「自然语言处理(NLP)」ACL && 阿里(舆论、立场检测)&& 耶鲁(电子邮件主题生成)
来源:AINLPer微信公众号
编辑: ShuYini
校稿: ShuYini
时间: 2019-8-24
引言
本次为大家推荐两篇文章,第一篇是阿里巴巴团队提出的用于谣言检测和立场分类的多任务学习方法;第二篇耶鲁大学主要研究了电子邮件主题的生成,提出了一种新的电子邮件主题生成模型。
PS:欢迎关注AINLPer微信公众号,论文解读会每日更新,等你来看。
First Blood
TILE: Rumor Detection By Exploiting User Credibility Information, Attention and Multi-task Learning
Contributor : 阿里巴巴(美国团队)
Paper: https://www.aclweb.org/anthology/P19-1113
Code: None
文章摘要
提出一种新的多任务学习方法用于谣言检测和立场分类任务。该神经网络模型具有一个共享层和两个任务特定层。将用户可信度信息纳入谣言检测层,并将注意机制应用于谣言检测过程中。注意力信息不仅包括谣言检测层的隐藏状态,还包括立场检测层的隐藏状态。在两个数据集上的实验表明,本文提出的模型优于目前最先进的谣言检测方法
模型方法介绍
多任务网络结构
下图为我们提出的多任务学习高层网络结构。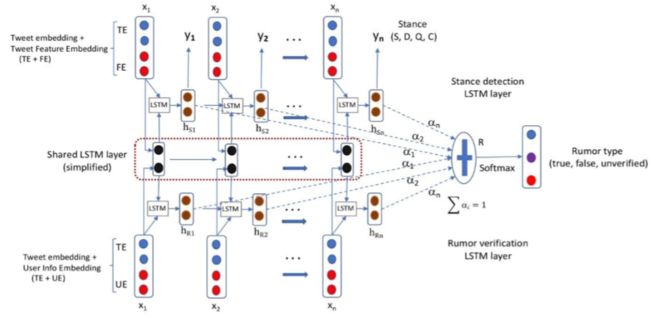 中间层是一个共享层,由两个任务共享。这一层是通过共享参数提取这两个任务之间的公共模式。上层用于立场检测,下层用于谣言的特定特征。在这个图中,我们假设这些帖子是推文,并将在下面的小节中使用推文作为示例。两个任务特定层的输入是claim(谣言、线程)分支。以下图2中的谣言传播路径为例,
中间层是一个共享层,由两个任务共享。这一层是通过共享参数提取这两个任务之间的公共模式。上层用于立场检测,下层用于谣言的特定特征。在这个图中,我们假设这些帖子是推文,并将在下面的小节中使用推文作为示例。两个任务特定层的输入是claim(谣言、线程)分支。以下图2中的谣言传播路径为例,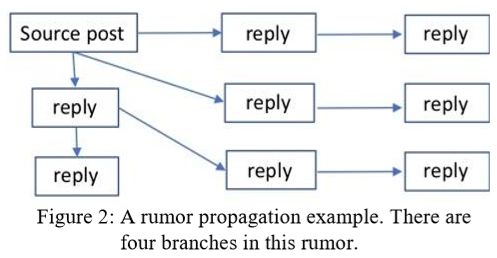 这个谣言传播路径有四个分支,每个分支都有一个输入序列 [ x 1 , x 2 , … , x n ] [x_1, x_2,…,x_n] [x1,x2,…,xn],输入到两个任务特定的层中。 x 1 x_1 x1是源推文), x n x_n xn是分支中的最后一条推文。
这个谣言传播路径有四个分支,每个分支都有一个输入序列 [ x 1 , x 2 , … , x n ] [x_1, x_2,…,x_n] [x1,x2,…,xn],输入到两个任务特定的层中。 x 1 x_1 x1是源推文), x n x_n xn是分支中的最后一条推文。
立场(SDQC)检测层
如图1所示,立场检测层使用标准的LSTM模型。输入 x i x_i xi是两种类型的特性的串联:推文嵌入(TE)和推文特性嵌入(FE)。其中TE是通过一个基于注意力的LSTM网络生成。FE是使用(Kochkina et al., 2017)中描述的相同的特性列表生成的。
谣言验证层
图1的低层显示了谣言验证流程的结构。在每个步骤中,输入 x i x_i xi由两个向量表示:推文嵌入(TE)和用户信息嵌入(UE)。UE代表用户可信度信息。
用户置信度信息: 我们从用户档案中获取可信度信息。我们使用(Liu et al., 2015)中描述的特性来获得这些信息。一些特征示例包括:验证帐户、配置文件是否包含位置、配置文件是否具有描述等 。将这些信息进行处理并连接在一起作为UE嵌入,然后UE与TE连接作为输入。
基于注意力的LSTM: 我们使用一个基于注意力的LSTM来对重要的推文给予更多的关注。对每一步i,来自上层的隐藏状态和来自下层的隐藏状态实际上被连接在一起并一起处理。
实验结果
在RumorEval数据集上,谣言验证结果对比 在PHEME数据集上,谣言验证结果对比
在PHEME数据集上,谣言验证结果对比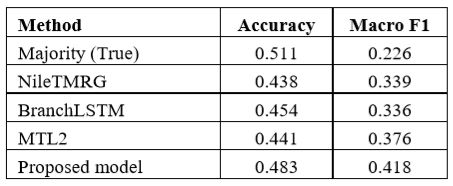
Double Kill
TILE: This Email Could Save Your Life: Introducing the Task of Email Subject Line Generation.
Contributor : Yale University(耶鲁大学)
**Paper:**https://www.aclweb.org/anthology/P19-1043
**Code:**None
文章摘要
提出并研究了电子邮件主题行生成任务:从电子邮件正文中自动生成电子邮件主题行。我们为这个任务创建了第一个数据集,并发现电子邮件主题行生成非常抽象,这与新闻标题生成或新闻单个文档摘要不同。然后,我们开发了一种新的深度学习方法,并将其与几种基线以及最新的最先进的文本摘要系统进行了比较。我们还研究了几种基于人类判断相关性的自动评价指标的有效性,并提出了一种新的自动评价指标。
本文三大看点
1、介绍了电子邮件主题行生成(SLG)的任务,并建立了一个基准数据集AESLC.1
2、研究了SLG自动度量的可能性,并研究了它们与人类判断的相关性。我们还介绍了一种新的电子邮件主题质量评估指标(ESQE)。
3、提出了一种新的电子邮件主题生成模型。我们的自动评估和人工评估表明,该模型性能优于竞争基线,并接近于人类水平的质量。
标注后的Enron主题行语料库
为了准备我们的电子邮件主题数据集,我们使用Enron数据集(Klimt and Yang, 2004),它是Enron公司员工的电子邮件信息的集合。 如表2所示,电子邮件主题通常比在以前的新闻数据集中生成的摘要短得多。虽然与新闻标题行生成类似(Rushetal.,2015),电子邮件主题生成也更具挑战性,因为它处理不同类型的电子邮件主题,而新闻文章的第一句话往往已经是一个很好的标题和总结。
如表2所示,电子邮件主题通常比在以前的新闻数据集中生成的摘要短得多。虽然与新闻标题行生成类似(Rushetal.,2015),电子邮件主题生成也更具挑战性,因为它处理不同类型的电子邮件主题,而新闻文章的第一句话往往已经是一个很好的标题和总结。
本文模型介绍
模型结构下图1所示。 基于新闻摘要的最新进展(Chen and Bansal,2018),我们的模型分为两个阶段生成电子邮件主题:(1)提取器选择包含显著信息的多个句子来编写主题。(2)摘要器在保留关键信息的同时,将选定的多个句子改写成简洁的主题行。
基于新闻摘要的最新进展(Chen and Bansal,2018),我们的模型分为两个阶段生成电子邮件主题:(1)提取器选择包含显著信息的多个句子来编写主题。(2)摘要器在保留关键信息的同时,将选定的多个句子改写成简洁的主题行。
例如在模型结构图中,输入电子邮件正文由四句话组成,提取器从中选择第二句和第三句。摘要器从所选的句子生成电子邮件主题。质量评估人员通过对邮件主体的主题打分来提供奖励。
实验结果
表3a和表3b中分别表示原始主题和Turkers (human annotations)生成主题的自动度量分数对比
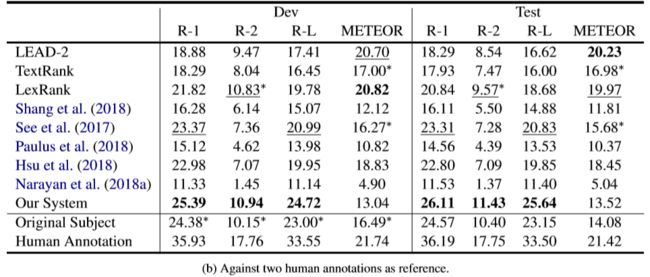 ESQE分数对比
ESQE分数对比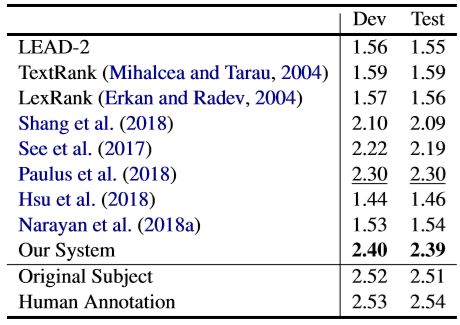 人为评估对比
人为评估对比 人工评估和自动分数度量对比
人工评估和自动分数度量对比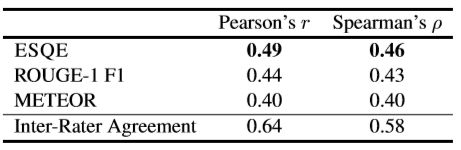
ACED
Attention
更多自然语言处理相关知识,还请关注AINLPer公众号,极品干货即刻送达。