只需一步,DLA开启TableStore多元索引查询加速!
一、背景介绍
Data Lake Analytics(简称DLA)在构建第一天就是支持直接关联分析Table Store(简称OTS)里的数据,实现存储计算分离架构,满足用户基于SQL接口分析Table Store数据需求。
玩转DLA+OTS:https://ots.console.aliyun.com/index#/demo/cn-hangzhou/dla
王烨:DLA如何分析Table Store的数据
DLA控制台:https://openanalytics.console.aliyun.com/
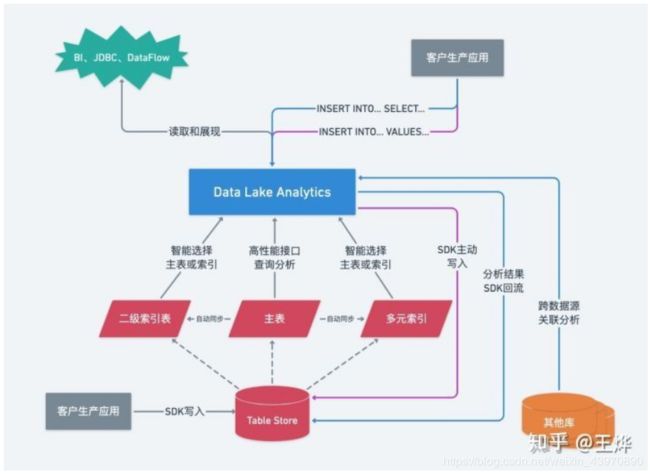
二、DLA与Table Store的密切配合
这是DLA与Table Store在生态中的关系,作为存储计算分离架构,DLA负责主要的SQL算子计算,而Table Store则负责部分计算(由DLA下推下来)和核心存储功能。
三、Table Store的数据原型
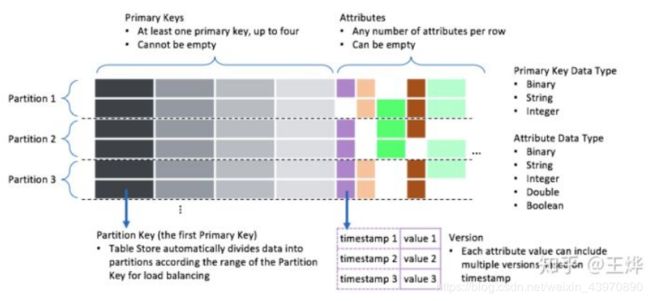
目前,Table Store的宽数据表结构中的列, 主要分成两部分:主键(所有主键都不可改,也不为空;其中第一主键是物理分区键),非主键列(可改可覆盖可为空,可有可无):
假设有张表tbl(主键:pk1,pk2;非主键:col1,col2),当DLA收到这样的SQL时:
select pk2,col1 from tbl where pk1 = 123 and pk2 >= '2019-01-10' and col2 = 'zzz'
DLA就会基于Table Store的SDK接口下发相关的查询:
1)查询tbl表数据,其中只查询pk2、pk3、col3这几个列;
2)按照pk1做分区裁剪,只下推查询到pk1=123所在的分区;
3)下推 pk1 =123、pk2 >='2019-01-10'和col4 ='zzz' 这三个条件;
4)如果当前分区的数据很大,则会切分出多个分片,并行查询;
这里,最关键的条件就是 pk1 =123,DLA基于这个第一主键(分区键)条件来筛选OTS的目标分区然后下发查询条件。其他支持的分区条件有
比较条件:>,>=,=,<,<=,!=
范围条件:[1,20], (2,10), (-∞,10], (20,+∞)等
四、DLA+Table Store查询时的瓶颈
针对上面的表结构,如果遇到如下的SQL:
select pk2,pk3,col3 from tbl where pk2 >= '2019-01-10' and col4 = 'zzz'
因为pk1并没有出现在条件中,无法做分区裁剪,因此目前DLA会先将整个TableStore的表切好分片,然后下推其他条件,并行获取每个分片的数据并做计算。这样的问题就是:
- 如果where条件的过滤性很强(满足条件的数据不多),那这种拉取大量数据方式就会引起极大的浪费;即使where条件是可以下推的,但Table Store内部也要消耗大量的CU来做计算和过滤;
- 虽然通过并行计算来加速,但整体延时还是会很高,无论这些计算是在Table Store内部还是DLA这一侧;尤其是强过滤性的SQL,更加不符合用户需求;
无论是计算成本还是延时,都会影响客户的体验。
而多元索引是基于倒排索引来设计和实现的:
- 把一行Table Store记录看成一篇Document,而Pk是这个Document的DocId;
- 每个索引字段都当成一个Term,每个Term值都反向形成一个DocId的链表;
- 在查询时针对where条件中每个列找到满足值域的Term列表,再对应产生多个DocId列表;
- 再通过拉链合并算法,最终得到合并DocId之后的最大公共集合;
- 基于这个合并之后的DocId集合(即Pk集合),再回主表查询数据和过滤、返回;
因此,DLA全面升级了,支持直接以SQL方式访问Table Store的多元索引从而来加速查询。
五*、DLA访问Table Store的多元索引
对DLA的客户来说,只需一步,就可以使用DLA来访问Table Store的多元索引。因为目前统计信息采集及优化器等原因,暂时还不支持自动判断多元索引,所以需要利用DLA的hint来主动开启:
/*+ ots-index-first=<相关的索引开关> */ select * from tbl1 where ...
其中,索引开关有几种模式:
- auto模式,会寻找与表相关的索引,只要有满足条件的索引,就会强制使用:
/*+ ots-index-first=auto */ select * from tbl1 where ...
- custom模式,根据用户选择表列表,来自动选择满足条件的索引;其中tbl1不需要显示指定库名,是因为当前连接上已经绑定了一个库(比如use xxx);如下case中,只有tbl1和tbl2会走索引,而tbl3则不会:
/*+ ots-index-first=[tbl1, dla_schema2.tbl2, ...] */ select * from tbl1
join dla_schema2.tbl2 join dla_schema3.tbl3 where ...
- threshold模式,会根据当前条件匹配的数据量来动态决策,如果找到一个索引,其匹配的数据量小于一定的行数或者一定比例,那就会自动选择;threshold:200表示where条件匹配的行数不超过200行才会使用,而threshold:5%则表示匹配的比例不超过5%才会使用(至于200和5%,DLA内部会调用Table Store的count接口做快速测试并预估判断):
/*+ ots-index-first=threshold:200 */ select * from tbl1 where ...
/*+ ots-index-first=threshold:5% */ select * from tbl1 where ...
另外,早期客户给DLA做的角色授权策略里并没有这些新增的多元索引接口,因此老客户需要重新给DLA做跨云服务访问的角色授权。
六、多元索引不是银弹,请合理使用
虽然Table Store多元索引很好用,但他也不是银弹,需要合理的使用。有几个场景的约束:
- 查询多元索引时,只能构建并下发一个分片,因此无法利用并行计算优势;因此对于匹配行数非常少时,单分片索引计算是有优势的;而过滤性很差、数据量很多时就没有优势;
- 目前多元索引与主表数据之间不是强一致同步的(正常同步时间在毫秒到秒级),因此业务上需要容忍这个延时;
- 通过索引找到一批Pk列表后,会再发起随机query来查找主表数据,所以可能会更慢;
- 索引字段的类型、定义等,可能不符合数据库的使用特性(比如定义了全文索引字段等),暂时也不能被自动使用起来;
当然,针对传统数据库的索引中的一些特性,在DLA中也尽量采纳进来,比如Covering Index来避免随机查询主表,DLA和Table Store也支持,比如这样的SQL:
-- pk1, pk2是主键,col1,col2是非主键列,索引是idx_col1_col2
select pk1, col1 from tbl where col2 = 21
这里col1和col2都在索引中,而pk1和pk2也间接在索引中,因此这个SQL完全可以在索引上完成过滤和输出,从而避免回主表查询。
七、未来方向考虑
除了多元索引之外,目前Table Store团队也在积极地推广二级索引,帮助用户更好的使用Table Store。未来DLA也会将这块能力集成进来,这样DLA可以帮助用户在主表、二级索引表、多元索引表之间最优化选择,帮助客户提升性能并且降低成本。
未来,DLA需要实现预先采集更多的统计信息,免去用户主动添加hint的麻烦,完全自动化的选择和路由,做到真正的数据库体验。
未来,DLA还需要下推更多的计算到Table Store上,实现更好的”近存储计算“,比如聚合能力下推、函数下推、支持全文索引等等,让用户使用DLA+Table Store获得更好的体验。
原文链接
本文为云栖社区原创内容,未经允许不得转载。