【机器学习】基于机器学习的乳腺癌预测模型
基于机器学习的乳腺癌预测模型(附Python代码)
- 前提说明
- 项目介绍
- 导入数据
- 概述数据
- 数据可视化
- 评估算法
- 实施预测
- 代码
- 参考
前提说明
此博客内容为2018年山东省人工智能大赛曲阜师范大学青春梦想队所创作,未经授权,禁止使用。
项目介绍
这个项目是针对乳腺癌进行分类的一个项目,使用的乳腺癌数据集,具有如下特点:
①所以特征数字都是数字,不需要考虑如何导入以及如何处理数据
②特征列第一列为用户ID信息,不参与此次机器学习模型构建
③这是一个分类问题,可通过有监督学习算法来解决问题,这是一个二分类问题,无需进行特殊处理
④所有特征的数值采用相同的单位,即特征按照程度划分为1~10,无需进行尺度的转换
⑤在某些特征列数据缺失,需要进行数据缺失处理
接下来,我们会对这一些特点进行分析,以下为相关步骤:
①导入数据
②概述数据并进行数据缺失处理
③数据可视化
④评估算法
⑤实施预测
导入数据
首先,需要导入项目所需的类库和数据集,类库包括numpy、pandas、sklearn、matplotlib库,数据集为之前介绍的乳腺癌数据集,在这里将采用Pandas来导入数据。在接下来的部分将采用Pandas来对数据进行描述性统计分析和数据可视化。需要注意的是,在导入数据时,给每个数据特征设定了名称,进一步解决了在医疗上名称过长的问题,这有助于后面对数据的展示工作。
概述数据
接下来对数据我们做一些理解,以便于选择合适的算法,我们会通过以下几个角度审查数据,并附上概述结果:
I.数据的维度
II.查看数据自身及其描述
III.统计描述所有的数据特征
IV.数据分类分布
以下为概述结果:
数据的维度概述结果:

查看数据自身及其描述概述结果:
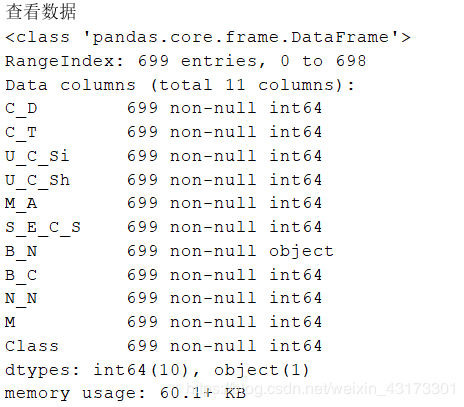
统计描述所有的数据特征概述结果:
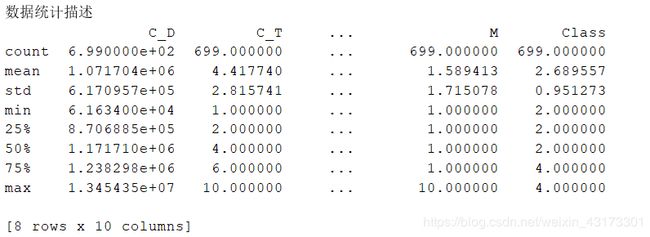
数据分布情况概述结果:

数据可视化
我们对我们所处理的数据有了基本的了解,将通过图表来查看数据的分布情况和数据不同特征直接的相互关系,其中单变量图表更好地理解每一个特征属性,多变量图表来理解不同特征属性的关系。
3.1箱线图
首先从单变量图表开始显示每一个单独的特征属性,因为每个特征属性都是数字,因此我们可以通过箱线图来展示的属性和与中位值的离散速度,其执行结果如下:
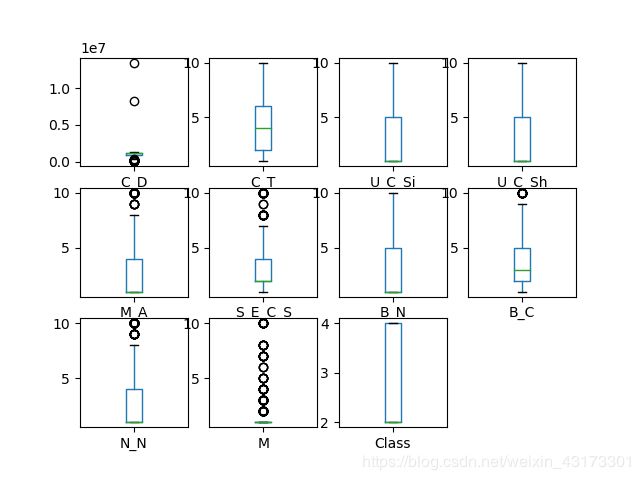
3.2直方图
接下来通过直方图来显示每个特征属性的分布状况,在输出的图表中,我们看到特征符合高斯分布,执行结果如下:
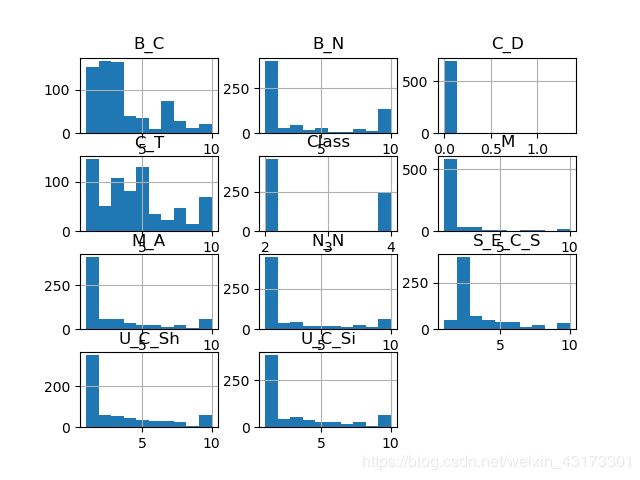
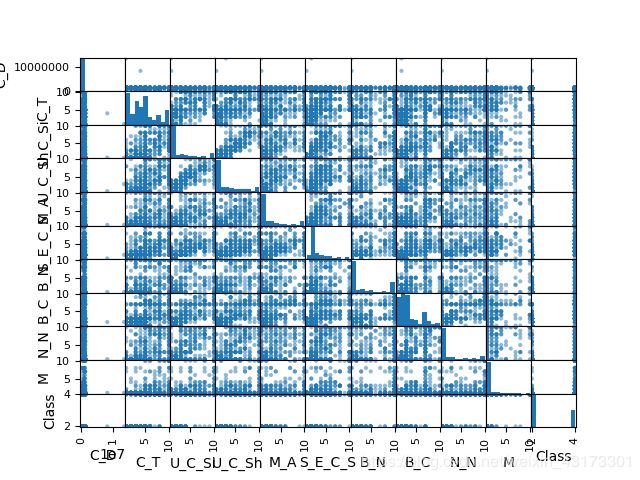
3.3散点矩阵图
接下来通过多变量图表来看一下不同特征属性之间的关系。在这里我们通过散点矩阵图来查看属性的俩俩之间的影响关系。
评估算法
我们会通过六种不同的算法来创建模型,并评估他们的准确度,以便于我们找到合适的算法。我们会通过以下步骤进行:
I. 分离出评估数据集。
II. 采用10交叉折验证来评估算法模型。
III. 生成5各不同的模型来预测新数据。
IV. 选择最优模型。
4.1分离出评估数据集
创建的模型是否足够好。后面我们会采用统计学的方法来评估我们创建的模型。但是,我们更想实际看一下我们的模型对真实的数据的准确度是什么情况,这是我们要保留一部分数据用来评估算法模型的主要原因。我们将会按照80%的训练数据集,20%的评估数据集来分离数据。于是就分离出了X_train,y_train用来训练算法创建模型,X_validation,y_validation在后面用来验证评估模型。
4.2评估模型
在这里将通过10折交叉验证来分离训练数据集,并评估算法模型的准确度。10折交叉验证是随机的将数据分成10份,8份用来训练模型,2份用来评估算法。在接下来的部分,将会对每一个算法,使用相同的数据进行训练和评估,并从中选择最好的模型。
4.3创建模型
我们不知道哪个算法对这个问题比较有效。通过前边的图表,我们发现有些数据特征线性分布,所有可以期待算法会得到比较好的结果。接下来评估6种不同的算法:
· 线性回归(LR)
· 线性判别分析(LDA)
· k近邻(KNN)
· 分类与回归树(CART)
· 贝叶斯分类器(NB)
· 支持向量机(SVM)
这个算法列表中包含了线性算法(LR、LDA),非线性算法(KNN、CART、NB、SVM)。在每次对算法进行评估前都会重现设置随机数的种子,以确保每次对算法的评估采用相同的数据集,保证对算法评估的公平性。接下来就创建并评估这六种算法模型。
4.4选择最优模型
现在我们有6各模型,并且评估了它们的精确度。我们需要比较这六个模型,并从中选出准确度最高的算法。执行代码结果如下:

选择最优模型执行结果
通过以上结果,我们会发现,针对乳腺癌预测模型,我们选择KNN(非线性算法)的准确度相对于其他算法更高,为了进一步比较算法之间的优劣关系,我们制作了算法比较的箱线图,其结果如下:

由此我们可以最终得出结论,选择KNN算法其准确度最高,模型最优。
实施预测
评估的结果显示,支持KNN算法是准确度最高的的算法。现在我们需要使用我们预留的评估数据集来验证这个算法模型。接下来我们可以使用我们得出的KNN的算法模型,并用评估数据集给出一个算法模型的报告。
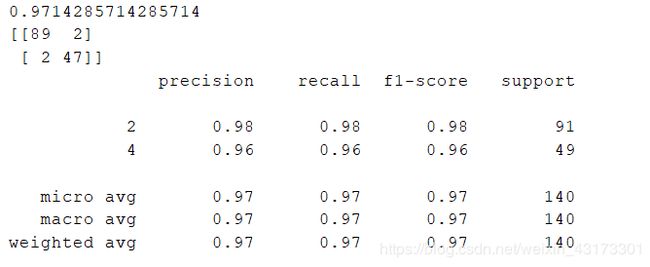
执行代码,我们会看到其准确度为0.97。通过观察冲突矩阵,我们发现对于乳腺癌良性及恶性症状类型,每个分类仅有两例预测错误,其下为其准确度、召回率、F1值的数据。
代码
# 导入类库
from pandas import read_csv
import pandas as pd
from sklearn import datasets
from pandas.plotting import scatter_matrix
from matplotlib import pyplot
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
from sklearn.preprocessing import LabelEncoder
from sklearn.linear_model import LogisticRegression
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns #要注意的是一旦导入了seaborn,matplotlib的默认作图风格就会被覆盖成seaborn的格式
import numpy as np
#breast_cancer_data = pd.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data',header=None
# ,names = ['C_D','C_T','U_C_Si','U_C_Sh','M_A','S_E_C_S'
# ,'B_N','B_C','N_N','M','Class'])
breast_cancer_data = pd.read_csv('breast_data.csv',header=None
,names = ['C_D','C_T','U_C_Si','U_C_Sh','M_A','S_E_C_S'
,'B_N','B_C','N_N','M','Class'])
#打印数据
print(breast_cancer_data)
#查看维度
print('查看维度:')
print(breast_cancer_data.shape)
#查看数据
print('查看数据')
breast_cancer_data.info()
breast_cancer_data.head(25)
#数据统计描述
print('数据统计描述')
print(breast_cancer_data.describe())
#数据分布情况
print('数据分布情况')
print(breast_cancer_data.groupby('Class').size())
#缺失数据处理
mean_value = breast_cancer_data[breast_cancer_data["B_N"]!="?"]["B_N"].astype(np.int).mean()
breast_cancer_data = breast_cancer_data.replace('?',mean_value)
breast_cancer_data["B_N"] = breast_cancer_data["B_N"].astype(np.int64)
#数据的可视化处理
#单变量图表
#箱线图
breast_cancer_data.plot(kind='box',subplots=True,layout=(3,4),sharex=False,sharey=False)
pyplot.show()
#直方图
breast_cancer_data.hist()
pyplot.show()
#多变量的图表
#散点矩阵图
scatter_matrix(breast_cancer_data)
pyplot.show()
#评估算法
#分离数据集
array = breast_cancer_data.values
X = array[:,1:9]
y = array[:,10]
validation_size = 0.2
seed = 7
#train训练,validation验证确认
X_train,X_validation,y_train,y_validation = train_test_split(X,y,test_size=validation_size,random_state=seed)
#评估算法(算法审查)
models = {}
models['LR'] = LogisticRegression()
models['LDA'] = LinearDiscriminantAnalysis()
models['KNN'] = KNeighborsClassifier()
models['CART'] = DecisionTreeClassifier()
models['NB'] = GaussianNB()
models['SVM'] = SVC()
num_folds = 10
seed = 7
kfold = KFold(n_splits=num_folds,random_state=seed)
#评估算法(评估算法)
results = []
for name in models:
result = cross_val_score(models[name],X_train,y_train,cv=kfold,scoring='accuracy')
results.append(result)
msg = '%s:%.3f(%.3f)'%(name,result.mean(),result.std())
print(msg)
#评估算法(图标显示)
fig = pyplot.figure()
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
pyplot.boxplot(results)
ax.set_xticklabels(models.keys())
pyplot.show()
#实施预测
#使用评估数据集评估算法
knn = KNeighborsClassifier()
knn.fit(X=X_train,y=y_train)
predictions = knn.predict(X_validation)
print('最终使用KNN算法')
print(accuracy_score(y_validation,predictions))
print(confusion_matrix(y_validation,predictions))
print(classification_report(y_validation,predictions))
参考
https://read.douban.com/reader/column/6939417/chapter/35867190/#
https://blog.csdn.net/ruoyunliufeng/article/details/79369142
如有侵权,请及时联系。