在计算损失时,作为真实值(即标签),更新模型。
学习字符嵌入
出发点:同一文本中的字符之间的距离在学习空间中较小,而属于不同文本的字符之间的距离较大。
因此,我们可以通过在嵌入空间中执行聚类来将字符分组为文本块。
定义损失函数
选择对比损失函数来训练我们的模型。令i和j表示一对候选字符的索引,vi和vj表示由嵌入子网提取的嵌入向量,l_i,j表示它们是否属于同一文本单元。如果pair(i,j)为正对,则l_i,j = 1;如果pair(i,j)为负对,则l_i,j = 0。
对比损失函数定义为
![]()
其中D表示距离。在训练中,如果l_i,j = 1,则将vi和vj拉近彼此。如果l_i,j = 0,则将vj和vi彼此推开直到D(vi,vj)> 1。
构建本地字符对
但是,如果两个字符分别位于一行文本的端点上,则它们属于同一文本行的概率应当显着增加。针对这种情况,通过构建本地字符对,将属于一个文本的稀疏分散的单个字符连接在一起。
在构建本地字符对时,我们使用有半径约束的kNN(r-KNN)。
具体的,每个候选字符依次被选为锚anchor。定义图像中字符i的中心坐标c_i,宽度w_i和高度h_i;KNN(i)表示字符i的k个最近邻居的集合。当j∈KNN(i)并且距离![]() 时,j∈r-KNN(i,βr(i))。在我们的实验中,k和β都设定为5。
时,j∈r-KNN(i,βr(i))。在我们的实验中,k和β都设定为5。
当j∈r-KNN(i)时,我们称i和j产生一个局部连接对。所有局部连接对的集合LCP ={(i; j):i∈M;j∈r-KNN(i)},其中M是一个图像中候选字符的集合。
基于以下分析,在训练时负对的权重应该比正对大。
- 无差错正对的最低要求是至少有一条链连接到文本单元中的所有字符。因此只要满足最低要求,具有大嵌入距离的正对不会产生损失的
- 具有较小嵌入距离的负对肯定会错误连接到两个文本单元并产生损失。
- 在本地字符对集合LCP中,大约有3/4是正对的(作者统计结果发现)
因此,我们从一批图像的LCP中采样R对,使得一个batch中有α对为负。(本文中设置R = 1024和α= 60%)。采样后得到SP,训练字符嵌入的加权重加权损失定义如下:
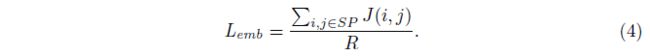
从而得到整个网络的损失函数
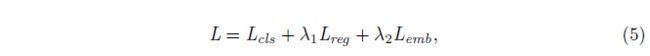
其中λ1和λ2控制损失之间的平衡。 我们在实验中将λ1和λ2都设置为1。
后处理
在测试中,我们使用两个阈值(s和d)来过滤错误的候选字符,并将字符组合成文本单元。
在前向传递之后,所提出的模型将得到一组候选字符及其相应的嵌入向量。然后,保留置信度大于s的的候选字符。接下来,对每个字符执行r-KNN,输出整个图像中的局部字符对。为了解决字符分组问题,我们简单地减少了嵌入距离超过d的连接对。
按照上述步骤,我们可以找到属于同一文本的字符。最后使用的WordSup中的piecewise linear model来形式化字符组的文本框。
piecewise linear model—分段线模型

对于每一个字符组,可以用3个复杂度的line model(0-order 、1-order models、Piecewise linear model)去构造文本框。0-order 模型构造水平或者竖直的文本框。1-order模型构造任意角度的倾斜文本框。Piecewise linear model构造多边形文本框。
文本框是可表示为一组中心线![]() 和一个高度值h,l_i=(a_i,b_i,c_i)代表为a_ix+b_iy+c_i=0的直线。对于0-order和1-order模型,用全部的字符中心坐标估计一个直线即可。
和一个高度值h,l_i=(a_i,b_i,c_i)代表为a_ix+b_iy+c_i=0的直线。对于0-order和1-order模型,用全部的字符中心坐标估计一个直线即可。
对于Piecewise linear model为每一个字符分别估计中心线。用k=min(n,11)个近邻坐标点估计中心线,其中(n=N为字符个数)。高度h为
![]()
其中P为所有字符的顶点坐标,d(P, l_i)为p到直线l_i的距离。
模型M的选择为最小化
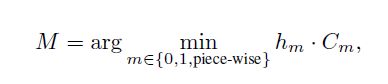
h_m为模型m的高度,越小说明拟合越好。C_m为模型m的复杂度惩罚,0-order、1-order和piecewise linear model对应为1、1.2、1.4。
计算多边形的文本框。每一个字符估计两个control point,对称落在中心线两边,两点连线过字符中心点。Control point为多边形边缘顶点。
在ICDAR15上,删除短文本(检测到的字符少于两个)。该策略旨在进一步消除检测结果中的误检。
实验
数据集
ICDAR13:水平方向文本
ICDAR15:多方向文本
MSRA-TD500:句子级长文本
Total-Text datasets:曲形的文本
消融实验

模型对比试验

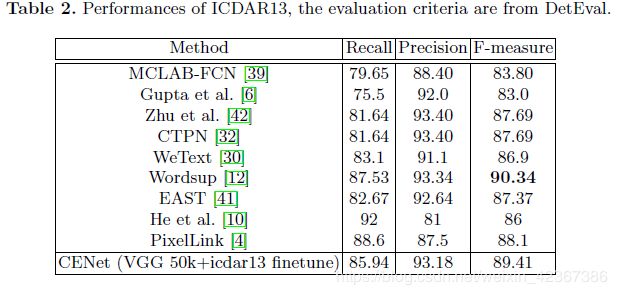
各个模型在ICDAR2013上的对比实验
各个模型在ICDAR2015上的对比实验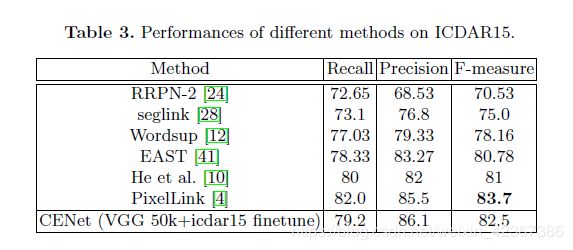
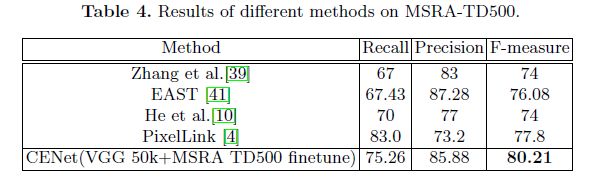
各个模型在MSRA-TD500上的对比实验
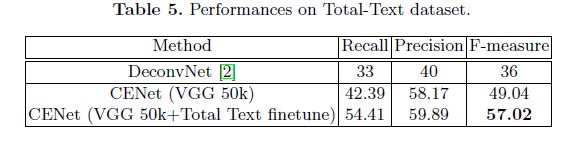
各个模型在Total-Text上的对比实验