姿态估计2-03:PVNet(6D姿态估计)-白话给你讲论文-翻译无死角(1)
以下链接是个人关于PVNet(6D姿态估计) 所有见解,如有错误欢迎大家指出,我会第一时间纠正。有兴趣的朋友可以加微信:a944284742相互讨论技术。若是帮助到了你什么,一定要记得点赞!因为这是对我最大的鼓励。
姿态估计2-00:PVNet(6D姿态估计)-目录-史上最新无死角讲解
本论文名为:
PVNet: Pixel-wise Voting Network for 6DoF Pose Estimation(CVPR 2019 oral)
话不多说,本人直接开始翻译了
Abstract
该论文主要提出一种,从单张RGB图像估算目标物体(遮挡或者截断情况下)的6D姿态。目前很多的方式都是使用两阶段的算法,首先是检测物体的关键点,然后利用Perspective-n-Point (PnP-目标姿态估算) 估算其6D姿态。然而,这些方法大多只通过回归它们的图像坐标或热图来定位一组稀疏的关键点。所以对于目标物体遮挡或者截断情况下的鲁棒性是非常差的,然而我们提出了Pixel-wise Voting Network (PVNet) 算法回归指向关键点的矢量(像素级别),并且利用这些方向矢量基于RANSAC(随机森林)对关键点进行投票选举,这为锁定或截断的关键点创建了一个灵活的表示法。这种表示法的另一个重要特征是它提供了关键点位置的不确定性,这可以被PnP求解器进一步利用。实验证明,我们的算法在LINEMOD,Occlusion LINEMOD 以及 YCBVideo datasets 等数据集上达到了目前最好的效果。
1. Introduction
物体姿态估算是为了检测物体,并且估算他们的旋转以及偏移矩阵。很多应用都建立在准确的姿态估算上面,如虚拟现实增强,自动驾驶,机器人抓取等。本文重点研究了恢复物体六自由度位姿的具体过程,如从单张RGB图像估算目标物体3D的rotation,translation。这个问题从很多方面来看都很具有挑战性,如严重遮挡,照明和外观变化,混乱背景情况的目标检测。
传统的方法通过建立目标图像和目标模型之间的对应关系可以实现位姿估计,他们依赖于手工提取特征,其对图片发生变化,或者背景凌乱的鲁棒性是很差的。使用深度学习的方法,通过端到端的训练进行特征提取,输入一张图像,获得目标物体对应的姿态。然而,泛化仍然是一个问题,因为不清楚这种端到端方法是否学习了足够的特征表示来进行姿态估计。
有的一些算法,首先利用CNN去回归2D keypoints,然后通过 Perspective-n-Point (PnP)计算 6D姿态参数,换句话说,检测关键点为姿态估算的一个中间步骤,这种两截断的方法达到了目前最先进的效果,多亏了关键点的鲁棒检测。然而,这些方法在处理遮挡和截断目标时存在困难,尽管cnn可以通过记忆相似的模式来预测这些看不见的关键点,但是算法的泛化是很困难的。
们认为解决遮挡和截断需要密集的预测,也就是对最终输出或中间表示的 pixel-wise 或 patch-wise 估计。为此,我们提出了一个新的框架使用像素级投票网络的6D位姿估计(PVNet),其基本实现如Figure 1所示:
Figure 1
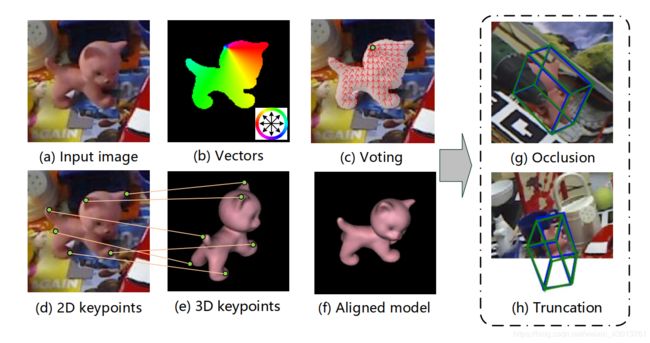
图解:将6D位姿估计问题表述为Perspective-n-Point (PnP)的问题,需要2D和3D关键点的对应,如上的插图(d) and (e),我们对每个像素都预测其指向关键点的 vectors(如图b所示),并在基于RANSACbased的投票方案中定位2D关键点(如图c所示)。提出的这种方法对于occlusion(如图g-遮挡),truncation (如图h-截断)的鲁棒性是很好的,绿色的边界盒代表地面真相的姿势蓝色的边界盒代表我们的预测。
我们并不是直接回归图像的关键点,PVNet预测的Vectors每个像素趋向目标各个关键点的方向,最后基于Vectors对关键点的位置进行投票,这个投票方案是由刚性物体的一种特性激发的,一旦我们看到一些局部部分,我们就能够推断出相对于其他部分的方向,
我们的方法本质上是为关键点定位创建一个矢量场表示,与基于坐标或热图的表示相反,学习这样种表示方式会使网络专注于物体的局部特征和物体各部分之间的空间关系,因此,因此物体的不可视部分,可以从物体的可是部分推算出来。另外, vector-field 是有能力去便是输入图像之外的关键点的。所有这些优点使它能较好的表示遮挡或者截断的对象,Xiang 等人,提出了一个类似的方法来检测目标,在这里我们使用它来定位关键点。
该方法的另一个优点是稠密的输出,为PnP求解器提供了丰富的信息来处理不准确的关键点预测。具体来说,基于RANSAC的投票抹去了局外人的预测,并给出了每个关键点的空间概率分布,这种关键点位置的不确定性,为PnP求解提供了更多的自由空间,去自主最终位姿,实验表明,不确定性驱动PnP算法提高了位姿估计的精度。
我们在 LINEMOD,Occlusion LINEMOD,YCB-Video等数据集上评估了我们的算法,这些都是6D姿态估计中广泛使用的基准数据集,通过这些数据集,PVNet展现了最先进的性能,我们还演示了我们的方法在名为Truncation LINEMOD的新数据集中处理截断对象的能力, 该数据是由随机裁剪LINEMOD的图像生成。另外我们的算法,效率也是比较高的。在GTX 1080ti GPU能达到 25 fps ,其可以实时的进行姿态估算。该篇论文的提出,主要做了如下贡献:
1.我们提出了新异的目标检测框架PVNet,其是基于像素级别的投票网络。主要是学习能够代表关键点的 vector-field ,其对遮挡或者截断对象的鲁棒性是很好的。
2.基于PVNet的密集预测,我们提出利用不确定性驱动的PnP算法来解释二维关键点定位中的不确定性。
3.在多个数据集上已经证明我们的算法是是否优越的,同时创建了一个新的数据集。
2. Related work
Holistic methods. 在给定一幅图像的情况下,一些方法的目的是在单镜头下估计物体的三维位置和方向,传统的方法主要依靠模板匹配技术,哪些对杂乱的环境和外观变化很敏感。最近,CNN对于环境外貌的改变展现出了很大的鲁棒性,作为一个先锋,PoseNet 介绍了使用CNN从单张图像RGB图像直接回归目标的 6D camera pose,但是,由于缺乏深度信息,直接在3D中定位对象是困难的,因为这是一个很大的空间。为了解决这个问题,PoseCNN对二维图像中的物体进行定位,并预测其深度,从而获得三维位置。然而,直接估计三维旋转也是困难的,由于旋转空间的非线性,使得CNNs的推广性较差。为了避免这种麻烦,将旋转空间离散化,将三维旋转估计转化为分类任务,这样的离散化会产生一个粗糙的结果,而后细化对于获得准确的6自由度姿态是至关重要的。
Keypoint-based methods. 基于关键的方法,其不是直接中一张图像获得姿态,其实使用了二截断的方式,其首先是获得2D关键点位置,然后通过PnP算法求解2D到3D之间坐标的对应关系。2D关键点的检测比3D定位以及旋转矩阵的估算是更加简单的。对于纹理丰富的对象,传统的方法对局部关键点的检测鲁棒性是很好的,从而有效、准确地估计出目标的姿态,即使在杂乱的场景和严重的遮挡下。然而传统的方法很难处理低纹理的目标以及低分辨率的图像。为了解决这个问题,最近的研究定义了一组语义关键点,并使用cnn作为关键点检测器,利用分割确定目标在图像的区域,并且对该区域进行关键点回归。使用YOLO架构来估计对象关键点,该网络的预测是基于低分辨率的特征图。当发生干扰时,如遮挡情况下姿态估算的准确率是很低的。受到2D人体姿态估以及其他算法的启发,输出关键点的像素级热图来解决遮挡问题。然而关键点热图是固定大小的,所以其是很难处理截断(关键点在图片的外面)情况,相比之下,我们的方法使用更灵活的表示法对二维关键点进行像素预测,比如 vector field,关键点的定位是通过他们进行投票决定的。
Dense methods. 在这种方法中,对每个 pixel 或者 patch 进行预测,然后使用 Hough voting
scheme 进行投票处理。使用随机森林预测三维对象坐标为每个像素,并产生二维到三维对应假设使用几何约束。总的来说使用CNN提取特征,用于最后的投票。然而这种方法需要RGB-D图像,使用自动上下文回归框架生成3D对象坐标的像素分布,相对于稀疏的关键点,为姿态估计提供了密集的2D-3D对应信息,对于遮挡物体的鲁棒性更加强。但是回归物体的3D坐标是比回归关键困难很多的。
我们的方法对关键点定位进行了密集预测。它结合了两种方法的优点,是一种基于关键点的密集方法
3. Proposed approach
在这篇论文中,我们提出一种新异的6D姿态估算框架,输入一张RGB图像,检测目标并且同时估算其6D姿态。其中,6D位姿(R;t)从物体坐标系到摄像机坐标系变换而来。R表示三维旋转,t表示三维平移。
受到最近一些方法的启发,我们使用两阶段的方法进行姿态评估:我们首先利用CNN检测2D关键点,然后使用PnP算法计算其姿态。我们的创新之处在于提出了一种新的二维目标关键点表示和改进的PnP位姿估计算法。我们的方法使用像素级的投票网络(PVNet)以类似搜查的方式检测2D关键点,其对于目标遮挡或者截断的鲁棒性是很强的。基于RANSAC的投票机制,给出 每个关键点的概率分布。使得我们可以用不确定驱动的PnP来估计6D的姿态
3.1. Voting-based keypoint localization
Figure 2概括呢关键定位的处理过程,输入一张RGB图像,PVNet预测每个像素的类别标签以及unit vectors。unit vectors代表了其趋向于关键点的方向。给定从属于该对象的所有像素到某个对象关键点的方向,我们为该关键点生成2D位置进行假设,然后根据置信分数使用RANSAC-based投票。我们评估每个关键点空间概率分布的均值与协方差。
与直接从图像部分进行关键点回归的明显差异。对每个像素进行方向预测,强制网络更加关注局部信息,去减少遮挡或者混乱背景的干扰。另外一个优势就是,该方式有能力代表遮挡或者处于图像之外的关键点。甚至一些不可见的关键点,通过可见的部分也能预测出来。
更加具体的说明,PVNet 执行两个任务,分别是语义分割以及 vector-field 的预测。针对于每个 pixel P P P,PVNet输出目标对应目标的语义标签,以及 unit vector V k ( P ) V_k(P) Vk(P), V k ( P ) V_k(P) Vk(P) 代表了每个像素趋向于2D关键点 X K X_K XK 的方向, V k ( P ) V_k(P) Vk(P)的定义如下:
V k ( P ) = X k − P ∣ ∣ X k − P ∣ ∣ 2 V_k(P) = \frac {X_k-P}{||X_{k}-P||_2} Vk(P)=∣∣Xk−P∣∣2Xk−P
给去语义分割的标签 mask 以及unit vectors,我们基于RANSAC策略去生成假设的关键点。首先使用语义分割的标签获得目标物体的相关像素,随机选择一对像素的vector,把他们的交叉点看作为关键点 h k h_k hk,例如针对于关键点 X k X_k Xk,随机选取成对vector操作重复N次,这样我们就获得一个关键点假设集合 { h k , i ∣ i = 1 , 2 , 3...... , N } \{h_{k,i}|i=1,2,3......,N\} {hk,i∣i=1,2,3......,N},其表示的是关键点可能所在位置,最后,对象的所有像素都对这些假设进行投票,具体而言,假设 h k , i h_{k,i} hk,i的投票分数 w k , i w_{k,i} wk,i定义为
w k , i = ∑ p ∈ O Π ( ( h k , i − P ) T ∣ ∣ h k , i − P ∣ ∣ 2 V k ( P ) ≥ θ ) w_{k,i}=\sum_{p \in O} \Pi (\frac {(h_{k,i}-P)^T}{||h_{k,i}-P||_2}V_k(P) \geq θ) wk,i=p∈O∑Π(∣∣hk,i−P∣∣2(hk,i−P)TVk(P)≥θ)
其中的 Π \Pi Π 表示指示函数, θ θ θ 表示阈值(实验中全部使用0.99), p ∈ O p \in O p∈O意味着像素 P P P 属于目标物体 O O O,直观的来说,更高的投票分数意味着一个假设更有信心,因为它与更多预测的方向一致。
由此产生的假设代表了图像中一个关键点的空间概率分布,如下图Figure 2中的 e 图:
Figure 2
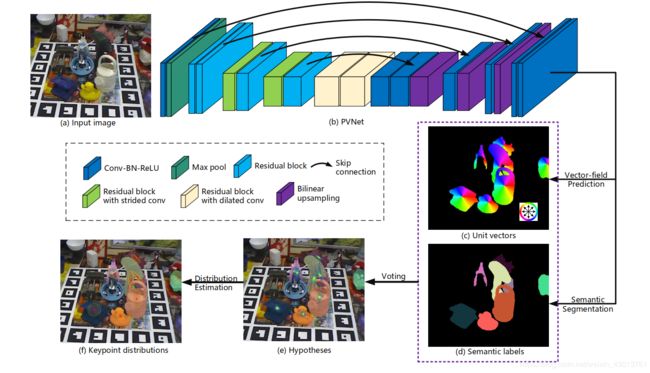
e图是一个代表的例子,对于关键点 X k X_k Xk均值 u k u_k uk 与协方差 ∑ k \sum_k ∑k 的估算如下:
u k = ∑ i = 1 N w k , i h k ∑ i = 1 N w k , i u_k = \frac {\sum_{i=1}^N w_{k,i}h_k}{\sum_{i=1}^Nw_{k,i}} uk=∑i=1Nwk,i∑i=1Nwk,ihk
∑ k = ∑ i = 1 N w k , i ( h k , i − u k ) ( h k , i − u k ) T ∑ i = 1 N w k , i \sum_k = \frac{\sum_{i=1}^Nw_{k,i}(h_{k,i}-{u_k})(h_{k,i}-u_k)^T}{\sum^N_{i=1}w_{k,i}} k∑=∑i=1Nwk,i∑i=1Nwk,i(hk,i−uk)(hk,i−uk)T
在第3.2节中描述的不确定性驱动的PnP使用哪些。
Keypoint selection. 需要根据三维对象模型定义关键点,最近的很多算法,使用 3D bounding box 的8个顶点当作关键点,一个例子如下图Figure 3(a):

图中的 a,可与看到每个顶点的坐标都是远离目标物体的,距离目标像素越远,定位误差就越大,因为关键点假设是用从目标像素开始的向量生成的。图Figure 3中的 b和 c 显示物体表面上选择的边框顶点和关键点的假设,他们都由PVNet网络生成,在定位过程中,物体表面的关键点通常具有较小的变化。
因此,对于关键点的选择,我们是选取物体表面的关键代理,而不是长方体边框的顶点。同时,这些关键点要分散在目标上,使PnP算法更加稳定。考虑到两个需求,我们使用 farthest point sampling (FPS) 算法选取 K K K个关键点,我们通过添加对象中心来初始化关键点设置,然后我们重复的在物体表面选择关键点,哪个距离当前关键点集最远,然后把它加到集合中,直到集合的大小达到 K K K。实证结果见第5.3节,表明使用这种方法,更加由于使用长方体边框的顶点作为关键点。我们对不同数目的关键点进行测试,考虑到效率和准确率的问题,我们建议是最好是选取 K K K = 8。
Multiple instances.
基于该策略,我们的方法可以处理多个实例, 使用我们提出的投票方案生成对象中心及其投票分数的假设, 最后后,我们在假设中找出模型,并将这些模型标记为不同实例的中心。最后,通过将像素分配到他们投票选择的最近的实例中心来获得实例掩码(这段不太会翻译,不知道modes表示什么)
3.2. Uncertainty-driven PnP
获得目标对象的2D关键位置后,可以使用 PnP 算法求解6d姿态。如之前很多的算法采用EPnP,但是他们忽略每个关键点的置信度是由差异的,存在不确定性,在使用PnP进行求解的时候,我们应该考虑到这些问题。
如第3.1节所述,我们的投票机制,出来的结果是每个关键的对应的概率分布,对于每个关键点的评估标准,是计算他们的均值 u k u_k uk 以及协方差 ∑ k = 1 , 2 , 3 , . . . k \sum_k=1,2,3,...k ∑k=1,2,3,...k,通过最小化Mahalanobis distance 计算6D姿态估算pose (R,t)。
m i n i m i z e R , T ∑ k = 1 k ( ( X ‾ k − u k ) T ∑ k − 1 ( X ‾ k − u k ) ) minimize_{R,T} \sum_{k=1}^k((\overline X_k-u_k)^T\sum_k^{-1}(\overline X_k-u_k)) minimizeR,Tk=1∑k((Xk−uk)Tk∑−1(Xk−uk)) X ‾ k = π ( R X k + t ) \overline X_k = \pi(RX_k + t) Xk=π(RXk+t)
这里的 X k X_k Xk代表关键点的3D坐标, X ‾ k \overline X_k Xk是 3D X k X_k Xk 的 2D 映射,EPnP算法根据四个关键点对参数R和t进行初始化,其协方差矩阵轨迹最小。然后利用LevenbergMarquardt算法求解,在其他的一些工作中还通过最小化逼近值来考虑特征的不确定性Sampson错误,在我们的方法中,我们直接最小化重投影误差。
4. Implementation details
假设存在C类物体,每个物体的关键点数目为K个,PVNet 输入要求为 H × W × 3 H \times W \times 3 H×W×3的图像,用一个完全卷积的架构处理它。输出 H × W × ( K × 2 × C ) H \times W \times (K \times 2 \times C) H×W×(K×2×C)的unit vectors, H × W × ( C + 1 ) H×W ×(C+1) H×W×(C+1)的类别概率,我们使用预训练好的ResNet-18 模型作为主干网络,我们对其作了三次修改:
1.当网络的feature map的大小为 H = 8 × W = 8 H=8×W=8 H=8×W=8时,我们不再通过丢弃后续的pooling层对feature map进行downsample
2.为了保持接收域不变,用合适的扩张的卷积替换后续的卷积
3.将原ResNet-18中全连接层替换为卷积层
然后在feature map上反复进行跳跃连接、卷积和上采样,直到其输出 H x W HxW HxW的特征图为止,展示如之前的贴图Figure 2,在最终的feature map上进行1×1的卷积,我们得到了单位向量和类概率。
我们使用CUDA实现假设生成、像素级投票和密度估计,用于初始化姿态的EPnP在OpenCV中实现,为了得到最终的位姿,我们使用迭代求解器Ceres去最小化Mahalanobis distance。对于对称对象,关键点位置存在歧义,为了消除歧义,我们在训练中将对称对象旋转到一个标准姿势。
4.1. Training strategy
我们使用平滑 φ l o s s \varphi ~loss φ loss去学习unit vectors,其 l o s s loss loss函数被定义如下:
φ ( w ) = ∑ k = 1 k ∑ p ∈ O φ ( Δ v k ( p ; w ) ∣ x ) + φ ( Δ v k ( p : w ) ∣ y ) \varphi (w)=\sum_{k=1}^{k}\sum_{p \in O} \varphi(\Delta v_k(p;w)|_x)+\varphi(\Delta v_k(p:w)|_y) φ(w)=k=1∑kp∈O∑φ(Δvk(p;w)∣x)+φ(Δvk(p:w)∣y) Δ v k ( p ; w ) = v ‾ k ( p ; w ) − v k ( p ) \Delta v_k(p;w)= \overline v_k(p;w)-v_k(p) Δvk(p;w)=vk(p;w)−vk(p)
其上的 w w w代表 PVNet 的网络参数, v ‾ \overline v v表示预测的unit vector, v k v_k vk 表示 ground truth unit vector, Δ v k ∣ x \Delta v_k|_x Δvk∣x 与 Δ v k ∣ y \Delta v_k|_y Δvk∣y 表示 Δ v \Delta v Δv 的两个元素。对于训练语义分割的标签,使用的是softmax cross-entropy,值得注意的是,我们不需要预测的向量单位的具体值,因为后续的处理只使用向量的方向。
为了防止过拟合,添加了合成的数据到训练集之中,对于每个对象,我们渲染10000张视点一致采样的图像,们进一步使用“剪切粘贴”策略合成了另外10000张图像,每张图片的背景都是从SUN397数据集中随机选取的,我们还应用了在线数据增加,包括随机裁剪,在训练中调整大小,旋转和颜色抖动等。我们将初始学习率设置为0.001,并每20个epoch将其减半。所有的模型都训练了200个epoch
结语
到这里,该篇论文的重点可以说是翻译完成了,下篇博客继续为大家翻译剩余的部分