无监督学习——聚类(clustering)算法应用初探
俗话说:“物以类聚,人以群分”,在自然科学和社会科学中,存在着大量的分类问题。所谓类,通俗地说,就是指相似元素的集合。
在工业生产过程中,通过分析生产数据及相关数据,将为我们优化创新、降本增效提供科学依据。以分类需求为例,通常由人工辅助信息化系统,以及业务专家等,通过大量理论计算,把数据转化为图形、表格,依赖人的智慧把数据分类,打上标签,为科研、生产管理提供辅助决策支持。
我们在实际工作中,使用当前信息化资产——历史生产数据进行大数据人工智能研发工作,通过深度学习,虽然取得很好的结果,不过还有专家对此有疑虑,例如数据准确性问题,物联网采集的数据“异常”情况、人工分类失误为数据打上错误的标签等等,对于这些问题,我引入了聚类算法,用以区分正常数据、不正常数据。
聚类是将对象进行分组的一项任务,使相似的对象归为一类,不相似的对象归为不同类。聚类分析(Cluster Analysis)是机器学习算法中同数据分类算法同样重要的算法,数据聚类分析是一种无监督的机器学习方法。
1. DBSCAN聚类
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一个比较有代表性的基于密度的聚类算法。与划分和层次聚类方法不同,它将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在噪声的空间数据库中发现任意形状的聚类。
1.1. DBSCAN算法原理
DBSCAN算法:将簇定义为密度相连的点最大集合,能够把具有足够高密度的区域划分为簇,并且可在噪声的空间数据集中发现任意形状的簇。
DBSCAN中的几个定义:
- Ε邻域:给定对象半径为Ε内的区域称为该对象的Ε邻域;
- 直接密度可达:对于样本集合D,如果样本点q在p的Ε邻域内,并且p为核心对象,那么对象q从对象p直接密度可达。
- 密度可达:对于样本集合D,给定一串样本点p1,p2….pn,p= p1,q= pn,假如对象pi从pi-1直接密度可达,那么对象q从对象p密度可达。
- 密度相连:存在样本集合D中的一点o,如果对象o到对象p和对象q都是密度可达的,那么p和q密度相联;
- 核心对象:如果给定对象的半径eps邻域内样本数量超过阈值min_samples,则称为核心对象;
- 边界对象:在半径eps内点的数量小于min_samples,但是落在核心点的邻域内;
- 噪声对象:既不是核心对象也不是边界对象的样本。
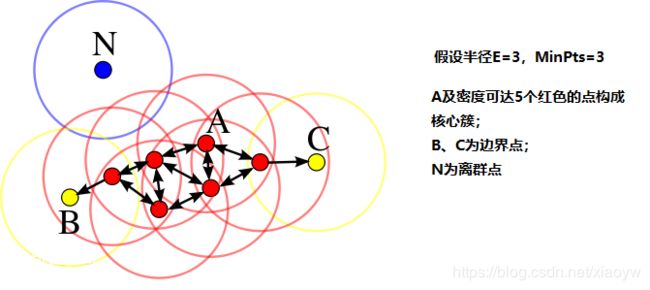
如上图所示,在众多样本点中随机选中一个(A),围绕这个被选中的样本点画一个圆,规定这个圆的半径以及圆内最少包含的样本点,如果在指定半径内有足够多的样本点在内,那么这个圆圈的圆心就转移到这个内部样本点,继续去圈附近其它的样本点,类似传销一样,继续去发展下线。等到这个滚来滚去的圈发现所圈住的样本点数量少于预先指定的值,就停止了。那么我们称最开始那个点为核心点,如A,停下来的那个点为边界点,如B、C,没得滚的那个点为离群点,如N。
Eg: 假设半径Ε=3,MinPts=3,点p的E邻域中有点{m,p,p1,p2,o}, 点m的E邻域中有点{m,q,p,m1,m2},点q的E邻域中有点{q,m},点o的E邻域中有点{o,p,s},点s的E邻域中有点{o,s,s1}.
1.2. 参数
- 半径(eps):半径是最难指定的 ,大了,圈住的就多了,簇的个数就少了;反之,簇的个数就多了,这对我们最后的结果是有影响的。我们这个时候K距离可以帮助我们来设定半径r,也就是要找到突变点;
- MinPts(min_samples):半径中要有的样本数,就是圈住的点的个数,也相当于是一个密度,一般这个值都是偏小一些,然后进行多次尝试;
- metric:采用怎样的距离计算方式,默认是欧式距离,其他的距离,曼哈顿,切比雪夫等;
- metric_params:Additional keyword arguments for the metric function,计算距离的方式可能还有其他的参数需求,欧氏距离没有那就是none;
- algorithm:{‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}在DBSCAN中我们要找一个点他的近邻,这有三种算法,而auto会自动挑一个最好的给你,稀疏数据的话,一般就brute了。
其实最最重要的参数是前面两个,eps和min_samples,而我们主要的调参也就是这些,其他的,保持默认就好。
1.3. SKlearn API及其应用代码实践
1.3.1. API:
- model = sklearn.cluster.DBSCAN(eps_领域大小圆半径,min_samples_领域内,点的个数的阈值)
- model.fit(data) 训练模型
- model.fit_predict(data) 模型的预测方法
1.3.2. 代码:
聚类应用案例是解决数据分析过程中,异常数据的问题,包括人工标签错误。
'''
Created on 2019年4月12日
@author: xiaoyw
'''
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.colors as colors
from sklearn.cluster import DBSCAN
import math
def init_data():
data_X = []
data_Y = []
data_X ,data_Y = featureSet()
c = len(data_X)
row = 0
xp = []
while row < c:
tmp_data = data_X[row]
P = []
P.append(tmp_data[17])
P.append(tmp_data[18])
tmp_x = np.array(P)
tmp_x = tmp_x.transpose(1,0) # 二维转置
if len(xp) == 0:
xp = tmp_x
else:
xp = np.concatenate((xp,tmp_x)) # concatenate,第三个参数,1是水平连接,默认是0
row = row + 1
return np.array(xp)
if __name__ == '__main__':
colors_ = ['b','r','y','g','m','c','k','pink']
X = init_data()
db = DBSCAN(eps = 0.8, min_samples = 10).fit(X) #.fit_predict(X)
y_pred = db.labels_
index = [int(tmp) for tmp in y_pred]
col = []
k = 0
for i in index:
k = i
if k>=len(colors_):
k = i%len(colors_)
# 设置不同的颜色
col.append(colors_[k])
plt.scatter(X[:, 0], X[:, 1], c=col) #y_pred)
plt.show()
1.3.3. 运行效果
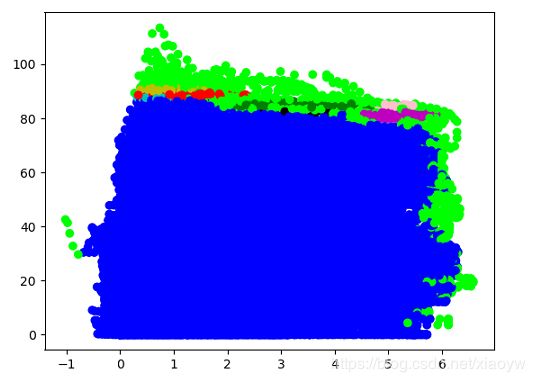
效果一:eps = 0.5、min_samples = 20
效果二:eps = 0.8、min_samples = 10
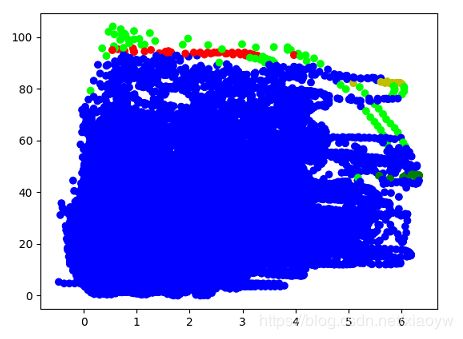
通过上述效果来分析,异常数据属于小概率样本,这样需要扩大核心密度E领域的半径,缩小密度,也就是min_samples 的参数值。
算法优缺点
| 优点 | 缺点 |
|---|---|
| 可以发现任意形状的聚类 | 随着数据量的增加,对I/O、内存的要求也随之增加。如果密度分布不均匀,聚类效果较差。 |
2. Birch聚类
BIRCH的全称是利用层次方法的平衡迭代规约和聚类(Balanced Iterative Reducing and Clustering Using Hierarchies)。
2.1. Birch算法原理
BIRCH算法利用了一个树结构来帮助我们快速的聚类,这个数结构类似于平衡B+树,一般将它称之为聚类特征树(Clustering Feature Tree,简称CF Tree)。这颗树的每一个节点是由若干个聚类特征(Clustering Feature,简称CF)组成。从下图我们可以看看聚类特征树是什么样子的:每个节点包括叶子节点都有若干个CF,而内部节点的CF有指向孩子节点的指针,所有的叶子节点用一个双向链表链接起来。
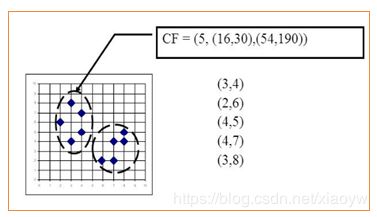
如上图所示:N = 5
LS=(3+2+4+4+3,4+6+5+7+8)=(16,30)
SS =(32+22+42+42+32,42+62+52+72+82)=(54,190)
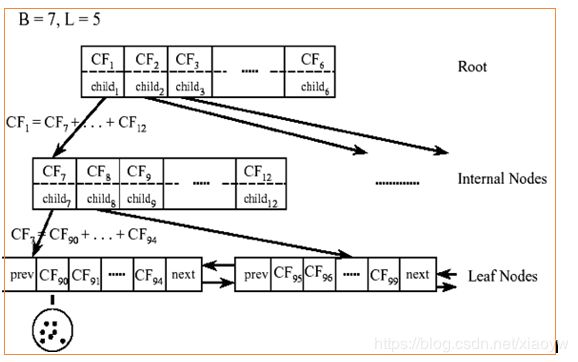
对于上图中的CF Tree,限定了B=7,L=5, 也就是说内部节点最多有7个CF(CF90下的圆),而叶子节点最多有5个CF(CF90到CF94)。叶子节点是通过双向链表连通的。
2.2. SKlearn Birch算法函数
2.2.1. 主要参数(详细参数)
- n_clusters :聚类的目标个数。(可选)
- threshold :扫描半径(个人理解,官方说法比较绕口),设置小了分类就多。
- branches_factor:每个节点中CF子集群的最大数量,默认为50。
2.2.2. 主要属性
labels_ :每个数据点的分类
2.3. 应用案例代码实现
2.3.1. 代码
colors_ = ['b','r','y','g','m','c','k','pink']
birch = Birch(n_clusters = 18)
##训练数据
y_pred = birch.fit_predict(X)
print("CH指标:", metrics.calinski_harabaz_score(X, y_pred))
##绘图
index = [int(tmp) for tmp in y_pred]
col = []
for i in index:
col.append(colors_[i])
plt.scatter(X[:, 0], X[:, 1], c=col)#y_pred)
plt.show()
与上节重复代码省略。
2.3.2. 效果
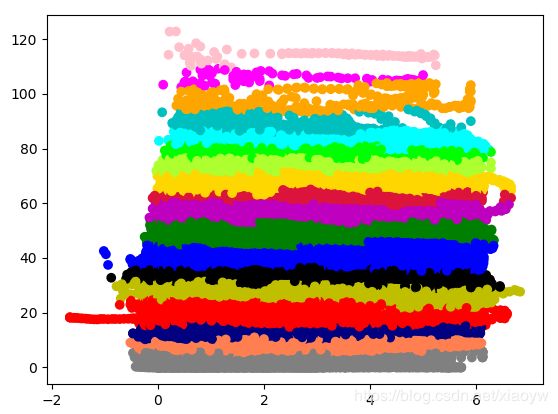
分层效果还是挺好的,但是识别异常数据未达到期望。
3. k-means聚类
k-means算法属于无监督学习的一种聚类算法,其目的为:在不知数据所属类别及类别数量的前提下,依据数据自身所暗含的特点对数据进行聚类。对于聚类过程中类别数量k的选取,需要一定的先验知识,也可根据“类内间距小,类间间距大“(一种聚类算法的理想情况)为目标进行实现。
3.1. K-Means算法原理
K-means算法模型,一种流行的聚类算法是首先对可能的聚类定义一个代价函数,聚类算法的目标是寻找一种使代价最小的划分。
在这类范例中,聚类任务转化为一个优化问题,目标函数是一个从输入(X,d)和聚类方案 C = (C1,C2,…,Ck)映射到正实数(即损失值)的函数。
给定这样一个目标函数,我们将其表示为 G,对于给定的一个输入(X,d),聚类算法的目标被定义为寻找一种聚类 C 使 G((X,d),C)最小。
- 首先,我们选择一些类/组来使用并随机地初始化它们各自的中心点。要想知道要使用的类的数量,最好快速地查看一下数据,并尝试识别任何不同的分组。中心点是与每个数据点向量相同长度的向量,在下面的图形中是“X”;
- 每个数据点通过计算点和每个组中心之间的距离进行分类,然后将这个点分类为最接近它的组;
- 基于这些分类点,我们通过取组中所有向量的均值来重新计算组中心;
- 对一组迭代重复这些步骤。你还可以选择随机初始化组中心几次,然后选择那些看起来对它提供了最好结果的来运行。
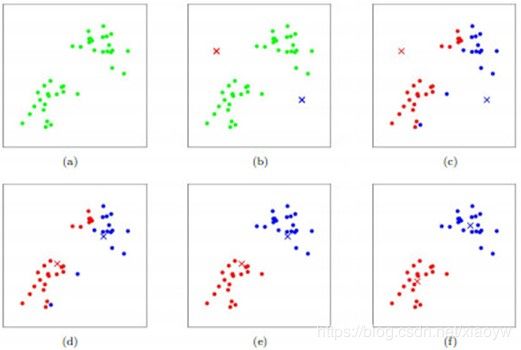
如图所示,数据样本用圆点表示,每个簇的中心点用叉叉表示。[1]
3.1.1. 聚类中心个数K
聚类中心的个数K需要事先给定,但在实际中这个 K 值的选定是非常难以估计的,很多时候,事先并不知道给定的数据集应该分成多少个类别才最合适。这个过程会是一个漫长的调试过程,我们通过设置一个[k, k+n]范围的K类值,然后逐个观察聚类结果,最终决定该使用什么K值对当前数据集是最佳的
在实际情况中,往往是对特定的数据集有对应一个最佳的K值,而换一个数据集,可能原来的K值效果就会下降。但是同一个项目中的一类数据,总体上来说,通过一个抽样小数据集确定一个最佳K值后,对之后的所有K值都能获得较好的效果
3.1.2. 初始聚类中心(质心)的选择
刚开始时是原始数据,杂乱无章,没有label,看起来都一样,都是绿色的
Kmeans需要人为地确定初始聚类中心,不同的初始聚类中心可能导致完全不同的聚类结果。在实际使用中我们往往不知道我们的待聚类样本中哪些是我们关注的label,人工事先指定质心基本上是不现实的,在大多数情况下我们采取随机产生聚类质心这种策略
假设数据集可以分为两类,令K = 2,随机在坐标上选两个点,作为两个类的中心点(聚类质心)
3.1.3. 确定了本轮迭代的质心后,将余下的样本点根据距离度量标准进行归类
这一步也非常直观,计算样本点和所有质心的“距离”,选取“距离”最小(argmin)的那个质心作为该样本所属的类别。
这里要注意的是,特征空间中两个实例点的距离是两个实例点相似程度的反映,高维向量空间点的距离求解,可以泛化为Lp距离公式,它在不同的阶次数中分为不同的形式
K-Means聚类算法的优势在于它的速度非常快,因为我们所做的只是计算点和群中心之间的距离;它有一个线性复杂度O(n)。
另一方面,K-Means也有几个缺点。首先,你必须选择有多少组/类。这并不是不重要的事,理想情况下,我们希望它能帮我们解决这些问题,因为它的关键在于从数据中获得一些启示。K-Means也从随机选择的聚类中心开始,因此在不同的算法运行中可能产生不同的聚类结果。因此,结果可能是不可重复的,并且缺乏一致性。其他聚类方法更加一致。
3.2. SKlearn K-Means应用代码
与第1章节相同代码,省略。
把数据放到三维空间中,包括时序、位移、力三个特征数据。
if __name__ == '__main__':
X = init_data()
est = KMeans(n_clusters=20).fit(X)
labels = est.labels_
colors_ = ['b','r','y','g','m','c','k','pink','orange']
index = [int(tmp) for tmp in labels]
col = []
k = 0
for i in index:
k = i
if k>=len(colors_):
k = i%len(colors_)
col.append(colors_[k])
fig = plt.figure()
plt.clf()
ax = Axes3D(fig, rect=[0, 0, .95, 1], elev=48, azim=134)
plt.cla()
ax.scatter(X[:, 2], X[:, 0], X[:, 1], c=col)
ax.w_xaxis.set_ticklabels([])
ax.w_yaxis.set_ticklabels([])
ax.w_zaxis.set_ticklabels([])
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('z')
plt.show()
效果不理想,请看下图。
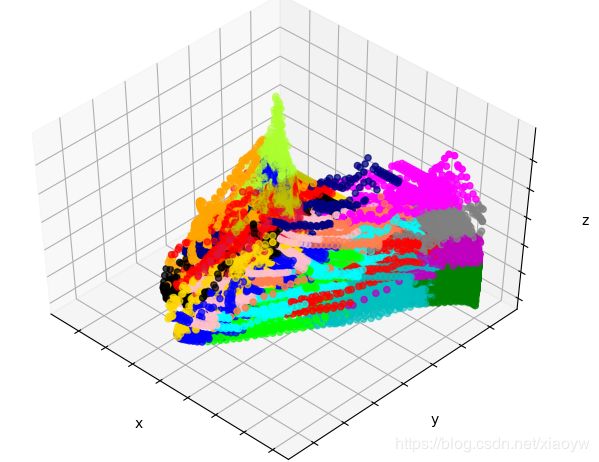
注:绘制3D图形,出现环境上的问题“ImportError: No module named mpl_toolkits”
找到mpl_toolkits文件夹,在下边建一个文件:_init_.py
try:
import(‘pkg_resources’).declare_namespace(name)
except ImportError:
pass # must not have setuptools
由于本人的水平有限,开始试验了K-Means、Birch等算法,都是很不理想,接着,重点研究、试验DBSCAN算法,但是,比较担心数据密度不够,将会影响分析效果。最后总结如下,需要进一步验证。
首先,异常数据、离群点都是小样本,数据密度很低。这样,在接手别人数据集时,可以通过DBSCAN聚类打一次标签试试,和原数据标签有多大差异。
按DBSCAN算法,输入1000条样本数据,其中包含147850采集数据点,根据聚类结果标记的离群低密度点,原始数据是这样的,与规范的分类识别差距很大。真的怀疑人工标识故障分类了。
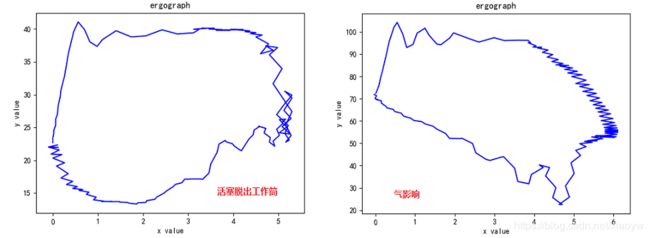
欢迎读者反馈交流。
参考:
[1]. 《各类聚类(clustering)算法初探》 博客园/长路 Andrew.Hann 2018年1月
[2]. 《异常点检测算法小结》 博客园/刘建平Pinard 2018年7月
[3]. 《DBSCAN聚类算法——机器学习(理论+图解+python代码)》 CSDN博客 风弦鹤 2018年7月
[4]. 《Python实现聚类算法(6种算法)》 CSDN博客 周小董 2019年3月
[5]. 《使用Python Matplotlib绘图并输出图像到文件中的实践》 CSDN博客 肖永威 2018年4月
[6]. Visualizing DBSCAN Clustering